







最近 AI 数字人异常火爆,多款开源方案,效果炸裂,直逼付费方案!
也许你也发现了,市面上的数字人方案,琳琅满目。不过,大致可以分为:卡通数字人和真人数字人。
本篇主要讲真人数字人,真人数字人又可以进一步细分为:
- 2D 真人:只需一张图片,用姿态/音频等驱动生成对应的视频;
- 2.5D 真人:需要2-3分钟真人视频数据进行学习,最终可以完美还原表情和动作。常常也被称为语音驱动对口型。
- 3D 超写实:需要3D建模、渲染、面部骨骼绑定、动作捕捉等,流程相对复杂。
应该说,和商业应用场景最相关的是2.5D 真人,技术方案有很多,不过大多基于wav2lip的方案。
今日分享,给大家带来一款实时的2.5D数字人开源项目-UltraLight Digital Human,轻量高效,效果惊艳。
1. UltraLight Digital Human 简介
这个项目的技术方案和wav2lip基本一致,本质上是一个 GAN 模型。
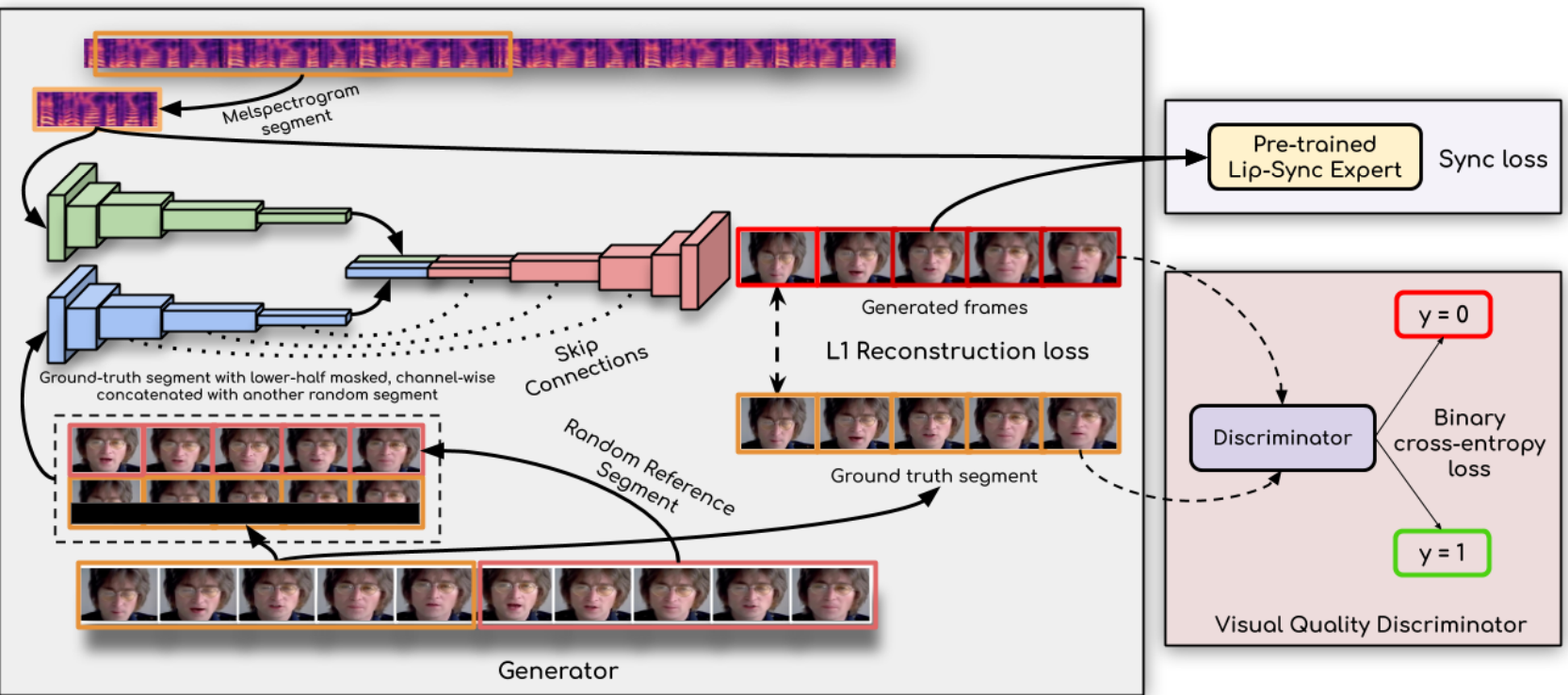
GAN 中有两个关键组成:生成器和判别器:
- 生成器用于生成逼真的图像;
- 生成器用来识别生成的假图像;
通常,二者交叉迭代,在相互博弈的过程中不断优化,从而生成器致力于生成欺骗生成器的图像,而生成器则努力识别出生成器的假图像。
基于 GAN 的基本认识,下面我们来实操 UltraLight Digital Human,就更容易理解了。
2. UltraLight Digital Human 实操
首先,下载项目源码:
git clone https://github.com/anliyuan/Ultralight-Digital-Human
项目文档中有具体实操步骤,这里我们梳理成三部分,分别介绍。
2.1 数据准备
准备一段3到5分钟的视频,确保视频中每一帧都有完整的人脸,声音清晰,然后执行如下命令:
cd data_utils
python process.py YOUR_VIDEO_PATH --asr hubert
这一步共干了四件事:
# 用 ffmpeg 提取视频中的音频数据
extract_audio(opt.path, wav_path)
# 使用wenet或者hubert提取音频特征
get_audio_feature(wav_path, asr_mode)
# 用 opencv 提取视频中的所有帧图像
extract_images(opt.path, asr_mode)
# 对所有帧图像进行人脸和关键点检测(110个)
get_landmark(opt.path, landmarks_dir)
2.2 模型训练
模型训练包括两个部分:
2.2.1 判别器训练
和 wav2lip一样,本项目也是采用的 syncnet 模型。
cd ..
python syncnet.py --save_dir ./syncnet_ckpt/ --dataset_dir ./data_dir/ --asr hubert
那么,syncnet 训练过程中,都干了啥?
- 读取原始图像和关键点数据,以及音频特征
- 每次模型训练时:根据关键点crop出
嘴唇部位图像;提取对应帧的音频特征。 - 将人脸图像和音频特征进行配对,输入 SyncNet,对得到的embedding进行损失计算。
syncnet 训练的目的又是啥?
为了让同一帧的人脸图像和音频特征尽可能逼近,从而迫使生成器生成和音频匹配的人脸图像。
syncnet 显存占用情况如何?

不到 2G 就能跑,实在不行,CPU 也能顶上。
2.2.2 生成器训练
数字人模型最主要的就是生成器,用来生成图像啊。
整体架构是 Unet,包括图像编码器和音频编码器,两路输出拼接后给解码器,生成图像。
从 2.2.1 中找到 loss 最小的判别器模型加载进来,开始生成器的训练:
cd ..
python train.py --dataset_dir ./data_dir/ --save_dir ./checkpoint/ --asr hubert --use_syncnet --syncnet_checkpoint syncnet_ckpt
生成模型显存占用:

至此,整个模型训练就完成了!
训练耗时如何?
对于一个 1min40s 的视频,采用默认参数,实测耗时如下:
- 数据准备:7min(关键点提取耗时严重);
- 模型训练:判别器 5min + 生成器 70min
2.2 模型推理
首先,需要准备一条测试音频文件,提取测试音频的特征(项目提供了两种音频特征提取方法,下面以 hubert 为例):
python data_utils/hubert.py --wav your_test_audio.wav # when using hubert
然后,为每一帧音频生成一张图像,每张图像 crop 出嘴唇部位进行合成,再把合成嘴唇部位贴回到原图中。
所以,最终生成视频除了人脸区域不同之外,其它区域和原图是一样的。
python inference.py --asr hubert --dataset ./your_data_dir/ --audio_feat your_test_audio_hu.npy --save_path xxx.mp4 --checkpoint your_trained_ckpt.pth
最后,把生成的视频和音频进行合并:
/usr/bin/ffmpeg -i demo/result.mp4 -i demo/gen_audio.wav -c:v libx264 -c:a aac result_wav.mp4
最终**视频共 18s,实测推理耗时 18s 搞定!**模型训练成功后,同一个角色可以重复使用!
3 一键整合包
为方便大家实操,我把上述流程进行了整合和封装(包括模型权重和测试用例):
你只需傻瓜式操作:
step 0: 安装依赖:
conda create -n udh python=3.10
conda activate udh
pip install -r requirements.txt
step 1: 数据准备:
python data_prepare.py
step 2:模型训练:
python train.py
step 3:模型推理:
python inference.py
先快速跑通测试用例,然后再看看:还有哪些环节可以改进吧!
整合包已上传云盘,有需要的朋友,公众号后台回复udh自取!
写在最后
本文带大家在本地实操了开源的2.5D数字人项目。
如果对你有帮助,欢迎点赞收藏备用。
市场上类似项目还有很多,不知大家使用体验如何,欢迎评论区留言!
后续打算开一个专栏,梳理一下已有的数字人方案,结合语音克隆,打造一款可商用的解决方案,感兴趣的盆友随时交流!
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 2139
2139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









