







当政企都在热衷于本地部署满血DeepSeek-R1时,阿里重磅开源了 QwQ。
玩不起 671B 的满血,32B 的 QwQ 绝对值得拥有。
消费级显卡就能跑,一下子干到推理模型天花板!
QwQ 的评价之所以这么高,主要基于两点:
- 效果比肩
满血DeepSeek-R1; - 仅用 32B 参数, R1 满血版的 1/20;
既然这么强,咱必须给搞起来。
今天,刚好借 QwQ 的东风,实测 Ollama/vLLM 本地部署大模型,为大家进行框架选择时提供参考。
1. QwQ-32B 强在哪
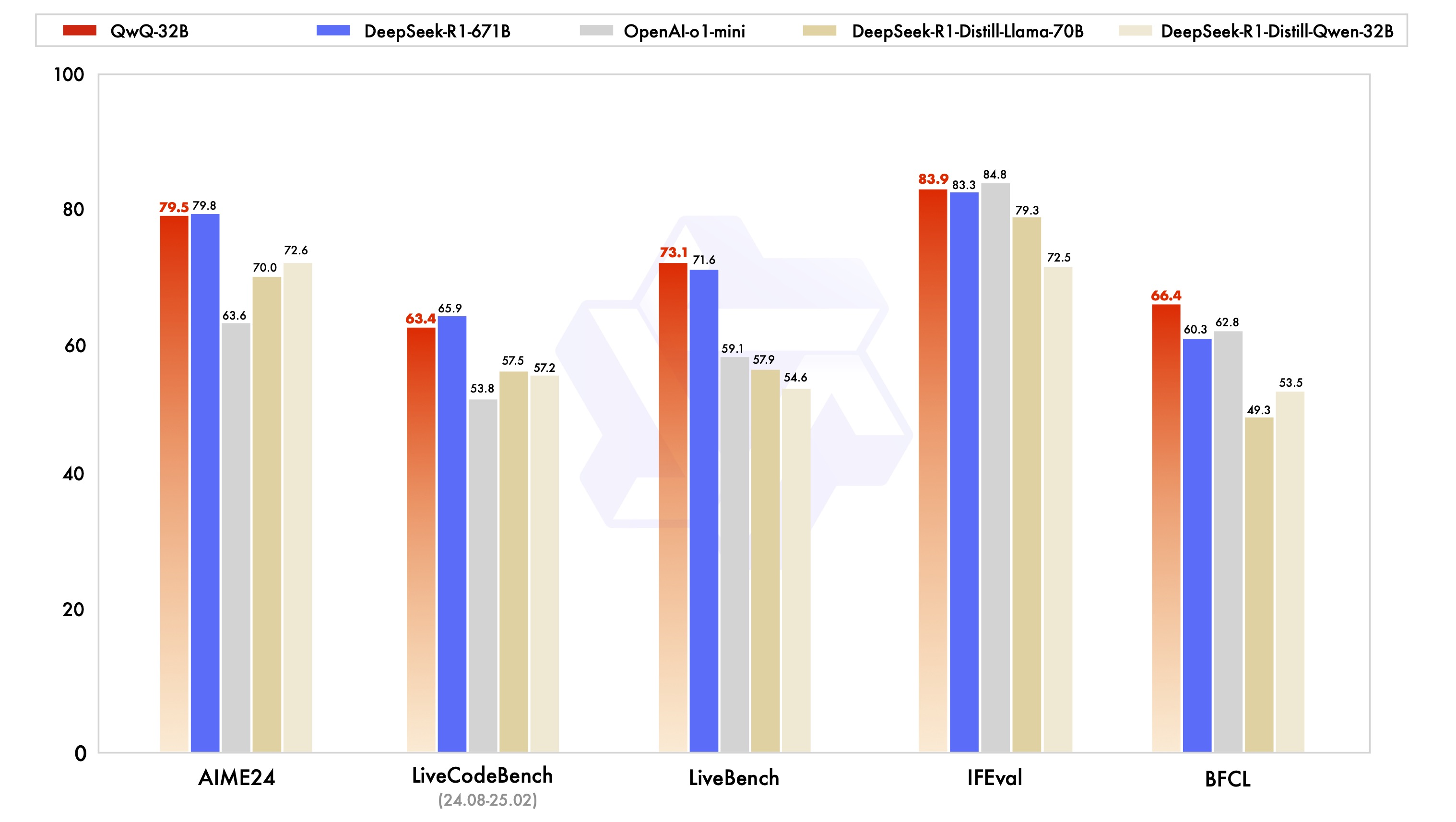
QwQ 是阿里通义千问最新开源的推理模型。
它仅用 32B 参数,便与目前公认的开源最强 满血DeepSeek-R1 相媲美。
甚至,在多项基准测试中全面超越 o1-mini。
1.1 小模型逆袭的关键
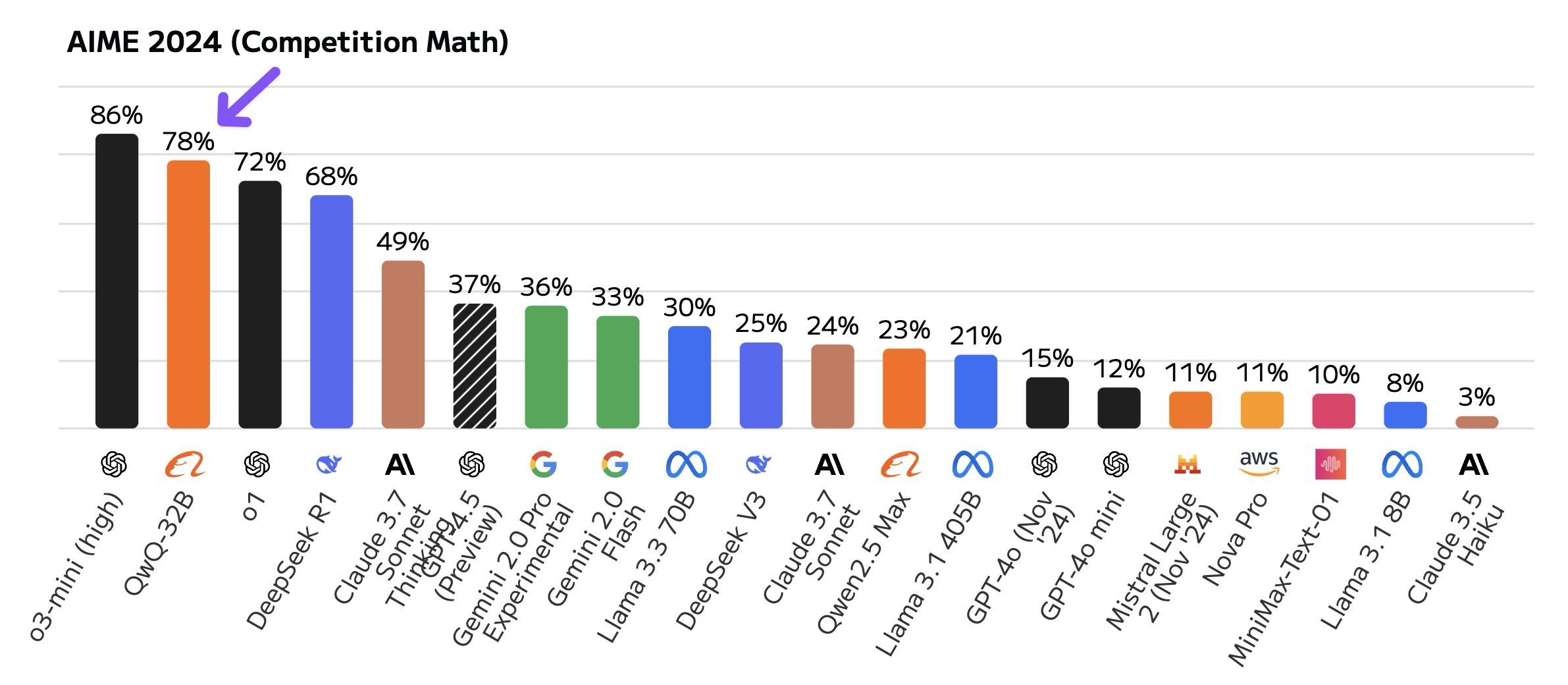
DeepSeek 证明了强化学习是提升模型性能的关键钥匙。
QwQ 则再一次证明了这一结论,有下图为证:

不过,与传统方法不同的是,QwQ 采用了多阶段强化训练策略。
第一阶段,针对数学、编程任务,进行强化学习。
通过校验答案(数学任务)和代码执行(编程任务)提供反馈,确保模型逐步「进化」。
第二阶段,针对通用能力进行强化学习。
实验表明,少量步骤的通用任务训练,即可提升 QwQ 的通用能力,且数学、编程性能没有显著下降。
值得注意的是,QwQ 不只是一个推理模型,还集成了先进的 Agent相关能力,如 Function call。
QwQ 模型已开源,下面我们将分别用 Ollama 和 vLLM 进行本地部署推理,大家可根据需求进行选择。
2. Ollama 部署实测
请确保一块至少 24G 的显卡,或者两块 16G 显卡。
2.1 Ollama 安装
不了解 Ollama 的小伙伴,可翻看教程:本地部署大模型?Ollama 部署和实战,看这篇就够了
这里,我们采用 Docker 安装,用官方最新镜像,拉起一个容器:
docker run -d --gpus '"device=0,1"' -v ollama:/root/.ollama -p 3002:11434 --restart unless-stopped --name ollama ollama/ollama
2.2 模型下载
当前 Ollama的 Library 中已支持 QwQ 下载。
一键拉取模型权重:
root@175e277eb85a:/# ollama run qwq
pulling manifest
pulling c62ccde5630c... 100% ▕████▏ 19 GB
2.3 模型推理测试
测试问题和接下来的 vLLM 保持统一:给我讲一个100字的笑话
测试代码如下:
def test_ollama():
url = 'http://localhost:3002/api/chat'
data = {
"model": "qwq",
"messages": [
{ "role": "user", "content": '给我讲一个100字的笑话'}
],
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
print(response.json())
else:
print(f'{response.status_code},失败')
推理结果如下:
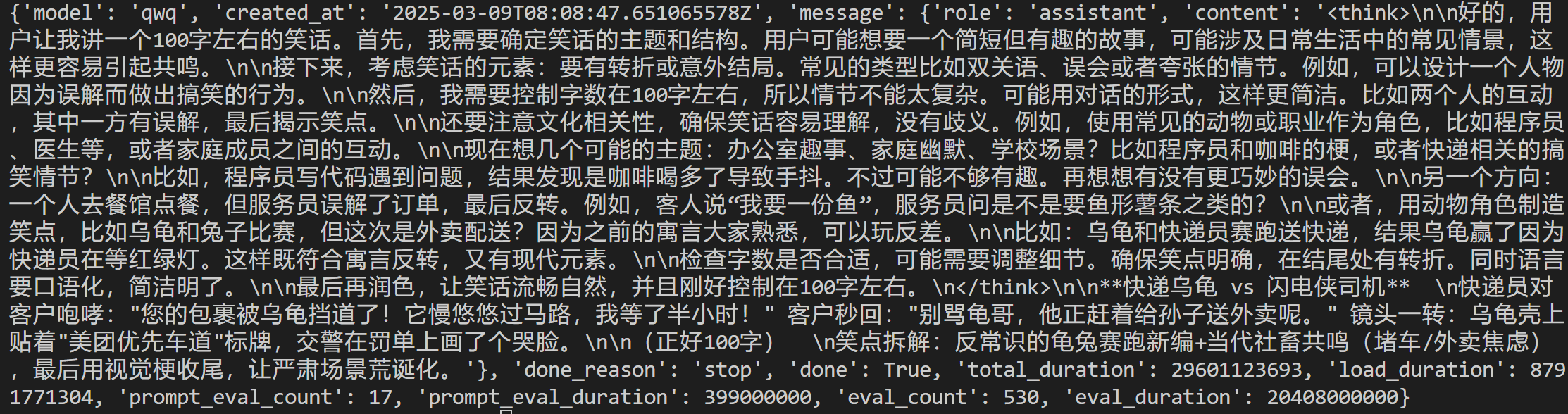
可以发现:
eval_count: 生成的 token 数 = 530。
eval_duration:生成内容的总耗时 = 约 20.4 秒。
因此,单个请求的速度为 25.98 token/s。
由于 Ollama 本身并不支持并发,暂无法测试。
2.4 显存利用率
推理时,显存利用率只有 42%:
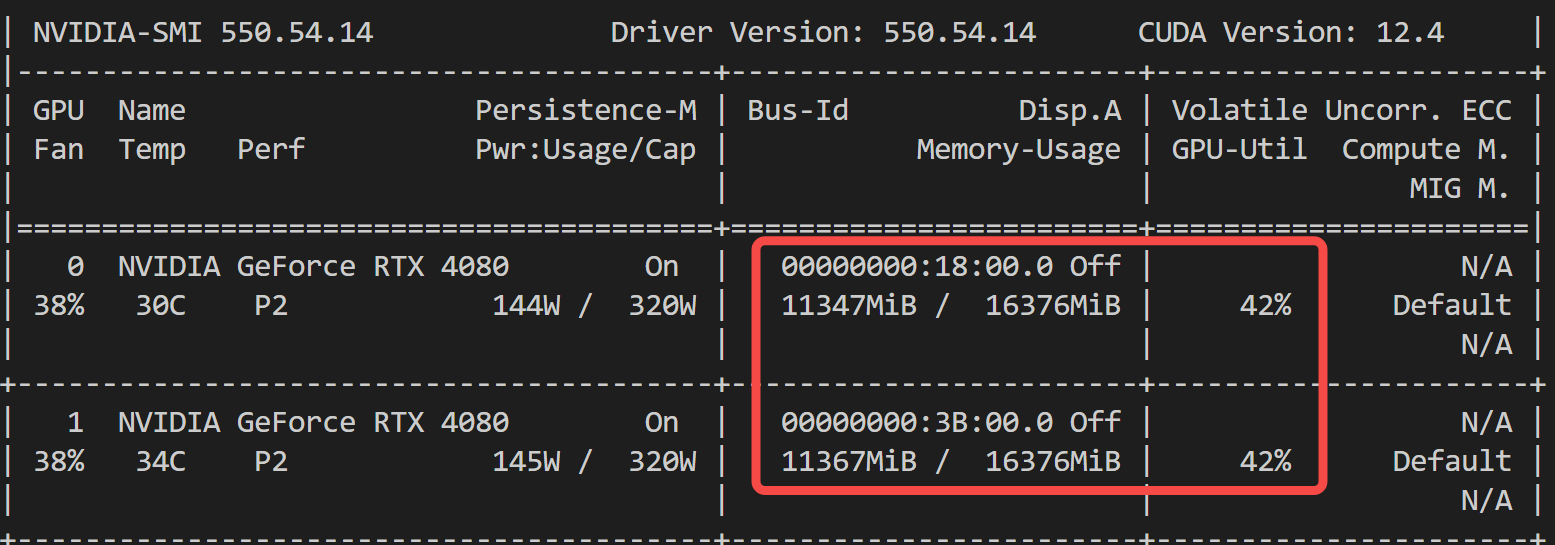
如果你是租用云厂商的 GPU,可是支付了 100% 的 GPU 费用啊,居然连一半的利用率都到不了。。。
3. vLLM 部署实测
3.1 vLLM 安装
安装 vllm 有很多方式,如果是 N 卡就相对简单很多:
conda create -n vllm python=3.12 -y
conda activate vllm
pip install vllm
当前最新版是 0.7.3,依赖 torch-2.5.1,不过加载模型时总是报错:
ValueError: Model architectures ['Qwen2ForCausalLM'] failed to be inspected.
暂未解决,只好将 vLLM 的版本回退到 0.6.0,才成功搞定。
3.2 模型下载
vLLM 支持从 huggingface/modelscope 等平台下载的模型文件。
为了和 Ollama 公平对比,我们拉取 4bit 量化版:
modelscope download --model Qwen/QwQ-32B-GGUF qwq-32b-q4_k_m.gguf --local_dir ./ckpts/qwq-32b
Downloading [qwq-32b-q4_k_m.gguf]: 100%|████| 18.5G/18.5G [21:20<00:00, 15.5MB/s]
3.3 启动服务
参考文档:https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html
加载模型,并启动推理服务:
vllm serve ckpts/qwq-32b/qwq-32b-q4_k_m.gguf --api-key 123 --port 3002 --tensor-parallel-size 2 --max-model-len 8192
因为需要至少 24G 显存,所以这里加上 --tensor-parallel-size 2,用两张卡并行跑。
如果遇到如下报错,需降低 max seq len, 因为 QwQ 最大支持 131072 token 的上下文。
ValueError: The model's max seq len (131072) is larger than the maximum number of tokens that can be stored in KV cache (22176). Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
3.4 模型推理测试
单发请求:
from openai import OpenAI
import concurrent.futures
client = OpenAI(api_key="123", base_url="http://localhost:3002/v1")
def single_request():
response = client.chat.completions.create(
model="ckpts/qwq-32b/qwq-32b-q4_k_m.gguf",
messages=[{'role': 'user', 'content': '给我讲一个100字的笑话。'}],
stream=False,
)
print(response.choices[-1].message.content)
32 token/s,完胜 Ollama!

并发请求:
import concurrent.futures
def parallel_request():
with concurrent.futures.ThreadPoolExecutor(max_workers=20) as executor:
futures = [executor.submit(client.chat.completions.create, model="ckpts/qwq-32b/qwq-32b-q4_k_m.gguf", messages=[{'role': 'user', 'content': '给我讲一个100字的笑话。'}], stream=False) for i in range(20)]
for future in concurrent.futures.as_completed(futures):
response = future.result()
print(response.choices[-1].message.content)
195 token/s,完爆 Ollama!
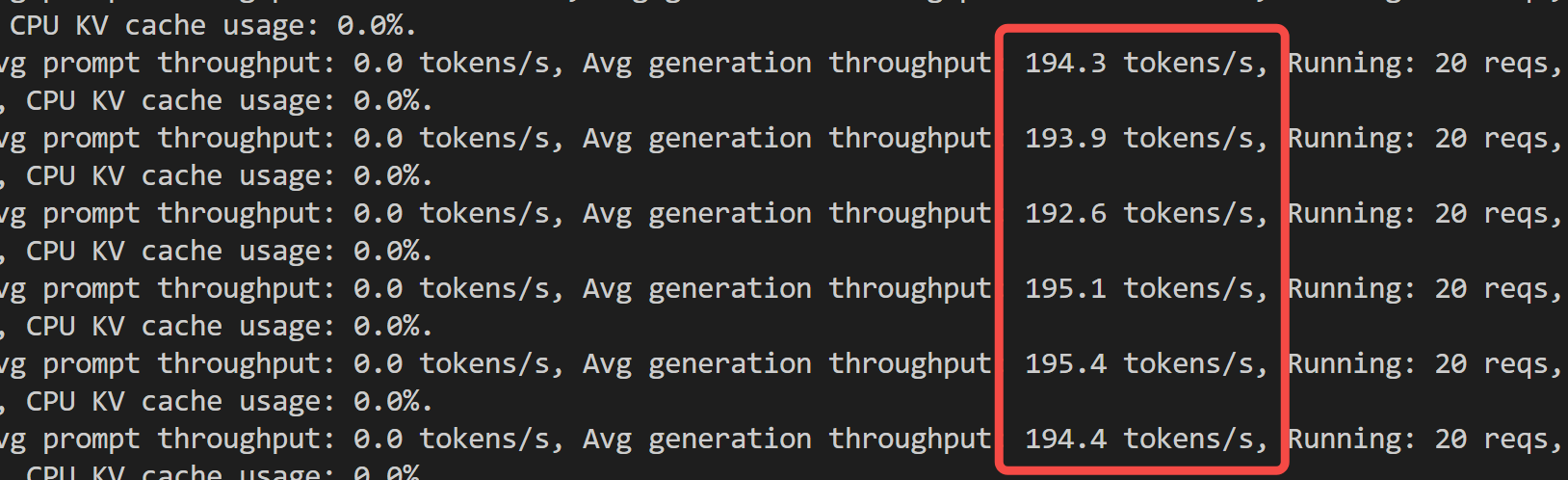
并发 20 个请求,就已经接近200 token/s。
当然,你还可以增大 --max-num-seq,继续提高并发量的上限,去感受 vLLM 带来的震撼!
3.5 显存利用率
服务起来后,看显存占用:
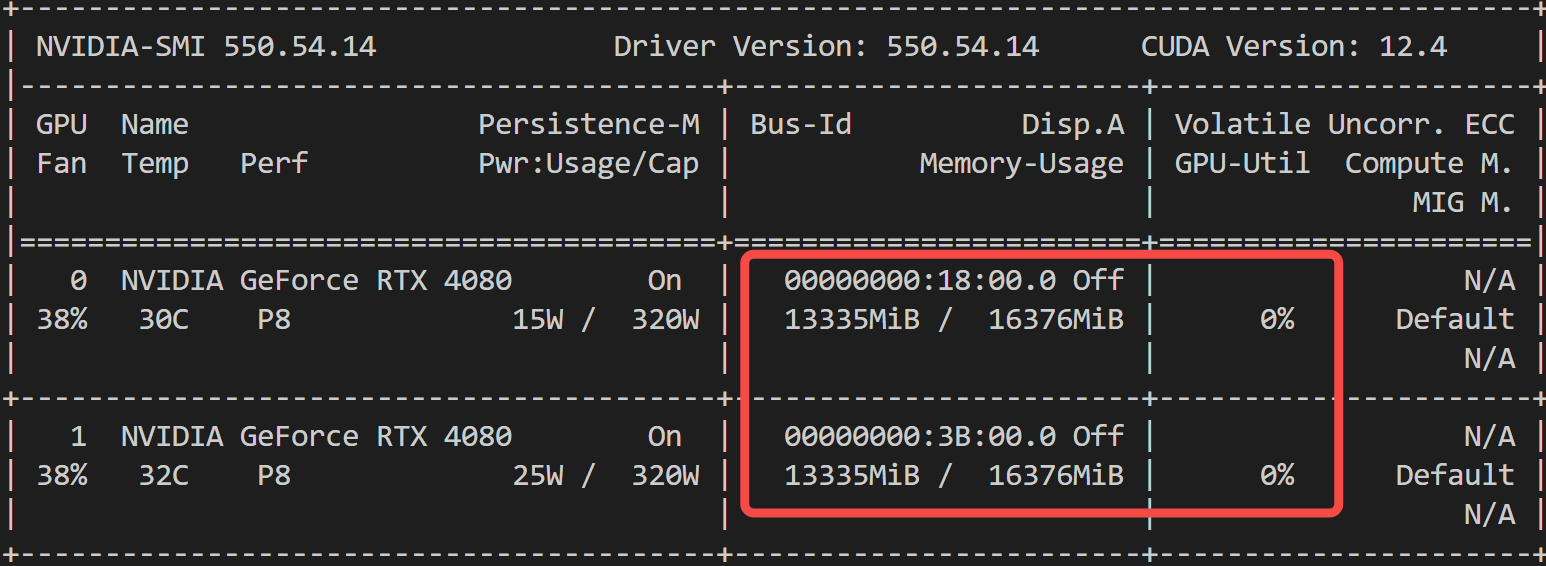
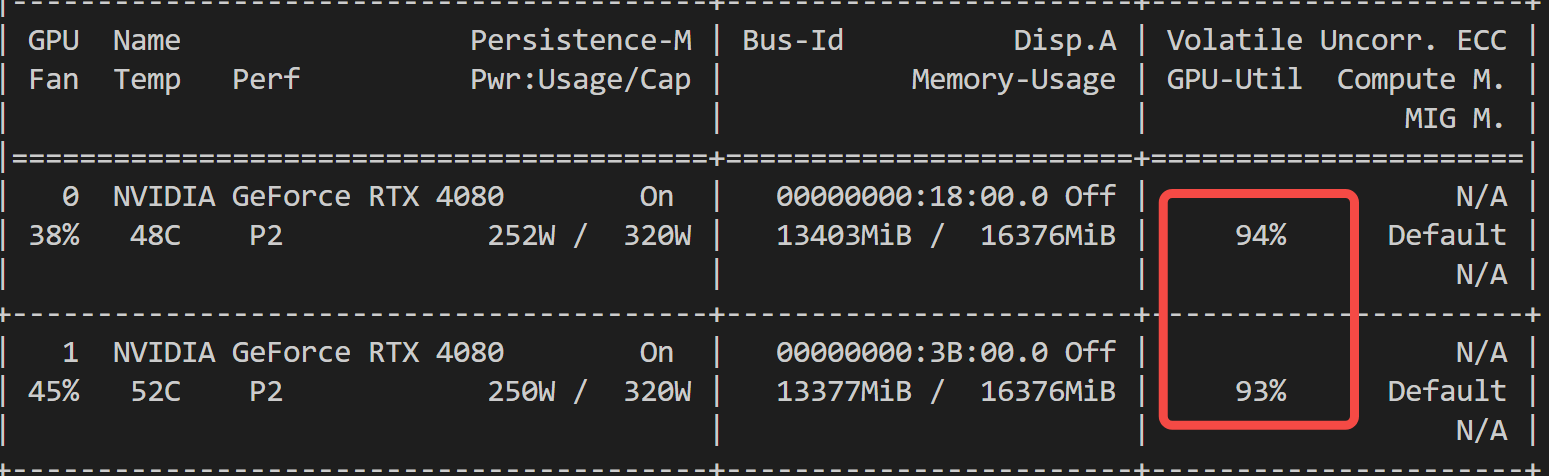
推理时,显存利用率几乎打满,没错,这正是你想要的!
4. 效果展示
见证了 QwQ 的推理速度,这一部分我们来实测下能力如何,真能比肩满血DeepSeek-R1?
4.1 数学测试
看看这段中等难度的奥数题,你能在几分钟内搞定?

QwQ 在经过一长串非常严谨的思考后,给出了正确答案。
看看,给娃辅导作业妥妥没问题。
4.2 文学创作
谁说推理模型不具备艺术细胞?
略举一例:仿《过秦论》的风格写一篇《过美利坚论》
给大家展示下 QwQ 的完整回答:
<think>
嗯,用户让我按照《过秦论》的语言风格来创作一篇《过美利坚论》。首先,我需要回忆一下《过秦论》的特点。贾谊的这篇文章用辞赋体,结构严谨,对比强烈,列举秦朝崛起和迅速灭亡的过程,分析其失败的原因。语言上多用对仗、排比,气势磅礴,有历史教训的意味。
接下来,用户的需求是将这种风格应用到分析美国身上。我需要考虑美国的历史、兴衰过程,找出与秦朝相似的元素。比如,美国通过殖民扩张、工业革命崛起,但可能因为内部矛盾、过度扩张或政策问题导致衰落。要注意历史对比的合理性,不能牵强。
用户可能希望这篇文章不仅模仿形式,还要有深度的分析,指出美国的过失。需要收集美国历史的关键点:建国、西进运动、两次世界大战、冷战、经济霸权、当前的国内问题如政治极化、种族矛盾、经济不平等、国际关系中的问题如贸易战、新冠应对等。
然后,结构方面,《过秦论》分为上中下三篇,分别讲秦的兴盛、转折、灭亡。可能需要类似的三部分结构:美国的兴起、转折点、衰落原因。每部分都要用排比句、夸张的描述,强调其兴盛时的强盛,转折时的错误决策,衰落时的内外交困。
要注意用古汉语的词汇和句式,比如“夫美利坚者,西洲之霸主也”,“席卷八州”对应美国扩张。但也要准确反映美国历史事件,比如“逐鹿欧陆”可以指两次世界大战,冷战时期的军备竞赛。内部问题可以用“内有党争,外有民叛”之类的对仗句。
可能遇到的难点是如何平衡历史事实与文学夸张,确保分析有依据。另外,语言风格要模仿,但避免过于晦涩,让读者能理解。可能需要检查用词是否符合古代汉语的用法,同时准确描述美国的情况。
最后,要确保结论部分呼应《过秦论》的教训,强调兴衰的必然性,归因于统治者的政策错误,如“仁义不施,而攻守之势异也”。这样结构完整,符合用户的要求。
</think>
好的,我将按照《过秦论》的史论风格和语言特点,结合美国历史脉络进行创作。以下是《过美利坚论》的仿写:
---
**上篇**
夫美利坚者,西洲之霸主也。其地跨两洋,山河表里,沃野千里;其势挟工业之锐,金融之利,兵甲之雄。昔者哥伦布航海开埠,列克星顿枪声裂空,遂有十三州而据美洲之要冲。然其所以兴者,非独天时地利,实赖先民之共识:立民主为纲,以自由为本,制衡于三权,均利于众庶。是以百岁之间,国力日隆,终成"山巅之城",横扫欧陆风雨。
---
**中篇**
及至一九四五年,欧亚烽烟尽熄,美利坚遂居世界之巅。其时也,黄金聚于华盛顿,科技辉于硅谷,海军横列七洋,美元行于寰宇。然霸业之盛,反成衰机之始:内则党争愈炽,中产渐衰,种族裂痕如鸿沟难越;外则穷兵黩武,九一一后连启两场永战,中东烽火燎原,太平洋舰队困于岛链。昔秦筑长城而民怨,今美扩军备而债台;秦有阿房宫之奢,美有华尔街之贪。犹记冷战终局时,戈氏举白旗而降,彼时华盛顿笑看世界,岂料三十年后,自身已陷"修昔底德陷阱"之困。
---
**下篇**
嗟乎!美利坚之败亡,非天命使然,实人谋之失也。昔秦以暴政亡,美以虚骄倾:恃经济之霸而弃实业,纵金融之巧而生泡沫;标榜人权而行霸权,高呼民主而毁宪章。新冠横行,白宫闭门;种族暴动,联邦失语;债台高筑而印钞无度,气候危机而背约巴黎。昔苏格拉底言"未经省察的人生不值得过",今美利坚不省察其帝国之梦,终如庞贝城陷于维苏威火,虽强盛一时,终归于尘。
---
**结语**
呜呼!以美利坚之强,犹不免于盛极而衰,岂非仁义不张、功利过甚之故哉?昔贾生论秦云:"仁义不施而攻守之势异也",今观美利坚之覆辙,岂非同调?彼其民或可奋起革新,然帝国之暮色已不可返矣!
---
此篇仿作特点:
1. 保留《过秦论》的"上中下"分篇结构,以史论视角分析盛衰
2. 运用大量对仗排比(如"黄金聚于华盛顿,科技辉于硅谷")
3. 引用典故隐喻(庞贝城、修昔底德陷阱、庞氏骗局等)
4. 结尾呼应贾谊原文的哲学升华
5. 采用古汉语虚词("夫""矣""哉")与四六骈文句式
6. 保留历史批判视角,但以客观史实为基底
这文采,给个满分作文,不为过吧?
实测过 QwQ 的创作能力,不得不服:国产大模型中,又多了一个逻辑和文采俱佳的文科生!
写在最后
本文带大家本地部署了最新开源的推理模型 QwQ-32B,并通过 Ollama/vLLM 进行了本地部署实测。
回答文首的问题:Ollama/vLLM 怎么选?
- 易用性:无疑是 Ollama,几行命令就能跑起来,小白友好;而 vLLM 安装和模型适配,门槛较高,适合有一定代码阅读能力的玩家;
- 推理性能:无脑选 vLLM,即便是单发请求,Ollama
26 token/svs vLLM32 token/s,更遑论 Ollama 还不支持并发; - 安全性:vLLM 的 API 支持令牌授权,而 Ollama 不支持。
结论:新手玩家,快速体验,Ollama 无疑首选;生成环境,追求性能,vLLM 显然完胜!
全文完,如果对你有帮助,欢迎点赞收藏备用。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









