







最近两个月,小智 AI 异常火热。
前不久,分享了自建服务端的初步尝试:
成本不到50的AI对话机器人,如何自建服务端?自定义角色+语音克隆,个人隐私不外传
单篇文章收到 322 位朋友的关注,足见话题炽热。
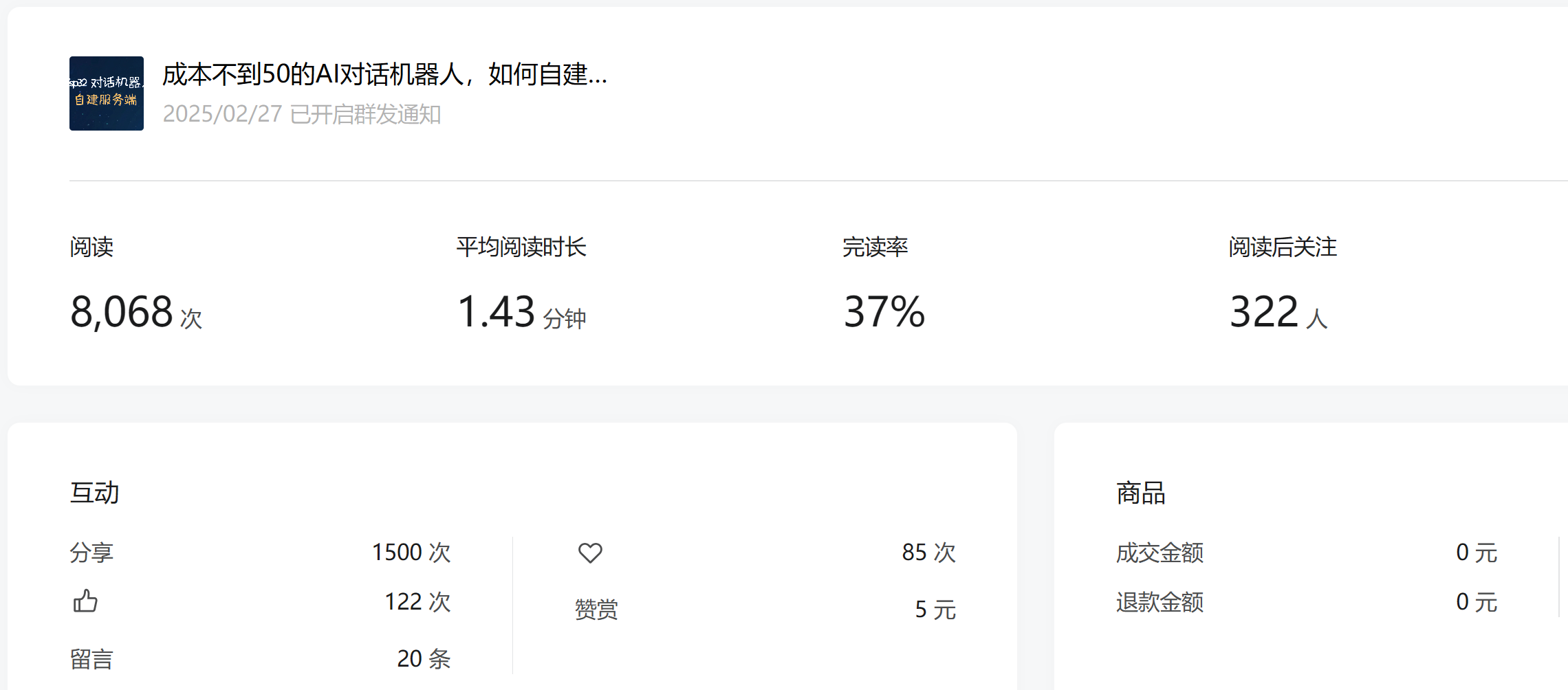
文章发布后,后台收到了很多朋友咨询,一一回复实在精力有限。
本篇开始,将陆续分享系列文章,统一回答大家最关心的问题。
为方便大家理解整体交互逻辑,当时手绘了下面的架构图:
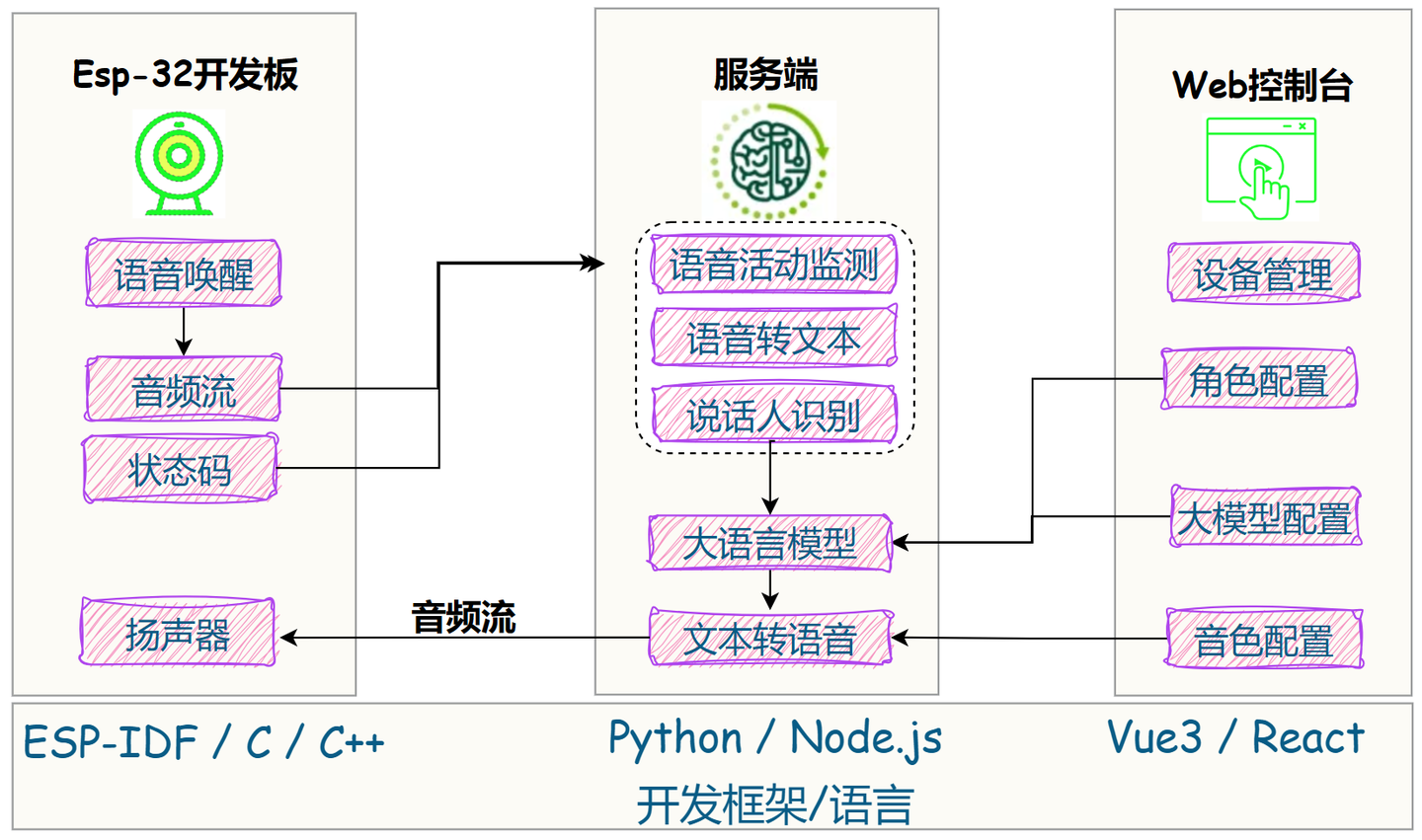
从上图可以发现,服务端的延时,主要有三个方面构成:
- 语音转文本 ASR:流式输入
- 大语言模型 LLM:流式输出
- 文本转语音 TTS:流式输出
测试数据显示,小智的平均语音响应延迟低于 800ms,这是怎么做到的?
本篇,先来拆解 ASR 部分,为各位技术选型提供参考。
1. 技术方案选型
ASR 的技术方案,无外乎:
- 接入外部 API
- 本地部署模型
- GPU 模型推理
- CPU 模型推理
1.1 接入外部 API
这里主要测试了阿里云的 ASR 服务,按使用量付费:
- sensevoice-v1: 2.52元/小时
- paraformer-realtime-v2:0.864元/小时
提交作业接口限流机制:
- sensevoice-v1: RPS = 10;
- paraformer-realtime-v2: RPS = 20
RPS = 10,也即每秒并发请求不超过10。
其中 Paraformer 支持实时语音流识别,而 sensevoice 不支持流式,且只支持url输入。
1.2 本地部署模型
这也是小智开源服务端中采取的方案:
- 本地 VAD 模型
- 本地 ASR 模型
- 本地 声纹向量 模型
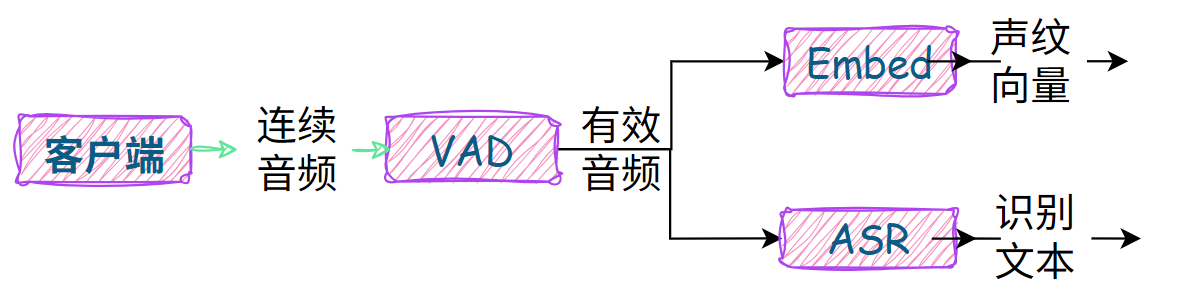
本地部署的优势是完全自主可控,可以根据请求并发量动态扩缩容。
下面我们来实测下各个模型的延时情况。
2. 本地部署实测
模型选择如下:
- 本地 VAD 模型:
speech_fsmn_vad_zh-cn-16k-common-pytorch - 本地 ASR 模型:
SenseVoiceSmall - 本地 声纹向量 模型:
speech_eres2netv2w24s4ep4_sv_zh-cn_16k-common
以一段 4.3s 的音频为例,流式输入,进行测试:
file_path = 'tts_16k.pcm'
with open(file_path, "rb") as f:
pcm_data = f.read()
# 16k采样率,60ms
byte_frame_size = 960
for i in range(0, len(pcm_data), byte_frame_size):
frame = pcm_data[i:i+byte_frame_size]
worker.on_audio_frame(frame)
# 发送几段空白音频,以便识别出空白
for i in range(16):
worker.on_audio_frame(b'\x00'*byte_frame_size)
统计结果如下:
| 任务 | GPU 推理 (秒) | CPU 推理 (秒) |
|---|---|---|
| VAD | 0.005 | 0.007 |
| ASR-SenseVoice | 0.07 | 0.36 |
| Embed | 0.04 | 0.49 |
注:以上测试 GPU 为 Nvidia GTX 4080。
VAD 因为模型参数较小,所以 GPU 推理没有显著优势。
但是 语音识别 和 声纹向量 模型,如果不上 GPU 推理,用户体验就得大打折扣了。
既然要上 GPU 推理,接下来的问题是:
成本和配置!
3. GPU 推理方案
以上三个模型的显存占用并不高,4G 完全足够。
笔者找了几家主流 GPU 云厂商的方案,最低配 11G 显存起步,价格基本得 0.99元/小时。
如果大家有更低成本的方案,欢迎评论区交流!
我这里在趋动云上采用了最低配方案进行了测试:

并发测试示例代码如下:
def run_single_client():
wsapp = websocket.WebSocketApp(
"ws://localhost:8082",
on_message=on_message,
on_error=on_error,
on_close=on_close,
on_open=on_open
)
wsapp.run_forever()
def run_concurrent_test(num_clients=20):
threads = []
for i in range(num_clients):
thread = threading.Thread(
target=run_single_client,
name=f"Client-{i+1}"
)
threads.append(thread)
thread.start()
# time.sleep(0.5) # 每个客户端启动间隔0.5秒
# 等待所有线程完成
for thread in threads:
thread.join()
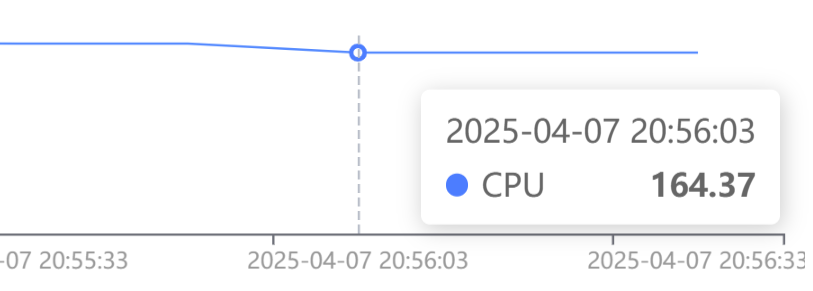
CPU 满载运行:
内存占用:
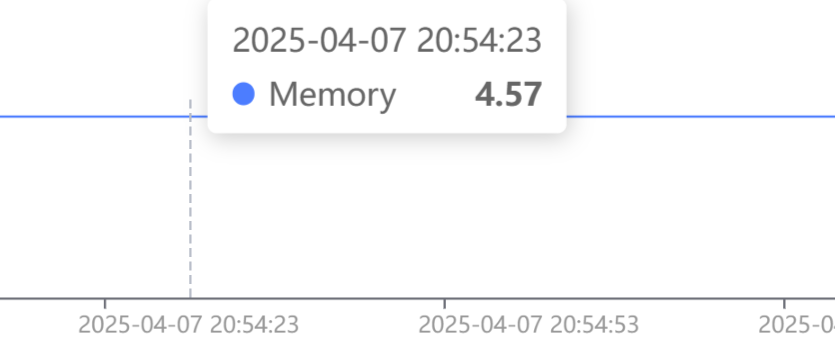
显存占用:
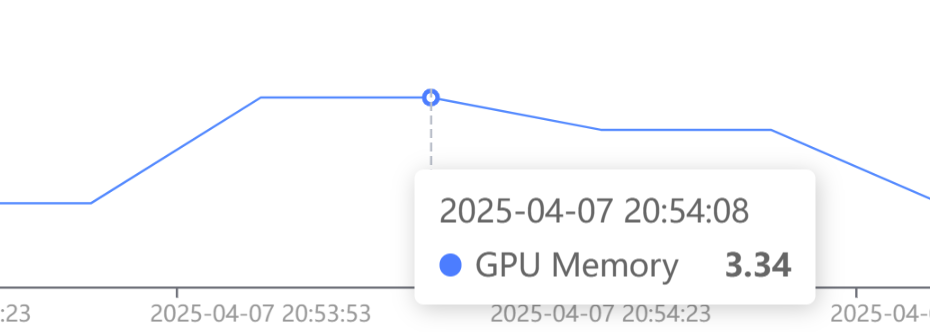
GPU 利用率基本保持在 100%,显存峰值占用不超过 4 G。
内存至少确保 > 4 G,主要用于处理客户端发来的音频数据。
程序启动后,会维护一个worker字典,每个会话都有独立的worker实例,因此可以并行处理多个会话,一旦并发量上来以后,延迟也是肉眼可见地上升。
要实现负载均衡,需在 asr-server 服务端实现相关逻辑,然后在这里手动扩容。
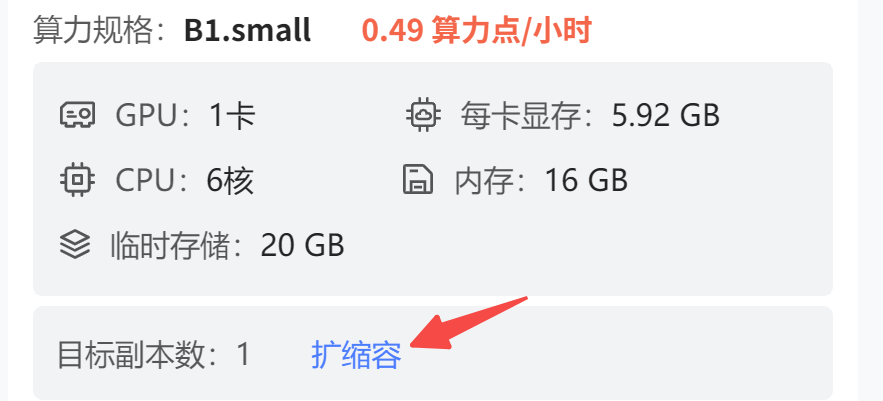
成本核算:
单台实例,一天 0.49 * 24 = 12元,合计 360 元的月租成本。
因此,想要自建服务端的朋友,单 ASR 这笔钱你可省的了?
最后,想自己玩玩的朋友,也可以去薅一波羊毛,新人注册送 100 点算力:
写在最后
本文主要分享了小智AI服务端ASR的几种实现方案,对本地部署-GPU推理方案的配置和成本进行了估算。
如果对你有帮助,欢迎点赞收藏备用。
下篇将给出CPU推理方案的实现,明天见。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 1496
1496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









