







前段时间,分享了低延迟小智AI服务端搭建的 ASR、LLM 和 TTS 部分:
从实测来看:
-
音频流式输入,VAD + ASR 部分的延时几乎可忽略。
-
LLM 采用流式推理,延时在 0.3-0.5s。
-
TTS 采用流式推理,延时在 0.3-0.5s。
因此,平均语音响应延迟可以达到 0.6s-1.0s。
而这三个环节中,成本最高的当属 TTS。
从本篇开始,我们将陆续分享几款开源的 TTS 模型,本地部署,实测所需硬件配置和响应延时,为各位技术选型提供参考。
模型选择的要求如下:
- RTF<1
- 支持流式推理
- 支持音色克隆
本篇,fishspeech 优先安排!
1. 关于 fishspeech
本地部署 fishspeech 并搭建音色克隆服务,笔者之前有分享过实操教程:FishSpeech 焕新升级,本地部署实测,在此不再赘述。
这里只对 fishspeech 架构的训练和推理过程,再做一补充。
下面这张图,左侧展示了 fishspeech 的两阶段训练过程,右侧是它的推理过程。
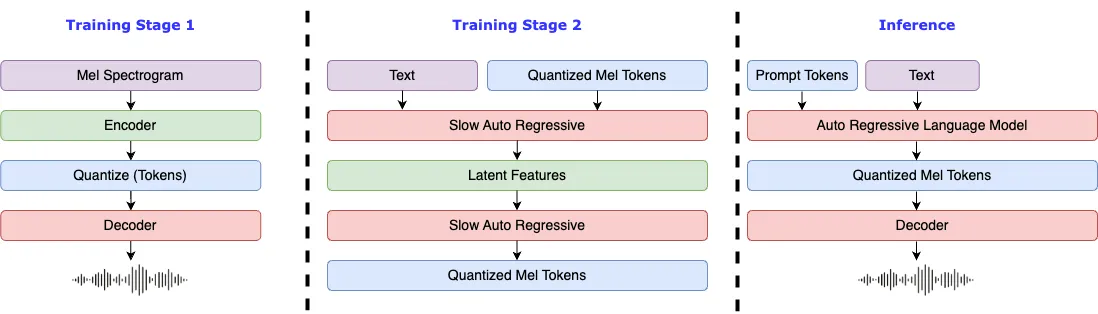
如何降低推理延时?
fish_speech/inference_engine/__init__.py
从上图可以发现,模型推理过程包括三步:
- 参考音频和参考文本的编码
- LLAMA model 推理获取待合成的音频tokens
- FFGAN解码器将音频tokens转换为声学特征,进而输出音频流
第一步-参考音频编码,可通过缓存来节省耗时。
fish_speech/inference_engine/reference_loader.py
TTSInferenceEngine 中,根据参考音频的 ID,在模型实例中缓存了音频编码特征:
if use_cache == "off" or id not in self.ref_by_id:
pass
else:
# Reuse already encoded references
logger.info("Use same references")
prompt_tokens, prompt_texts = self.ref_by_id[id]
2. 流式推理服务
fishspeech 开源仓库中已经提供了用 fastapi 封装的服务端部署代码,启动命令如下:
nohup python tools/api_server.py --listen 0.0.0.0:3003 --compile > server.log 2>&1 &
上篇中采用云端 TTS 的 API 均是采用 webscoket 协议提供服务,为了客户端能够自由切换,我们还需把上述 fastapi 服务封装成一个 webscoket 服务,接收 fastapi 服务输出的音频流,并发送给客户端。
class TTSWebSocketServer:
def __init__(self, host="0.0.0.0", port=8085):
self.host = host
self.port = port
self.sessions = {}
self.fish_url = "http://localhost:3003"
async def handler(self, websocket):
async for message in websocket:
await self.process_message(websocket, message)
async def process_message(self, websocket, message):
data = json.loads(message)
action = data.get("header", {}).get("action")
task_id = data.get("header", {}).get("task_id")
if action == "run-task":
await self.start_task(websocket, task_id, data)
elif action == "continue-task":
await self.continue_task(websocket, task_id, data)
elif action == "finish-task":
await self.finish_task(websocket, task_id)
async def start_task(self, websocket, task_id, data):
session = {
"task_id": task_id,
"params": data.get("payload", {}).get("parameters", {}),
"text": "",
}
user_id = session['params'].get('user', '')
voice_id = session['params'].get('voice', '')
sample_rate = session['params'].get('sample_rate', 0)
res = db.getVoice(user_id, voice_id)
if not res:
logging.error(f"Voice not found: {voice_id}")
return
session['voice_id'] = f'{user_id}/{voice_id}'
session['sample_rate'] = sample_rate
self.sessions[task_id] = session
# 发送 task-started 事件
await websocket.send(json.dumps({
"header": {"event": "task-started", "task_id": task_id}
}))
async def continue_task(self, websocket, task_id, data):
session = self.sessions.get(task_id)
if not session:
logging.warning(f"Session not found: {task_id}")
return
# 添加文本
text = data.get("payload", {}).get("input", {}).get("text", "")
session["text"] += text
# 生成音频数据
data = {
"text": text,
"reference_id": session['voice_id'],
"streaming" : True,
"use_memory_cache": "on",
}
pydantic_data = ServeTTSRequest(**data)
data = ormsgpack.packb(pydantic_data, option=ormsgpack.OPT_SERIALIZE_PYDANTIC)
headers = {'Content-Type': 'application/msgpack'}
async for chunk in self.fetch_audio(data, headers, sample_rate=session['sample_rate']):
try:
await websocket.send(chunk)
except websockets.exceptions.ConnectionClosedError as e:
logging.error(f"Connection closed: {e}")
break
await websocket.send(json.dumps({
"header": {"event": "sentence_end", "task_id": task_id, "text": text}
}))
async def fetch_audio(self, data, headers, sample_rate=24000):
async with aiohttp.ClientSession() as session:
async with session.post(f"{self.fish_url}/v1/tts", data=data, headers=headers) as response:
if response.status == 200:
async for chunk in response.content.iter_chunked(16000):
if chunk:
yield chunk
else:
logging.error(f"Error fetching audio: {response.status}")
async def finish_task(self, websocket, task_id):
session = self.sessions.get(task_id)
if not session:
logging.warning(f"Session not found: {task_id}")
return
# 发送 task-finished 事件
await websocket.send(json.dumps({
"header": {"event": "task-finished", "task_id": task_id}
}))
# 清理会话
del self.sessions[task_id]
async def start_server(self):
async with websockets.serve(
self.handler, self.host, self.port,
ping_interval=60, # 每 30 秒发送一次 Ping 帧
ping_timeout=30 # 等待 Pong 响应的超时时间为 10 秒
):
logging.info(f"WebSocket TTS Server running on ws://{self.host}:{self.port}")
await asyncio.Future() # 阻塞以保持服务运行
3. 硬件配置和响应延时
服务启动后的显存占用情况:

相比其它开源 TTS,fishspeech 对显存的要求,相当友好。
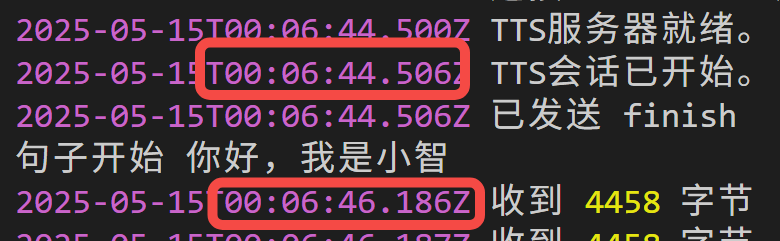
以下是在 RTX 4080 显卡上,流式推理,首个音频包到达客户端的延时情况。
第一次推理,需要对参考音频进行编码,首包延时近 2s:
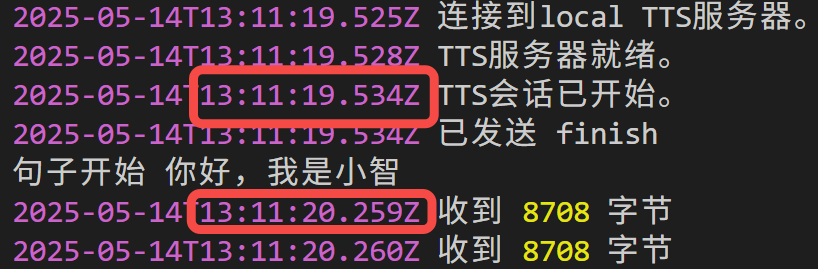
参考音频编码缓存后,后续推理,首包延时 0.7s:
注意:这是在模型没有任何优化的前提下,通过切换加速推理引擎/更换显卡设备,可进一步降低延时。
最后,我们把接收到的 pcm 数据转成 wav,来感受一下音质。
参考音频来自小智火爆出圈的
台湾腔女生-湾湾小何
ffmpeg -f s16le -ar 24000 -ac 1 -i tts.pcm tts.wav
写在最后
本文分享了小智AI服务端 本地TTS的实现,对fishspeech的首包延时进行了实测。
如果对你有帮助,欢迎点赞收藏备用。
后续,我们将继续实测几款支持流式推理的 TTS 模型,下篇见。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









