






在上一章中,我们看到神经网络通过随机梯度下降法可以学习权重和偏差。然而,之前我们没有解释过如何计算成本函数的梯度计算方法,这是个空白!在本章,我将会阐述一个计算这个梯度的快速算法,称为反向传播(backpropagation)算法。
反向传播算法最初在20世纪70年代提出,但是直到1986年, David Rumelhart, Geoffrey Hinton, and Ronald Williams三人的论文才使得它的重要性被认可。这篇论文介绍了一些神经网络的反向传播算法快于早期的方法,并且它可能可以解决一些之前解决不了的问题。今天反向传播算法是神经网络学习的一种主要方法。
本章所涉及到的数学知识很多。如果你对这些数学知识并不感兴趣,可以跳过本章,并且将反向传播算法作为一个黑盒去使用。那为什么我们要花时间来学习算法的细节呢?
当然,原因是为了能够理解算法。反向传播的核心是关于成本函数
C
的关于权重(或者关于偏差)的偏导数。表达式告诉我们如何当权重和偏差改变时,如何快速的更改成本函数。虽然表达式有点复杂,但是也是美丽的,每个元素都有着自然、直接的解释。所以反向传播学习的不仅仅是一个快速的算法,它实际上给了我们改变权重和偏差从而改变改变整体的细节。这是很值得深入研究的。
如果你想大致浏览下或者跳过本章,都是可以的。本书的其他部分你也是可以看懂的,只要将反向传播当做一个黑盒就行。当然,本章最后的推论结果应当是需要知道的。理解主要的结论,中间过程不需要明白。
Warm up: a fast matrix-based approach to computing the output from a neural network(复习:基于矩阵的快速计算神经网络输出的方法)
在讨论反向传播之前,让我们来复习下个基于矩阵的快速计算神经网络输出的方法。我们实际上在上一章的最后简单的介绍了这个算法,但是我很快的描述了它,因此我们需要重新了解下细节。特别地,在熟悉的上下文环境下,这是一个很舒服的方式去获得反向传播中使用的符合意义的。
让我们先以一种清晰的方式从权重的符号开始,我们将会
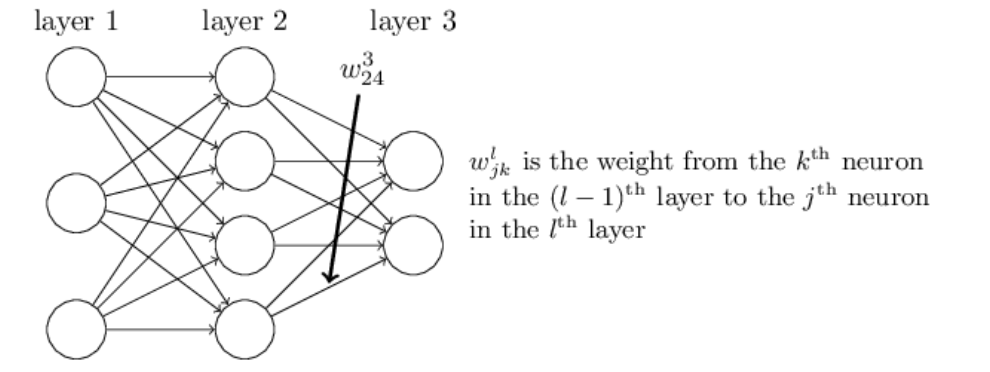
这个符号起初是很麻烦的,它确实需要一些工作来掌握。但是经过一段努力掌握后,你会发现这个符号变得很自然也很简单。一个奇怪的地方在于j和k的位置。你可能会觉得用j表示输入神经元,用k表示输出神经元更好,但是并不然,下面我会阐述理由。
我们使用熟悉的符号来表示网络中的偏差和激活状态。明确的是,我们用
blj
表示第
l
层第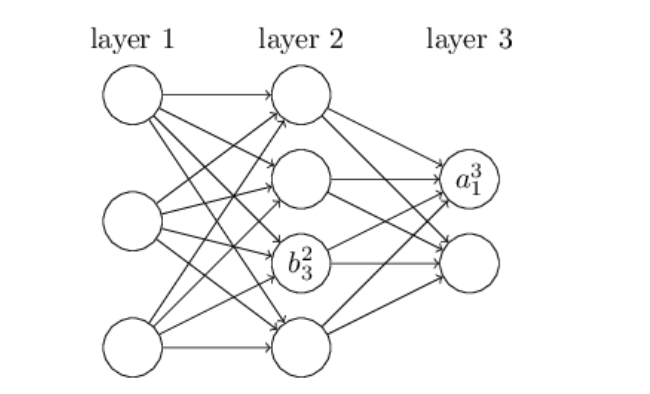
通过这些符号,第
l
层第
alj=σ(∑kwljkal−1k)+blj (23)
这里和指的是在
(l−1)th
层的所有k个神经元之和。用这个表达式重写第
l
层的权重矩阵
最后一个成分我们需要用矩阵形式重写的是作用于向量的函数,比如
σ
。我们在上一章中简单的描述了。我们用一个明显的符号
σ(v)
来表示这类函数的对应元素的应用。也就是说,
σ(v)
仅仅是
σ(v)j=σ(vj)
。举个例子,如果我们有函数
f(x)=x2
,那么对于向量它的作用如下:
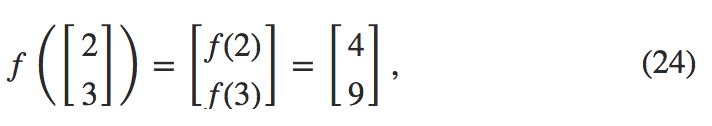
也就是说,向量化函数
f
对于向量中的每个元素都进行了平方。
记住上面的这些符号定义,那么方程(23)即可重写为一个非常美丽的的形式如下。
这种表达式给了我们一个更加全局的方式去了解如何在一层的激活与上一层激活状态的思考:我们只是应用权重矩阵激活,然后加偏置向量,最后运用σ函数。这种全局观念在神经元和神经元之间往往更容易、更简洁(包括更少的指标!)。现在我们采取这种方式。这种方式可以想象成一种避免下标的方式,这种表达式在实践中也是很有用的,因为在大多数矩阵库提供了快速的方式来计算矩阵的乘法,向量的加法和向量化。事实上,最后一章中的代码隐式使用这个表达式来计算网络的行为。
我们用方程(25)来计算
al
,我们计算中间的内容
zl≡=wlal−1+bl
。这内容证明是有用的,值得命名:我们称
zl
是
l
层的权重输入。我们将在下一章考虑权重输入















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









