









Python编程
链表list
在Python中链表的表示为:[](这是一个空链表),或者[‘A’,’B’].list中的元素是允许重复的!
##########有关列表的基本操作##############
#定义一个空链表
list1=[]
list1.appen(1)#在链表中中追加内容
#list1:[1]
list.append(2)
#list1:[1,2]
list1.append('A')
#list1:[1,2,'A']
print list1[1]#根据索引取数据
# 2,注意索引是从0开始的
print list1[0]#取出列表中的第一个元素
# 1
print list1[-1]#取出列表中的倒数第一个元素
# 'A'
print len(list1)#求列表的长度
# 3
del list1[0]#删除列表中的第一个元素
#此时的list1变为:[2,'A']
#列表之间的操作
list1=[1,2,3]
list2=[4,5,6]
list3=list1+list2 # +表示组合列表
#list3:[1,2,3,4,5,6]
list1=[1,2]
list2=list1*4 # *表示重复列表
#list2=[1,2,1,2,1,2,1,2]
#判断某一元素是否在链表中:
if 2 in [1,2,3]:
print True
else:
print False
# 结果为:True
#迭代(循环列表)
for x in [1,2,3]:
print x
'''
输出结果为:
1
2
3
'''
#列表的截取或者切片
list1=['A','B','C','D']
list2=list1[1:]#从第二个元素开始截取列表
#list2:['B','C','D']
list3=[:-1]#截取列表截止到倒数第一个之前
#list3:['A','B','C']
list4=[:3]#截取列表截止到第四个元素之前
#list4:['A','B','C']
#列表函数和方法
cmp(list1,list2)
'''
如果比较的元素是同类型的,则比较其值,返回结果。
如果两个元素不是同一种类型,则检查它们是否是数字。
如果是数字,执行必要的数字强制类型转换,然后比较。
如果有一方的元素是数字,则另一方的元素"大"(数字是"最小的")
否则,通过类型名字的字母顺序进行比较。
如果有一个列表首先到达末尾,则另一个长一点的列表"大"。
如果我们用尽了两个列表的元素而且所 有元素都是相等的,那么结果就是个平局,就是说返回一个 0。
'''
#!/usr/bin/python
list1, list2 = [123, 'xyz'], [456, 'abc']
print cmp(list1, list2);
print cmp(list2, list1);
list3 = list2 + [786];
print cmp(list2, list3)
以上实例输出结果如下:
-1
1
-1
#求最大最小
list1=[1,2,3,4]
print max(list)
# 4
test=['A','B','C','D',1,3]
print max(test)
# 'D' 注意在左右的字符中,数字是最小的
print min(list1)#求最小
# 1
list1=[1,2,2,2,3,4,4,5]
print list1.count(2)
# 3 统计元素‘2’出现的次数
print list1.index(2)#从列表中找出某个值第一个匹配项的索引位置
list1.insert(2,'A')#在索引2处插入元素‘A’
#list1:[1,2,'A',2,2,3,4,4,5]
print list1.pop()#移除列表中的最后一个元素,并返回值
#此时的list1变为:[1,2,'A',2,2,3,4,4]
print list1.pop(3)#移除索引3处的元素,并返回此处的值
list1.remove(4)#移除第一个元素4的匹配项,注意remove不返回值
#此时的list1变为[1,2,'A',2,2,3,4]
list1.reverse()#反向列表中的元素,也不能返回任何东西
print list1
#[4,3,2,2,'A',2,1]
list1.sort()#原表进行排序,按照升序排序
#[1, 2, 2, 2, 3, 4, 'A']
集合set
在Python中集合用()来表表示,例如()表示一个空集合。set中的元素是不允许重复的!
##################有关集合的基本操作#############
#定义一个空集合
a=set()
#或者
a=('boy')
print a
#set(['y', 'b', 'o'])
#python集合的添加有两种常用的方法,分别是add和update。
集合add方法:是把要传入的元素作为一个整体添加到集合中,例如“
”
>>> a = set('boy')
>>> a.add('python')
>>> a
set(['y', 'python', 'b', 'o'])
集合update方法:是把要传入的元素拆分,做为个体传入到集合中,例如:
>>> a = set('boy')
>>> a.update('python')
>>> a
set(['b', 'h', 'o', 'n', 'p', 't', 'y'])
集合删除操作方法:remove
set(['y', 'python', 'b', 'o'])
>>> a.remove('python')
>>> a
set(['y', 'b', 'o'])集合的交集、合集(并集)、差集,了解python集合set与列表list的这些非常好用的功能前,要先了解一些集合操作符号:

统计词频 调用nltk模块中的FreqDist
#调用FreqDist统计词频
from nltk import FreqDist
import jieba
words=jieba.cut(test_str)
fdis1=FreqDist(words)
print fdis1
print fdis1.N()
for key in fdis1.keys():
print key,fdis1[key]
print len(fdis1.keys())
print len(set(fdis1.keys()))双词搭配 调用nltk 中的bigrams
from nltk import bigrams
bi=bigrams(['我','们','祖','国'])
for w in bi:
print w[0],w[1]
print fdis1.max()
print fdis1[u',']自动理解自然语言
词意消歧
在词意消歧中,我们要算出特定上下文中的词被赋予的是哪个意思。汉语博大精深,存在一词多义的情况,这个时候我们就要根据词的上下文,赋予其真正的含义。换句话说,自动消除歧义需要使用上下文,利用相邻词汇有相近含义(相邻词所表示的含义肯定是同领域,同语境和意境下的)这样一个简单的事实。指代消解
一种跟深刻的语言理解是解决“谁对谁做了什么”,即检测主语和动词的宾语都是谁。
处理这个问题的计算技术包括:
指代消解(anaphora resolution)-----确定代词或者名词短语指的是什么。
语义角色标注(Semantic role labeling)----确定名词短语如何与动词相关。
自动生成语言
如果我们能够解决自动语言理解等问题,我们将能够继续那些包含自动生成语言的任务,如自动问答和机器翻译等。在这些任务重,计算机主要需要弄清楚词的含义、动作的主语以及代词的先行词是理解句子含义的步骤,也是我们希望语言理解系统能够做到的事情。机器翻译
长久以来,机器翻译(MT)都是语言理解的圣杯,人们希望能够找到从根本上提供高质量的符合语言习惯的任意两种语言之间的解释。
机器翻译是困难的,因为一个给定的词可能有几种不同的解释(取决于它的意思),也因为必须改变词序才能与目标语言的语法结构保持一致。人机对话系统
在人工智能的历史,主要的智能测试一个语言学测试,叫做图灵测试。
图灵测试:一个响应用户文本输入的对话系统能够表现的自然到我们无法区分它是人还是计算机。
对话系统给我们一个机会来说说一般认为的NLP 流程。下图显示了一个简单的对话系统架构。沿图的顶部从左向右是一些语言理解组件的“管道”。这些组件从语音输入经过文法分析到某种意义的重现。图的中间,从右向左是这些组件的逆向流程,将概念转换为语音。这些组件构成了系统的动态方面。在图的底部是一些有代表性的静态信息:语言相关的数据仓库,这些用于处理的组件在其上运作。 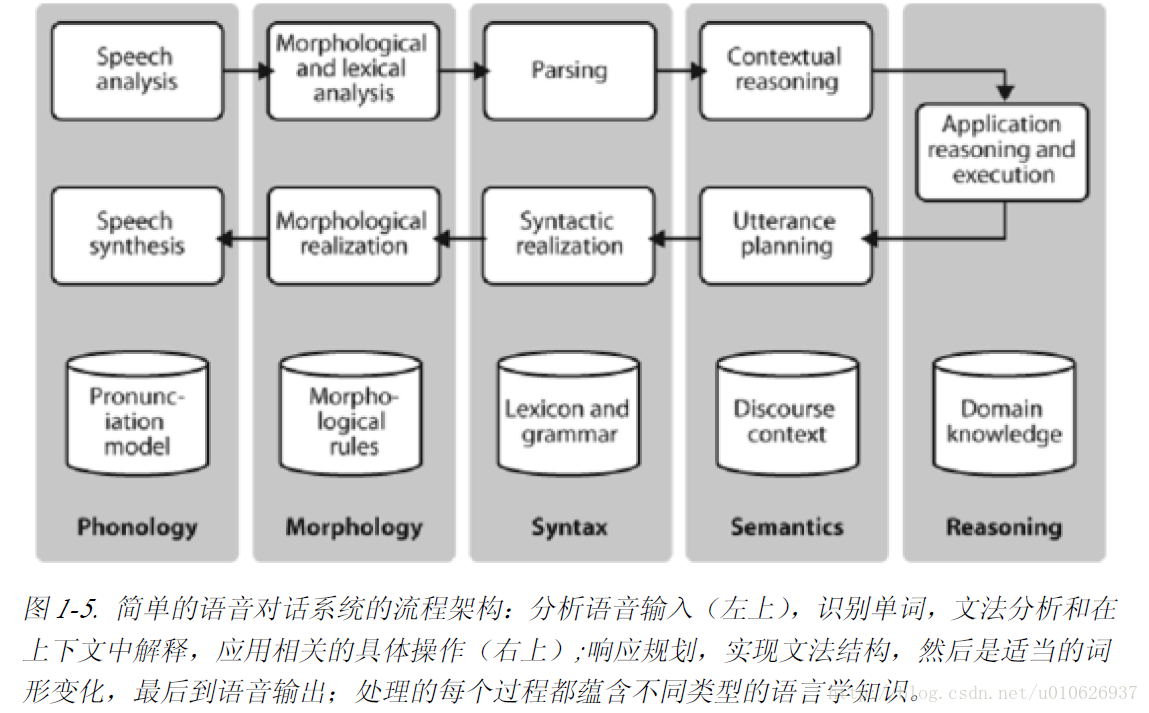
文本的含义
近年来,一个叫做文本含义识别(Recognizing Textual Entailment 简称RTE)的公开的“共享任务”使语言理解所面临的挑战成为关注焦点。基本情形很简单:假设你想找到证据来支持一个假设:Sandra Goudie 被Max Purnell 击败了。而你有一段简短的文字似乎是有关的,例如:Sandra Goudie 在2002 年国会选举首次当选,通过击败工党候选人Max Purnell 将现任绿党下院议员Jeanette Fitzsimons 推到第三位,以微弱优势赢得了Coromandel 席位。文本是否为你接受假说提供了足够的证据呢?在这种特殊情况下,答案是“否”。你可以很容易得出这样的结论,但使用自动方法做出正确决策是困难的。RTE 挑战为竞赛者开发他们的系统提供数据,但这些数据对“蛮力”机器学习技术(我们将在第6 章讲述这一主题)来说是不够的。因此,一些语言学分析是至关重要的。在前面的例子中,很重要的一点是让系统知道Sandra Goudie 是假设中被击败的人,而不是文本中击败别人的人。
NLP的局限性
尽管在很多如RTE 这样的任务中研究取得了进展,但在现实世界的应用中已经部署的语言理解系统仍然不能进行常识推理或以一种一般的可靠的方式描绘这个世界的知识。我们在等待这些困难的人工智能问题得到解决的同时,接受一些在推理和知识能力上存在严重限制的自然语言系统是有必要的。因此,从一开始,自然语言处理研究的一个重要目标一直是使用浅显但强大的技术代替无边无际的知识和推理能力,促进构建“语言理解”技术的艰巨任务的不断取得进展。
《本节完》
所谓的不平凡就是平凡的N次幂。
------By Ada
















 2679
2679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











