






2024.4.21 知识图谱大模型调研和部署
我们获得了富含大量语义信息和知识的文本数据,现在问题是如何通过这些数据构建知识图谱和训练大模型让其在相关领域具有更好的理解、表示、推理和生成能力。
一、模型选择
1. BERT-based Models (如 BERT, RoBERTa, SpanBERT)
-
特点和优势:
- BERT:基于Transformer架构,双向编码,适合各种NLP任务。
- RoBERTa:在BERT基础上优化了训练过程,效果更好。
- SpanBERT:专门优化了span-level表示,提升了实体和关系识别的性能。
-
训练方法:
- 使用预训练的BERT模型,然后在特定任务的数据集上进行微调(fine-tuning)。
- 数据集通常需要标注实体和关系。
-
部署方法:
- 使用
transformers库加载预训练模型并微调。 - 部署时可以使用
torch或ONNX等进行推理。
- 使用
-
注意事项:
- BERT模型较大,推理时需要较多资源。
- 微调需要高质量的标注数据。
2. GPT-based Models (如 GPT-3, GPT-4)
-
特点和优势:
- 强大的生成能力,适用于从文本生成知识图谱的任务。
- 通过自然语言提示(prompt)进行任务驱动,不需要专门微调。
-
训练方法:
- 使用预训练的GPT模型,针对具体任务设计合适的提示(prompt)。
- 可通过少量示例进行任务适应(少样本学习)。
-
部署方法:
- 使用API(如OpenAI的API)或
transformers库进行部署和调用。 - 部署时需要注意模型的推理延迟和成本。
- 使用API(如OpenAI的API)或
-
注意事项:
- 模型较大,推理成本高。
- 需要设计有效的提示来引导模型生成合适的输出。
3. Transformer-based Models 专为NLP任务设计 (如 T5, BART)
-
特点和优势:
- T5:统一的文本到文本框架,可以处理多种NLP任务。
- BART:结合了BERT和GPT的优点,适用于生成和序列标注任务。
-
训练方法:
- 使用预训练的模型,并在特定任务的数据集上进行微调。
- 数据集需要包含输入和输出对。
-
部署方法:
- 使用
transformers库进行加载和推理。 - 可以通过
ONNX或TorchScript优化推理性能。
- 使用
-
注意事项:
- 数据集的质量和规模对微调效果影响很大。
- 部署时需要注意内存和计算资源需求。
4. 专用模型 (如 SpaCy, Flair)
-
特点和优势:
- SpaCy:高效且易用,适合生产环境。
- Flair:灵活且易于扩展,支持多语言和多任务。
-
训练方法:
- 使用内置的预训练模型,或在自定义数据集上进行训练。
- 提供简单的API进行模型训练和评估。
-
部署方法:
- 部署时直接调用库的API。
- 可以通过容器化(如Docker)方便地进行部署。
-
注意事项:
- 对大规模任务可能性能不如BERT-based模型。
- 适合中小规模的数据和任务。
二、模型训练方法
1. 数据准备
- 收集和标注高质量的数据集,包括实体和关系标签。
- 数据集格式通常为CoNLL格式或JSON格式,包含文本、实体位置、实体类型和关系。
2. 预处理
- 数据清洗和预处理,确保数据质量。
- 对文本进行分词、标注等处理。
3. 模型微调
- 使用
transformers等库加载预训练模型。 - 在准备好的数据集上进行微调,调整超参数(如学习率、批次大小等)。
三、PaddleNLP 的 UIE 模型分析
一、基本特点和功能
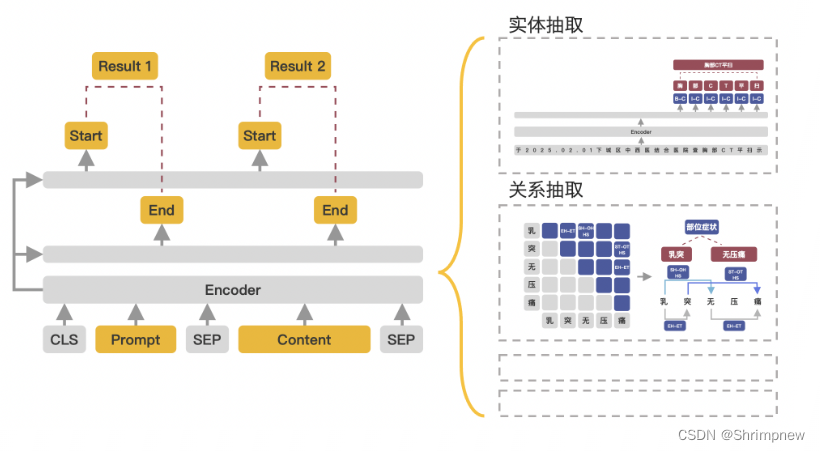
PaddleNLP 的 UIE(Universal Information Extraction)模型是一个强大的信息抽取模型,基于PaddlePaddle深度学习框架开发,设计用于处理多种信息抽取任务,包括命名实体识别(NER)、关系抽取(RE)、事件抽取等。UIE模型的核心特点和功能包括:
- 通用性:UIE模型可以通过统一的架构处理多种信息抽取任务,减少了为不同任务训练不同模型的需求。
- 预训练与微调:利用预训练技术,在大规模无监督数据上进行预训练,然后在特定任务上微调,提高模型的效果。
- 端到端训练:模型可以通过端到端训练方法,直接从原始文本到信息抽取结果,无需额外的手工特征工程。
- 高效性:PaddlePaddle框架提供了高效的训练和推理性能,支持多种硬件加速,包括GPU和CPU。
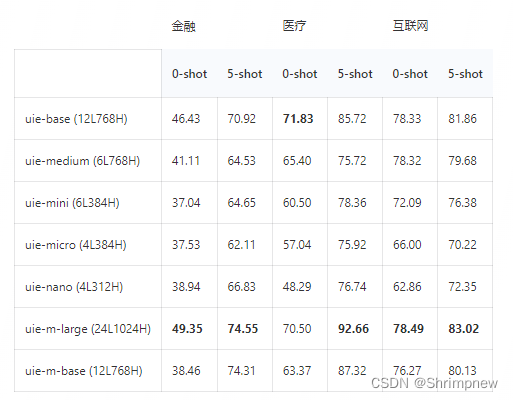
二、在实体识别和关系提取上的优劣势
优势:
- 统一框架:UIE模型使用统一的框架进行训练和推理,能够处理不同类型的抽取任务(实体、关系、事件等),简化了开发和部署流程。
- 高准确性:得益于预训练技术和大规模数据训练,UIE模型在实体识别和关系提取任务上具有较高的准确性。
- 灵活性:模型可以方便地适应不同的领域和任务,只需少量的标注数据进行微调。
- 扩展性:基于PaddlePaddle框架,UIE模型可以方便地进行扩展和优化,适用于大规模工业应用。
劣势:
- 资源需求高:与其他大型预训练模型类似,UIE模型的训练和推理过程需要较高的计算资源,尤其是显存和内存。
- 数据依赖:模型的效果高度依赖于训练数据的质量和数量,需要大量高质量的标注数据进行微调。
- 复杂性:对于初学者或小型团队,使用和调试大型预训练模型可能存在一定的复杂性和门槛。
实体抽取
命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体。在开放域信息抽取中,抽取的类别没有限制,用户可以自己定义。
例如抽取的目标实体类型是"时间"、"选手"和"赛事名称", 调用示例如下:
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema, model='uie-base')
ie_en = Taskflow('information_extraction', schema=schema, model='uie-base-en')
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint关系抽取
关系抽取(Relation Extraction,简称RE),是指从文本中识别实体并抽取实体之间的语义关系,进而获取三元组信息,即<主体,谓语,客体>。
例如以"竞赛名称"作为抽取主体,抽取关系类型为"主办方"、"承办方"和"已举办次数", 调用示例如下:
schema = {'竞赛名称': ['主办方', '承办方', '已举办次数']} # Define the schema for relation extraction
ie.set_schema(schema) # Reset schema
pprint(ie('2022语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,百度公司、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办,已连续举办4届,成为全球最热门的中文NLP赛事之一。'))事件抽取
事件抽取 (Event Extraction, 简称EE),是指从自然语言文本中抽取预定义的事件触发词(Trigger)和事件论元(Argument),组合为相应的事件结构化信息。
例如抽取的目标是"地震"事件的"地震强度"、"时间"、"震中位置"和"震源深度"这些信息,调用示例如下:
schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # Define the schema for event extraction
ie.set_schema(schema) # Reset schema
ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')评论观点抽取
评论观点抽取,是指抽取文本中包含的评价维度、观点词。
例如抽取的目标是文本中包含的评价维度及其对应的观点词和情感倾向,调用示例如下:
schema = {'评价维度': ['观点词', '情感倾向[正向,负向]']} # Define the schema for opinion extraction
ie.set_schema(schema) # Reset schema
pprint(ie("店面干净,很清静,服务员服务热情,性价比很高,发现收银台有排队")) # Better print results using pprint英文模型调用示例如下:
schema = [{'Aspect': ['Opinion', 'Sentiment classification [negative, positive]']}]
ie_en.set_schema(schema)
pprint(ie_en("The teacher is very nice."))情感分类
句子级情感倾向分类,即判断句子的情感倾向是“正向”还是“负向”,调用示例如下:
schema = '情感倾向[正向,负向]' # Define the schema for sentence-level sentiment classification
ie.set_schema(schema) # Reset schema
ie('这个产品用起来真的很流畅,我非常喜欢')英文模型调用示例如下:
schema = 'Sentiment classification [negative, positive]'
ie_en.set_schema(schema)
ie_en('I am sorry but this is the worst film I have ever seen in my life.')跨任务抽取
例如在法律场景同时对文本进行实体抽取和关系抽取,调用示例如:
schema = ['法院', {'原告': '委托代理人'}, {'被告': '委托代理人'}]
ie.set_schema(schema)
pprint(ie("北京市海淀区人民法院\n民事判决书\n(199x)建初字第xxx号\n原告:张三。\n委托代理人李四,北京市 A律师事务所律师。\n被告:B公司,法定代表人王五,开发公司总经理。\n委托代理人赵六,北京市 C律师事务所律师。")) # Better
三、模型训练和部署到本地的详细步骤
1. 环境准备
首先,安装PaddlePaddle和PaddleNLP库:
pip install paddlepaddle-gpu
pip install paddlenlp
2. 下载和准备数据
3. 数据预处理
使用PaddleNLP的工具进行数据预处理:
from paddlenlp.datasets import load_dataset
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
data = json.loads(line)
yield {'text': data['text'], 'entities': data['entities'], 'relations': data['relations']}
dataset = load_dataset(read, data_path='path/to/your/data')
4. 模型训练
使用PaddleNLP的UIE模型进行训练:
from paddlenlp.transformers import UIEModel, UIETokenizer
from paddlenlp.data import DataCollatorForTokenClassification
from paddlenlp.trainer import Trainer, TrainingArguments
model = UIEModel.from_pretrained('uie-base')
tokenizer = UIETokenizer.from_pretrained('uie-base')
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples['text'], truncation=True, padding='max_length', max_length=128)
labels = []
for i, label in enumerate(examples['entities']):
label_ids = [0] * len(tokenized_inputs['input_ids'][i])
for start, end, entity in label:
label_ids[start:end+1] = [1] * (end - start + 1)
labels.append(label_ids)
tokenized_inputs['labels'] = labels
return tokenized_inputs
tokenized_datasets = dataset.map(tokenize_and_align_labels, batched=True)
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['eval'],
tokenizer=tokenizer,
data_collator=DataCollatorForTokenClassification(tokenizer)
)
trainer.train()
5. 模型评估
使用验证集评估模型性能:
metrics = trainer.evaluate()
print(metrics)
6. 模型部署
将训练好的模型导出并部署为API服务:
from paddlehub.serving import application
import paddlehub as hub
model.save_pretrained('uie_model')
app = application.Application()
app.load('uie_model')
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
inputs = tokenizer(data['text'], return_tensors='pd')
outputs = model(**inputs)
# 处理输出并返回结果
return jsonify(outputs)
if __name__ == '__main__':
app.run()
7. 效果测试
from pprint import pprint
from paddlenlp import Taskflow
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
# schema = ['概念', '定义', '别名'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema, model='uie-base')
# ie = Taskflow('information_extraction', schema=schema, model='uie-m-base')
# ie = Taskflow('information_extraction', schema=schema, task_path='/home/yunpu/Data/codes/VCRS/UIE/checkpoint/model_best')
# ie = Taskflow('information_extraction', schema=schema, task_path='/home/yunpu/Data/codes/VCRS/UIE/checkpoint/model_best')
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
schema = ['实体'] # Define the schema for relation extraction
# schema = {'实体':['相关', '定义', '提供', '包含', '支持', '任务', '指导', '别名', '解决' ,'实现', '功能', '影响']}
# schema = {'实体':['相关']}
ie.set_schema(schema) # Reset schema
# pprint(ie("计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路和通信设备连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统。计算机网络主要是由一些通用的、可编程的硬件互连而成的。这些可编程的硬件能够用来传送多种不同类型的数据,并能支持广泛的和日益增长的应用。计算机网络Computer network计算机网络系统互联网信息的传输与共享网络操作系统计算机网络也称计算机通信网。关于计算机网络的最简单定义是:一些相互连接的、以共享资源为目的的、自治的计算机的集合。若按此定义,则早期的面向终端的网络都不能算是计算机网络,而只能称为联机系统(因为那时的许多终端不能算是自治的计算机)。但随着硬件价格的下降,许多终端都具有一定的智能,因而“终端”和“自治的计算机”逐渐失去了严格的界限。若用微型计算机作为终端使用,按上述定义,则早期的那种面向终端的网络也可称为计算机网络。另外,从逻辑功能上看,计算机网络是以传输信息为基础目的,用通信线路将多个计算机连接起来的计算机系统的集合,一个计算机网络组成包括传输介质和通信设备。从用户角度看,计算机网络是这样定义的:存在着一个能为用户自动管理的网络操作系统。由它调用完成用户所调用的资源,而整个网络像一个大的计算机系统一样,对用户是透明的。一个比较通用的定义是:利用通信线路将地理上分散的、具有独立功能的计算机系统和通信设备按不同的形式连接起来,以功能完善的网络软件及协议实现资源共享和信息传递的系统。从整体上来说计算机网络就是把分布在不同地理区域的计算机与专门的外部设备用通信线路互联成一个规模大、功能强的系统,从而使众多的计算机可以方便地互相传递信息,共享硬件、软件、数据信息等资源。简单来说,计算机网络就是由通信线路互相连接的许多自主工作的计算机构成的集合体。"))
pprint(ie("数据链路层的功能是为网络层提供服务。最主要的服务是将数据从源机器的网络层传输到目标机器的网络层。在源机器的网络层有一个实体(称为进程),它将一些比特交给数据链路层,要求传输到目标机器。数据链路层的任务就是将这些比特传输给目标机器,然后再进一步交付给网络层,如图3-2 Ca)所示。实际的传输过程则是沿着图3-2 Cb)所示的路径进行的,但很容易将这个过程想象成两个数据链路层的进程使用一个数据链路协议进行通信。基于这个原因,在本章中我们将隐式使用图3-2 Ca)的模型。"))
# schema = {'竞赛名称': ['主办方', '承办方', '已举办次数']} # Define the schema for relation extraction
# ie.set_schema(schema) # Reset schema
# pprint(ie('2022语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,百度公司、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办,已连续举办4届,成为全球最热门的中文NLP赛事之一。'))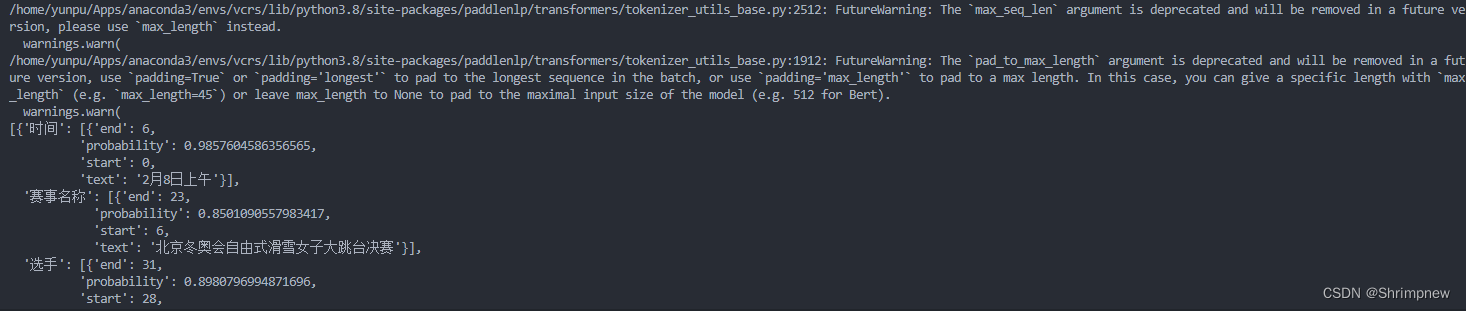
在模型原有的训练领域进行实体识别,表现良好

在计算机网络领域可以提取出少量实体
[{'实体': [{'end': 66,
'probability': 0.5219026066491139,
'start': 64,
'text': '进程'}]}]使用多种关系列表
schema = {'实体':['相关', '定义', '提供', '包含', '支持', '任务', '指导', '别名', '解决' ,'实现', '功能', '影响']}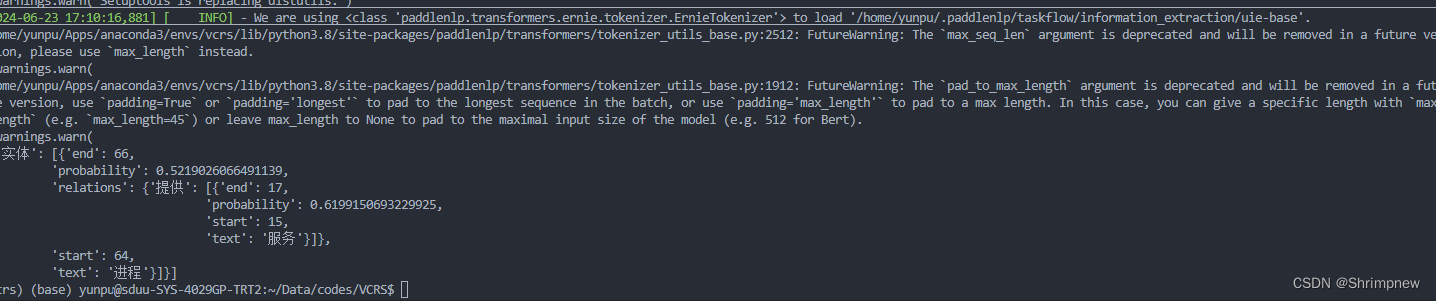 效果仍然不好
效果仍然不好
下一周我们将对该模型进行训练以提升实体识别和关系识别效果
四、模型选取和部署总结
paddle社区提供了十分完整易用的同意信息抽取模型UIE,并且经过了优秀的预训练过程,在许多领域上都取得了良好的信息提取效果,我们选用这个模型可以大大降低模型训练的风险。而且该模型配有比较完善的训练和测试代码,可以将主要工作放在数据集的精炼方面,已取得更好的模型训练效果。
该模型基于bert,部署所需的资源相对较少,运行速度快,十分适用于我们大数据量信息提取的问题背景,下周我的工作将针对于该模型的训练数据构建和模型训练与评估展开。















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









