






2024.5.26 知识图谱增强的大模型问答、检索调研
1. 知识图谱与语言模型融合的工作
1.1 K-BERT (Knowledge Enhanced BERT)
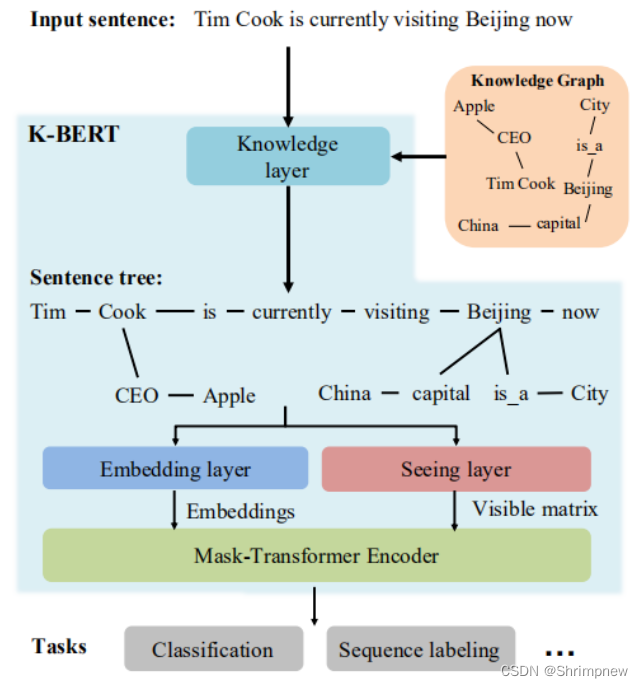
特点和思路:
- K-BERT 将知识图谱中的三元组嵌入到 BERT 的输入中,使得模型能够利用结构化的知识进行问答和检索。
- 通过在文本中插入实体及其关系节点,扩展了文本表示,从而在问答和信息检索任务中提供更丰富的语义信息。
优点:
- 利用现有的 BERT 架构,容易进行迁移学习。
- 能够增强模型对复杂问题的理解能力。
缺点:
- 需要预处理文本以嵌入知识图谱信息,增加了数据处理复杂度。
- 模型规模较大,训练和推理资源需求高。
模型和资源:
- 需要预训练的 BERT 模型(如 bert-base-uncased)。
- 需要额外的 GPU 资源用于训练和推理。
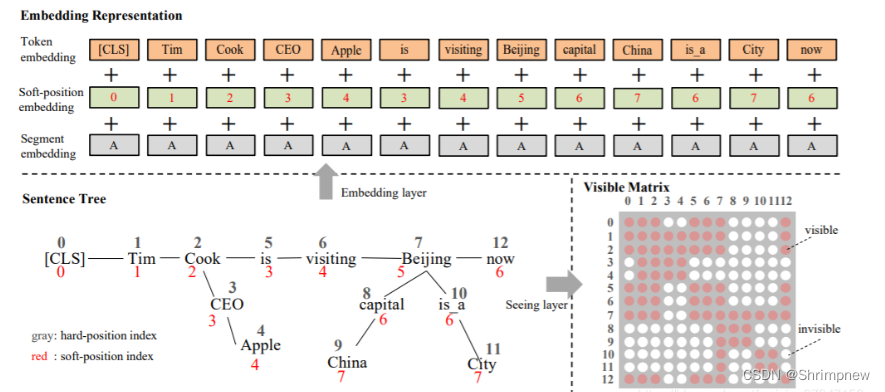
1.2 ERNIE (Enhanced Representation through Knowledge Integration)
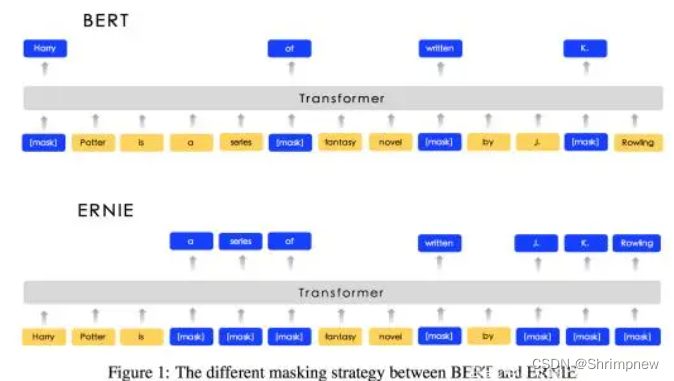
特点和思路:
- ERNIE 通过在训练过程中加入实体嵌入来增强语言模型的表示能力。
- 将知识图谱中的实体信息集成到 Transformer 结构中,使模型能够更好地理解和生成与知识相关的文本。
优点:
- 强化了模型对实体及其关系的理解能力,提高问答的准确性。
- 在多个自然语言理解任务上表现出色。
缺点:
- 需要复杂的预处理和知识集成步骤。
- 模型训练时间较长,对硬件资源要求高。
模型和资源:
- 预训练模型(如 ERNIE 1.0 或 ERNIE 2.0)。
- 需要大规模的计算资源,特别是多卡 GPU 环境。
1.3 KEPLER (Knowledge Embedding Pre-trained LanguagE Representations)
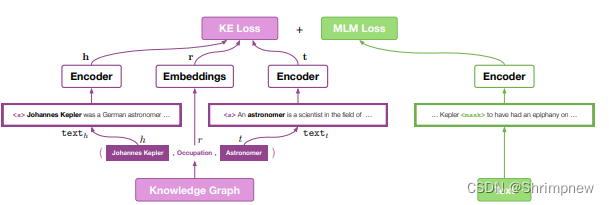
特点和思路:
- KEPLER 将知识图谱中的实体和关系嵌入到语言模型的预训练过程中。
- 通过联合训练知识图谱嵌入和语言模型,提供更丰富的语义表示。

优点:
- 在不显著增加模型复杂度的情况下增强语言模型的表现。
- 适用于多种下游任务,如问答、文本分类等。
缺点:
- 需要联合训练知识图谱和语言模型,训练过程复杂。
- 对硬件资源要求较高。
模型和资源:
- 基于 BERT 的预训练模型。
- 需要大规模的知识图谱数据和 GPU 资源。
2. 知识图谱增强问答和检索的实现思路
2.1 实时知识检索与融合
思路:
- 在用户查询时,实时从知识图谱中检索相关的实体和关系,融合到查询中以增强模型理解。
- 结合 Elasticsearch 等工具实现高效的知识检索。
优点:
- 能够动态响应用户查询,提供实时的知识增强。
- 灵活性高,可以适应多种知识图谱数据源。
缺点:
- 实时检索和融合会增加系统复杂度和响应时间。
- 需要高效的索引和检索系统支持。
资源需求:
- Elasticsearch 或其他搜索引擎。
- 实时数据处理和融合的计算资源。
2.2 预先嵌入知识的文本生成
思路:
- 在文本生成之前,通过查询知识图谱,将相关的实体和关系信息预先嵌入到生成模型的输入中。
- 利用已增强的文本生成模型(如 T5,GPT-3)进行问答和检索。
优点:
- 能够生成高质量的、知识丰富的回答。
- 预处理过程相对简单,易于实现。
缺点:
- 需要高质量的知识图谱数据和预处理步骤。
- 生成模型需要额外的知识嵌入模块。
资源需求:
- 预训练的文本生成模型。
- 数据预处理和知识嵌入的计算资源。
部署和实现的具体建议
-
选择合适的模型:
- 根据任务需求和资源情况选择合适的模型,例如选择 K-BERT 或 KEPLER 来进行问答任务。
- 考虑使用开源的预训练模型(如 Hugging Face 提供的 BERT 变体)以节省训练时间和资源。
-
知识图谱的构建和使用:
- 利用开源的知识图谱资源(如 DBpedia, Wikidata)。
- 使用现有的知识图谱工具(如 RDFLib, NetworkX)进行数据处理和检索。
-
系统架构:
- 部署基于 Elasticsearch 的知识检索系统,实现高效的知识查询。
- 使用 RESTful API 或 gRPC 服务实现模型推理和知识融合,确保系统的灵活性和可扩展性。
-
硬件和计算资源:
- 利用云服务(如 AWS, Google Cloud, Azure)提供的 GPU 实例进行模型训练和推理。
- 配置高效的缓存和存储系统以支持大规模知识数据的快速访问和处理。
通过以上方法,可以有效地利用知识图谱增强大模型的问答和检索能力,提升系统的智能性和实用性。















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









