






2024.5.12 使用模型进行命名实体识别和知识图谱关系提取
1. 工作概述
本周的工作旨在利用上周训练的 PaddleNLP 的 UIE 模型对现有文档数据进行实体识别和关系提取,从而构建知识图谱。提取出来的数据将分别存储到 JSON 文件和 Neo4j 数据库中。
2. 环境准备
2.1 安装必要的软件和库
确保安装以下软件和库Neo4j
pip install neo4j
2.2 设置 Neo4j 数据库
下载并安装 Neo4j 社区版:https://neo4j.com/download/
启动 Neo4j 数据库,并设置用户名和密码(默认用户名为 neo4j,密码可以自定义)。
3. 数据准备与预处理
将我们的爬取的所有数据按照上周训练模型的方式进行格式转换(仅跳过人工标注阶段)
import json
import re
def split_doc(doc):
single_sentences = re.split(r"(?<=[。!?])", docs[doc_title])
sentences = []
merged_sentence = ''
for sentence in single_sentences:
if len(merged_sentence) + len(sentence) < 512:
merged_sentence += sentence
else:
sentences.append(merged_sentence)
merged_sentence = sentence
if merged_sentence != '':
sentences.append(merged_sentence)
return sentences
if __name__ == '__main__':
domain_name = 'computer_network'
doc_f = open('/home/yunpu/Data/codes/VCRS/data/wiki_data/' + domain_name + '_docs.json' ,'r')
mention_f = open('/home/yunpu/Data/codes/VCRS/data/wiki_data/' + domain_name + '_mentions_with_title.json', 'r')
out_f = open('/home/yunpu/Data/codes/VCRS/UIE/data/' + domain_name + '_daccano.jsonl' ,'w')
# entitys = set()
# docs = {}
# for line in doc_f:
# doc = json.loads(line)
# assert doc['title'] not in entitys
# entitys.add(doc['title'])
# docs[doc['title']] = doc['content']
doc_titles = set()
docs = {}
entity_id = {}
cnt = 0
mentions = {}
for line in doc_f:
doc = json.loads(line)
assert doc['title'] not in doc_titles
doc_titles.add(doc['title'])
docs[doc['title']] = doc['content']
entity_id[doc['title']] = cnt
cnt += 1
for line in mention_f:
mention = json.loads(line)
if mention['doc_title'] not in mentions.keys():
mentions[mention['doc_title']] = [mention]
else:
mentions[mention['doc_title']].append(mention)
sample_cnt = 0
for doc_title in docs.keys():
if doc_title not in mentions.keys():
continue
# sentences = re.split(r"(?<=[。!?])", docs[doc_title])
sentences = split_doc(docs[doc_title])
if sample_cnt == 0:
print(sentences)
prelen = 0
cur = 0
for sentence in sentences:
if len(sentence) < 512:
sample = {}
sample['id'] = sample_cnt
sample_cnt += 1
sample['text'] = sentence
sample['relations'] = []
sample['entities'] = []
while cur < len(mentions[doc_title]) and mentions[doc_title][cur]['start_pos'] >= prelen and mentions[doc_title][cur]['end_pos'] <= prelen + len(sentence):
if mentions[doc_title][cur]['entity_name'] not in entity_id.keys():
entity_id[mentions[doc_title][cur]['entity_name']] = cnt
cnt += 1
entity = {
"id": entity_id[mentions[doc_title][cur]['entity_name']],
"start_offset": mentions[doc_title][cur]['start_pos'] - prelen,
"end_offset": mentions[doc_title][cur]['end_pos'] - prelen,
"label": "实体"
}
sample['entities'].append(entity)
cur += 1
if len(sample['entities']) == 0:
sample_cnt -= 1
else:
out_f.write(json.dumps(sample, ensure_ascii=False) + '\n')
prelen += len(sentence)
# if sample_cnt > 50:
# break
4. 实体识别与关系提取
使用 PaddleNLP 的 UIE 模型进行实体识别和关系提取。
from pprint import pprint
from paddlenlp import Taskflow
# schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
schema = ['概念', '定义', '别名'] # Define the schema for entity extraction
# ie = Taskflow('information_extraction', schema=schema, model='uie-base')
# ie = Taskflow('information_extraction', schema=schema, model='uie-m-base')
ie = Taskflow('information_extraction', schema=schema, task_path='/home/yunpu/Data/codes/VCRS/UIE/checkpoint/model_best')
# ie = Taskflow('information_extraction', schema=schema, task_path='/home/yunpu/Data/codes/VCRS/UIE/checkpoint/model_best')
# pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
# schema = ['实体'] # Define the schema for relation extraction
schema = {'实体':['相关', '定义', '提供', '包含', '支持', '任务', '指导', '别名', '解决' ,'实现', '功能', '影响']}
# schema = {'实体':['相关']}
ie.set_schema(schema) # Reset schema
# pprint(ie("计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路和通信设备连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统。计算机网络主要是由一些通用的、可编程的硬件互连而成的。这些可编程的硬件能够用来传送多种不同类型的数据,并能支持广泛的和日益增长的应用。计算机网络Computer network计算机网络系统互联网信息的传输与共享网络操作系统计算机网络也称计算机通信网。关于计算机网络的最简单定义是:一些相互连接的、以共享资源为目的的、自治的计算机的集合。若按此定义,则早期的面向终端的网络都不能算是计算机网络,而只能称为联机系统(因为那时的许多终端不能算是自治的计算机)。但随着硬件价格的下降,许多终端都具有一定的智能,因而“终端”和“自治的计算机”逐渐失去了严格的界限。若用微型计算机作为终端使用,按上述定义,则早期的那种面向终端的网络也可称为计算机网络。另外,从逻辑功能上看,计算机网络是以传输信息为基础目的,用通信线路将多个计算机连接起来的计算机系统的集合,一个计算机网络组成包括传输介质和通信设备。从用户角度看,计算机网络是这样定义的:存在着一个能为用户自动管理的网络操作系统。由它调用完成用户所调用的资源,而整个网络像一个大的计算机系统一样,对用户是透明的。一个比较通用的定义是:利用通信线路将地理上分散的、具有独立功能的计算机系统和通信设备按不同的形式连接起来,以功能完善的网络软件及协议实现资源共享和信息传递的系统。从整体上来说计算机网络就是把分布在不同地理区域的计算机与专门的外部设备用通信线路互联成一个规模大、功能强的系统,从而使众多的计算机可以方便地互相传递信息,共享硬件、软件、数据信息等资源。简单来说,计算机网络就是由通信线路互相连接的许多自主工作的计算机构成的集合体。"))
pprint(ie("数据链路层的功能是为网络层提供服务。最主要的服务是将数据从源机器的网络层传输到目标机器的网络层。在源机器的网络层有一个实体(称为进程),它将一些比特交给数据链路层,要求传输到目标机器。数据链路层的任务就是将这些比特传输给目标机器,然后再进一步交付给网络层,如图3-2 Ca)所示。实际的传输过程则是沿着图3-2 Cb)所示的路径进行的,但很容易将这个过程想象成两个数据链路层的进程使用一个数据链路协议进行通信。基于这个原因,在本章中我们将隐式使用图3-2 Ca)的模型。"))
# schema = {'竞赛名称': ['主办方', '承办方', '已举办次数']} # Define the schema for relation extraction
# ie.set_schema(schema) # Reset schema
# pprint(ie('2022语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,百度公司、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办,已连续举办4届,成为全球最热门的中文NLP赛事之一。'))实体关系提取结果
[{'实体': [{'end': 5,
'probability': 0.6005318961963724,
'relations': {'任务': [{'end': 200,
'probability': 0.9698870573010936,
'start': 194,
'text': '数据链路协议'},
{'end': 66,
'probability': 0.4390668090449168,
'start': 64,
'text': '进程'}],
'别名': [{'end': 5,
'probability': 0.4919679855852621,
'start': 0,
'text': '数据链路层'},
{'end': 66,
'probability': 0.5075148892749937,
'start': 64,
'text': '进程'},
{'end': 200,
'probability': 0.9762309109592202,
'start': 194,
'text': '数据链路协议'}],
'功能': [{'end': 13,
'probability': 0.44376848202138675,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9677385877496505,
'start': 194,
'text': '数据链路协议'}],
'包含': [{'end': 200,
'probability': 0.9632936000663435,
'start': 194,
'text': '数据链路协议'},
{'end': 66,
'probability': 0.7133097084983859,
'start': 64,
'text': '进程'},
{'end': 13,
'probability': 0.350316277516999,
'start': 10,
'text': '网络层'},
{'end': 74,
'probability': 0.4408596964685074,
'start': 72,
'text': '比特'}],
'定义': [{'end': 66,
'probability': 0.7746983510109118,
'start': 64,
'text': '进程'},
{'end': 13,
'probability': 0.2926227949657445,
'start': 10,
'text': '网络层'},
{'end': 5,
'probability': 0.3760399706607558,
'start': 0,
'text': '数据链路层'},
{'end': 200,
'probability': 0.9745190272374096,
'start': 194,
'text': '数据链路协议'},
{'end': 74,
'probability': 0.4548493369892199,
'start': 72,
'text': '比特'}],
'实现': [{'end': 200,
'probability': 0.965085009165108,
'start': 194,
'text': '数据链路协议'},
{'end': 66,
'probability': 0.33737749371358916,
'start': 64,
'text': '进程'}],
'影响': [{'end': 200,
'probability': 0.968669339943176,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.2814368158633087,
'start': 0,
'text': '数据链路层的功能是为网络层'},
{'end': 66,
'probability': 0.35398956152535277,
'start': 64,
'text': '进程'}],
'指导': [{'end': 66,
'probability': 0.7049022000343079,
'start': 64,
'text': '进程'},
{'end': 200,
'probability': 0.9693998137700177,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.3440330756493779,
'start': 10,
'text': '网络层'}],
'提供': [{'end': 200,
'probability': 0.9583710156460441,
'start': 194,
'text': '数据链路协议'},
{'end': 74,
'probability': 0.4320080527408372,
'start': 72,
'text': '比特'}],
'支持': [{'end': 200,
'probability': 0.9752165380922122,
'start': 194,
'text': '数据链路协议'}],
'相关': [{'end': 74,
'probability': 0.3743611816804062,
'start': 72,
'text': '比特'},
{'end': 200,
'probability': 0.9669209934058252,
'start': 194,
'text': '数据链路协议'},
{'end': 66,
'probability': 0.602049248791019,
'start': 64,
'text': '进程'},
{'end': 13,
'probability': 0.2815884586143511,
'start': 10,
'text': '网络层'}],
'解决': [{'end': 66,
'probability': 0.3170287021811369,
'start': 64,
'text': '进程'},
{'end': 13,
'probability': 0.3768038402505063,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9794629887107433,
'start': 194,
'text': '数据链路协议'}]},
'start': 0,
'text': '数据链路层'},
{'end': 215,
'probability': 0.6650135868184393,
'relations': {'任务': [{'end': 200,
'probability': 0.9952614241602831,
'start': 194,
'text': '数据链路协议'}],
'别名': [{'end': 5,
'probability': 0.7420704910728091,
'start': 0,
'text': '数据链路层'},
{'end': 200,
'probability': 0.9949301758251003,
'start': 194,
'text': '数据链路协议'}],
'功能': [{'end': 13,
'probability': 0.5364726319051272,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.996002579706655,
'start': 194,
'text': '数据链路协议'}],
'包含': [{'end': 200,
'probability': 0.9940045056794133,
'start': 194,
'text': '数据链路协议'},
{'end': 5,
'probability': 0.3356917194142497,
'start': 0,
'text': '数据链路层'},
{'end': 13,
'probability': 0.41103760404560674,
'start': 10,
'text': '网络层'}],
'定义': [{'end': 200,
'probability': 0.9968824343844638,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.34038113438623085,
'start': 10,
'text': '网络层'},
{'end': 5,
'probability': 0.7290466253792971,
'start': 0,
'text': '数据链路层'}],
'实现': [{'end': 200,
'probability': 0.9951321230631471,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.4129580369367716,
'start': 10,
'text': '网络层'}],
'影响': [{'end': 13,
'probability': 0.35869640112030154,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9945143671223633,
'start': 194,
'text': '数据链路协议'}],
'指导': [{'end': 200,
'probability': 0.9948704780196067,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.4504937063333685,
'start': 10,
'text': '网络层'},
{'end': 5,
'probability': 0.34261408132579163,
'start': 0,
'text': '数据链路层'}],
'提供': [{'end': 13,
'probability': 0.39763195758325054,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9936391754229064,
'start': 194,
'text': '数据链路协议'}],
'支持': [{'end': 200,
'probability': 0.9959154985722272,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.34308726511935816,
'start': 10,
'text': '网络层'}],
'相关': [{'end': 13,
'probability': 0.432190420703904,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9948869948353831,
'start': 194,
'text': '数据链路协议'},
{'end': 5,
'probability': 0.43909245306112865,
'start': 0,
'text': '数据链路层'}],
'解决': [{'end': 200,
'probability': 0.9974993152512006,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.2797731574461153,
'start': 10,
'text': '网络层'}]},
'start': 213,
'text': '本章'},
{'end': 13,
'probability': 0.6238407158454891,
'relations': {'任务': [{'end': 200,
'probability': 0.9839940784030254,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.31694098592878817,
'start': 10,
'text': '网络层'}],
'别名': [{'end': 5,
'probability': 0.797227933574348,
'start': 0,
'text': '数据链路层'},
{'end': 200,
'probability': 0.9834881590423947,
'start': 194,
'text': '数据链路协议'}],
'功能': [{'end': 200,
'probability': 0.9833944073903922,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.5149856991170481,
'start': 10,
'text': '网络层'}],
'包含': [{'end': 66,
'probability': 0.33095264769326604,
'start': 64,
'text': '进程'},
{'end': 13,
'probability': 0.47384069788556005,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9803019848715557,
'start': 194,
'text': '数据链路协议'},
{'end': 5,
'probability': 0.4585402659270521,
'start': 0,
'text': '数据链路层'}],
'定义': [{'end': 13,
'probability': 0.4456815305889563,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9889266342471572,
'start': 194,
'text': '数据链路协议'},
{'end': 5,
'probability': 0.7306352796176334,
'start': 0,
'text': '数据链路层'}],
'实现': [{'end': 200,
'probability': 0.9842405888379631,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.4948122085646034,
'start': 10,
'text': '网络层'},
{'end': 5,
'probability': 0.42174203350092654,
'start': 0,
'text': '数据链路层'}],
'影响': [{'end': 13,
'probability': 0.5796319731985342,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9799692801203825,
'start': 194,
'text': '数据链路协议'},
{'end': 5,
'probability': 0.35922441591354115,
'start': 0,
'text': '数据链路层'}],
'指导': [{'end': 200,
'probability': 0.9814421516329332,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.6013231551236089,
'start': 10,
'text': '网络层'},
{'end': 5,
'probability': 0.4329522415993097,
'start': 0,
'text': '数据链路层'}],
'提供': [{'end': 200,
'probability': 0.9778326669076023,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.3594617689496289,
'start': 10,
'text': '网络层'}],
'支持': [{'end': 13,
'probability': 0.6081998198690641,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9875006690457226,
'start': 194,
'text': '数据链路协议'}],
'相关': [{'end': 5,
'probability': 0.4378062414716908,
'start': 0,
'text': '数据链路层'},
{'end': 13,
'probability': 0.42953867361507037,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9838977612970545,
'start': 194,
'text': '数据链路协议'}],
'解决': [{'end': 13,
'probability': 0.49028739167711777,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9905621712259745,
'start': 194,
'text': '数据链路协议'}]},
'start': 10,
'text': '网络层'},
{'end': 66,
'probability': 0.8487259132296145,
'relations': {'任务': [{'end': 200,
'probability': 0.9935040593211397,
'start': 194,
'text': '数据链路协议'}],
'别名': [{'end': 200,
'probability': 0.994195473789901,
'start': 194,
'text': '数据链路协议'},
{'end': 5,
'probability': 0.6712277132313105,
'start': 0,
'text': '数据链路层'}],
'功能': [{'end': 200,
'probability': 0.9924854827858525,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.42719694525453633,
'start': 10,
'text': '网络层'}],
'包含': [{'end': 13,
'probability': 0.39829783541644304,
'start': 10,
'text': '网络层'},
{'end': 66,
'probability': 0.4676879334405726,
'start': 64,
'text': '进程'},
{'end': 5,
'probability': 0.39439215147044493,
'start': 0,
'text': '数据链路层'},
{'end': 200,
'probability': 0.9916918107047863,
'start': 194,
'text': '数据链路协议'}],
'定义': [{'end': 200,
'probability': 0.9957982942573409,
'start': 194,
'text': '数据链路协议'},
{'end': 5,
'probability': 0.5775194366399958,
'start': 0,
'text': '数据链路层'}],
'实现': [{'end': 5,
'probability': 0.32049253357394036,
'start': 0,
'text': '数据链路层'},
{'end': 13,
'probability': 0.35792611874876457,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9938605021066493,
'start': 194,
'text': '数据链路协议'}],
'影响': [{'end': 13,
'probability': 0.422854966861415,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.9910783764421289,
'start': 194,
'text': '数据链路协议'}],
'指导': [{'end': 5,
'probability': 0.3723472932997254,
'start': 0,
'text': '数据链路层'},
{'end': 200,
'probability': 0.9920228190599047,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.3644105925371832,
'start': 10,
'text': '网络层'}],
'提供': [{'end': 200,
'probability': 0.9908994025011744,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.2651048981189419,
'start': 10,
'text': '网络层'}],
'支持': [{'end': 13,
'probability': 0.3030407444525558,
'start': 10,
'text': '网络层'},
{'end': 200,
'probability': 0.993002295066443,
'start': 194,
'text': '数据链路协议'}],
'相关': [{'end': 13,
'probability': 0.35968502312524464,
'start': 10,
'text': '网络层'},
{'end': 5,
'probability': 0.4195980641421677,
'start': 0,
'text': '数据链路层'},
{'end': 200,
'probability': 0.9930614320943221,
'start': 194,
'text': '数据链路协议'}],
'解决': [{'end': 200,
'probability': 0.9957231702810674,
'start': 194,
'text': '数据链路协议'},
{'end': 13,
'probability': 0.2809384599513294,
'start': 10,
'text': '网络层'}]},
'start': 64,
'text': '进程'},
{'end': 200,
'probability': 0.9407074886524889,
'relations': {'任务': [{'end': 74,
'probability': 0.6407626259080175,
'start': 72,
'text': '比特'},
{'end': 66,
'probability': 0.8246515331119895,
'start': 64,
'text': '进程'},
{'end': 5,
'probability': 0.3696601705449538,
'start': 0,
'text': '数据链路层'}],
'别名': [{'end': 5,
'probability': 0.7368251290764078,
'start': 0,
'text': '数据链路层'},
{'end': 66,
'probability': 0.8100613017878544,
'start': 64,
'text': '进程'},
{'end': 74,
'probability': 0.740410508089802,
'start': 72,
'text': '比特'}],
'功能': [{'end': 66,
'probability': 0.6695362652242558,
'start': 64,
'text': '进程'},
{'end': 5,
'probability': 0.4309593002430603,
'start': 0,
'text': '数据链路层'},
{'end': 74,
'probability': 0.6196142650640724,
'start': 72,
'text': '比特'}],
'包含': [{'end': 5,
'probability': 0.4294471158893316,
'start': 0,
'text': '数据链路层'},
{'end': 66,
'probability': 0.9205541830463702,
'start': 64,
'text': '进程'},
{'end': 74,
'probability': 0.7958977909329157,
'start': 72,
'text': '比特'}],
'定义': [{'end': 74,
'probability': 0.7894219480449465,
'start': 72,
'text': '比特'},
{'end': 66,
'probability': 0.8985861859004771,
'start': 64,
'text': '进程'},
{'end': 5,
'probability': 0.7379489772258196,
'start': 0,
'text': '数据链路层'}],
'实现': [{'end': 5,
'probability': 0.45267709632662445,
'start': 0,
'text': '数据链路层'},
{'end': 74,
'probability': 0.7296872311953564,
'start': 72,
'text': '比特'},
{'end': 66,
'probability': 0.7298387094659589,
'start': 64,
'text': '进程'}],
'影响': [{'end': 66,
'probability': 0.7107741023653062,
'start': 64,
'text': '进程'},
{'end': 74,
'probability': 0.677202151316461,
'start': 72,
'text': '比特'},
{'end': 5,
'probability': 0.4818855166231373,
'start': 0,
'text': '数据链路层'}],
'指导': [{'end': 66,
'probability': 0.8911173612628858,
'start': 64,
'text': '进程'},
{'end': 74,
'probability': 0.7083410350432473,
'start': 72,
'text': '比特'},
{'end': 5,
'probability': 0.4678058904227491,
'start': 0,
'text': '数据链路层'}],
'提供': [{'end': 66,
'probability': 0.6899213950442018,
'start': 64,
'text': '进程'},
{'end': 74,
'probability': 0.697454058175353,
'start': 72,
'text': '比特'},
{'end': 17,
'probability': 0.6544352524772457,
'start': 15,
'text': '服务'}],
'支持': [{'end': 5,
'probability': 0.4041058034012224,
'start': 0,
'text': '数据链路层'},
{'end': 74,
'probability': 0.6019848143083344,
'start': 72,
'text': '比特'},
{'end': 66,
'probability': 0.36837901853124677,
'start': 64,
'text': '进程'}],
'相关': [{'end': 66,
'probability': 0.8350349497168175,
'start': 64,
'text': '进程'},
{'end': 74,
'probability': 0.6774177338857506,
'start': 72,
'text': '比特'},
{'end': 5,
'probability': 0.5283086785997426,
'start': 0,
'text': '数据链路层'}],
'解决': [{'end': 5,
'probability': 0.49215391236450046,
'start': 0,
'text': '数据链路层'},
{'end': 66,
'probability': 0.7997520203900876,
'start': 64,
'text': '进程'},
{'end': 215,
'probability': 0.2633573696507341,
'start': 213,
'text': '本章'},
{'end': 13,
'probability': 0.2540792344813916,
'start': 10,
'text': '网络层'},
{'end': 74,
'probability': 0.6684181476453261,
'start': 72,
'text': '比特'}]},
'start': 194,
'text': '数据链路协议'}]}]实体关系提取代码
import json
from pprint import pprint
from paddlenlp import Taskflow
# 加载OCR结果
with open('result_ocr.json', 'r', encoding='utf-8') as file:
ocr_data = json.load(file)
# 拼接文本并划分片段
text = "".join(item[1] for item in ocr_data)
chunks = [text[i:i+512] for i in range(0, len(text), 512)]
# 设置schema和加载模型
schema = {'实体': ['相关', '定义', '提供', '包含', '支持', '任务', '指导', '别名', '解决', '实现', '功能', '影响']}
ie = Taskflow('information_extraction', schema=schema, task_path='/home/yunpu/Data/codes/VCRS/UIE/checkpoint/model_best')
ie.set_schema(schema)
# 处理每个片段并存储结果
results = []
for chunk in chunks:
result = ie(chunk)
results.extend(result)
# 结果存储为json格式
with open('extraction_results.json', 'w', encoding='utf-8') as file:
json.dump(results, file, ensure_ascii=False, indent=4)
pprint(results)
5. 数据存储到 JSON 文件
5.1 定义 JSON 文件存储函数
def save_to_json(data, filename='extracted_data.json'):
with open(filename, 'w', encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=4)
5.2 保存提取的数据到 JSON 文件
save_to_json(extracted_data)
6. 数据存储到 Neo4j 数据库
6.1 连接 Neo4j 数据库
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
username = "neo4j"
password = "your_password"
driver = GraphDatabase.driver(uri, auth=(username, password))
6.2 定义数据存储函数
def save_to_neo4j(data):
with driver.session() as session:
for item in data:
entities = item['entities']
relations = item['relations']
for entity in entities:
session.run(
"MERGE (e:Entity {name: $name, type: $type})",
name=entity['name'],
type=entity['type']
)
for relation in relations:
session.run(
"""
MATCH (e1:Entity {name: $start_name}), (e2:Entity {name: $end_name})
MERGE (e1)-[r:RELATION {type: $type}]->(e2)
""",
start_name=relation['start_name'],
end_name=relation['end_name'],
type=relation['type']
)
7. 大模型实体-关系提取
我们还直接使用大模型+任务提示的方式进行了实体和关系提取,并对比效果
7.1实体提取
from modelscope import AutoTokenizer, AutoModelForCausalLM
import json
f = open("./data/index_ocr.json")
item = json.load(f)
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-72B-Chat-Int4", revision='master', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"qwen/Qwen-72B-Chat-Int4", revision='master',
device_map="auto",
trust_remote_code=True
).eval()
# response, history = model.chat(tokenizer, "你好", history=None)
# print(response)
prompt = """
请提取文本中的术语并以{"实体名":,"英文名":}的json数组形式表示,名称不要带括号。
"""
for i in range(len(item)):
text = item[i][1]
response, history = model.chat(tokenizer, prompt + text, history=None)
print(response)
break使用教材中的定义模板和索引表来提取术语
索引的pdf格式如下:


使用ocr扫描pdf转为文字
from rapidocr_pdf import PDFExtracter
import json
pdf_extracter = PDFExtracter(print_verbose=True, use_cuda=True)
# pdf_path = "computer_networks_5.pdf"
pdf_path = "index.pdf"
texts = pdf_extracter(pdf_path, force_ocr=True)
print(texts)
with open('./index_ocr.json', 'w', encoding='utf-8') as f:
json.dump(texts, f, ensure_ascii=False) 得到如下结果
将文本按照索引定义的格式进行正则匹配,提取数据的中英文二元组
import json
import re
def extract_entities(text):
result = []
seen = set()
matches = re.findall(r'(([^)]+))', text)
for match in matches:
print(match)
split_content = re.split(r',|:|。|;', match)
for entity_name in split_content:
entity_name = entity_name.strip()
if "参见" in entity_name:
continue
if entity_name and entity_name not in seen:
seen.add(entity_name)
entity_id = len(result) + 1
result.append({"id": entity_id, "entity_name": entity_name})
return result
f = open("./data/index_ocr.json")
item = json.load(f)
text = ""
for i in range(len(item)):
text = text + item[i][1]
text.replace("\n", "")
print(text)
# text = "这是一个测试(中国,美国:日本。韩国;泰国)和另一个测试(中国,法国:德国。意大利;西班牙)"
entities = extract_entities(text)
print(entities)
out_f = open("./data/entities_cn.json", "w", encoding="utf-8")
out_f.write(json.dumps(entities, ensure_ascii=False))得到结果如下

7.2关系提取
单纯使用大模型+文本的形式进行实体关系提取
import modelscope
import transformers
prompt = """
你的任务是提取以下文本中所有的实体和他们之间的关系并按{"entity1": '', "relation": '', "entity2": ''}的格式输出。
"""
class GlmModel:
def __init__(self) -> None:
self.tokenizer = transformers.AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
self.model = transformers.AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
self.model = self.model.eval()
def text2re(self, text: str):
message = prompt + text
print("input:", message)
response, history = self.model.chat(self.tokenizer, message, history=None)
print("output:", response)
return response
class QwenModel:
def __init__(self) -> None:
self.tokenizer = modelscope.AutoTokenizer.from_pretrained("qwen/Qwen-72B-Chat-Int4", revision='master', trust_remote_code=True)
self.model = modelscope.AutoModelForCausalLM.from_pretrained(
"qwen/Qwen-72B-Chat-Int4", revision='master',
device_map="auto",
trust_remote_code=True
).eval()
def text2re(self, text: str):
message = prompt + text
print("input:", message)
response, history = self.model.chat(self.tokenizer, message, history=None)
print("output:", response)
return response
if __name__ == '__main__':
re_model = GlmModel()
f = open('./data/sample_text.txt', 'r')
doc = f.readline()
re = re_model.text2re(doc)
效果如下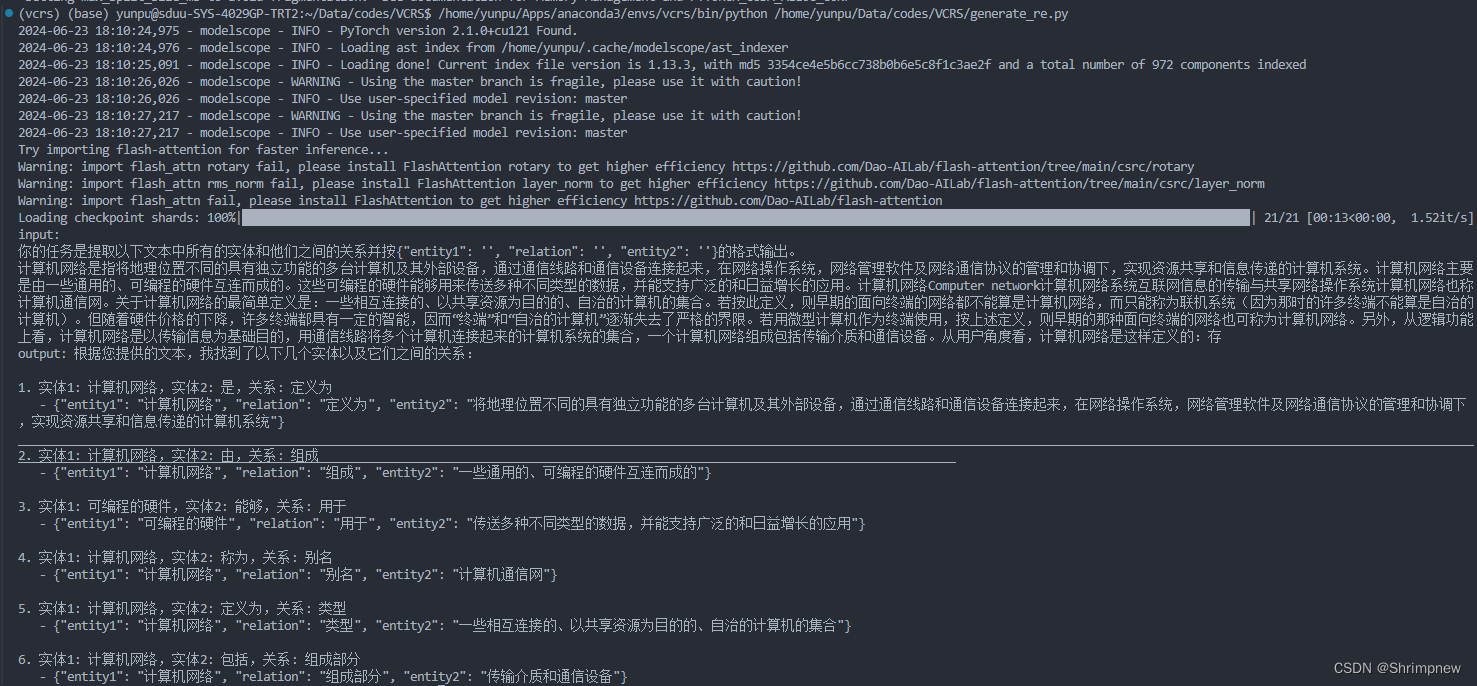
使用实现提取的术语表和实体作为提示,使用大模型提取关系
from modelscope import AutoTokenizer, AutoModelForCausalLM
import json
import re
def split_chinese_text(text):
"""
将中文文本按句子划分成列表
:param text: 中文文本
:return: 划分后的句子列表
"""
# 去除原句中的换行符
text = text.replace('\n', '')
# 使用正则表达式划分句子,以句号、问号和感叹号作为句子分隔符
sentences = re.split(r'([。?!])', text)
# 去除空白句子
sentences = [sentence.strip() for sentence in sentences if sentence.strip()]
# 将分隔符与前一句合并
merged_sentences = []
for i in range(0, len(sentences), 2):
if i + 1 < len(sentences):
merged_sentences.append(sentences[i] + sentences[i+1])
else:
merged_sentences.append(sentences[i])
return merged_sentences
entity_f = open("./data/entities_cn.json", "r", encoding="utf-8")
entities = json.load(entity_f)
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-72B-Chat-Int4", revision='master', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"qwen/Qwen-72B-Chat-Int4", revision='master',
device_map="auto",
trust_remote_code=True
).eval()
# response, history = model.chat(tokenizer, "你好", history=None)
# print(response)
doc_f = open("./data/result_ocr.json", "r", encoding="utf-8")
doc_arr = json.load(doc_f)
text = ""
for i in range(len(doc_arr)):
if i < 20:
continue
text = text + doc_arr[i][1]
# text = text.split("。")
# print(len(text))
sentences = split_chinese_text(text)
# print(len(sentences))
text = ""
max_len = 256
cnt = 0
re_prompt = """
根据文本回答给定实体间的强相关关系,用形如[{"subject": "", "relation": "", "object": ""}]的json三元组数组表示。
"""
prop_prompt = """
提取给定实体在文本中相关的句子作为description,总结实体与description间的关系作为relation,用形如[{"entity": "", "description": "", "relation": ""}]的json三元组数组表示。
"""
out_f = open("./data/cn_kg_prop.json", "w", encoding="utf-8")
for index, sentence in enumerate(sentences):
print(str(index) + '/' + str(len(sentences)))
if len(sentence) > max_len:
continue
if len(text) + len(sentence) <= max_len:
text += sentence
else:
entity_include = []
for entity in entities:
if len(entity["entity_name"]) < 2:
continue
if entity["entity_name"] in text:
entity_include.append(entity["entity_name"])
entity_str = "['" + "', '".join(entity_include) + "']"
if len(entity_include) == 0:
text = ""
continue
# print(text)
# print(entity_include)
response, history = model.chat(tokenizer, prop_prompt + "文本:\"" + text + "\"" + "实体:" + entity_str, history=None)
# print(response)
out_f.write(response + '\n')
cnt += 1
# if cnt == 10:
# break
text = ""提取的实体-关系
 提取的实体-描述
提取的实体-描述
















 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









