






不平衡数据在金融风控、反欺诈、广告推荐和医疗诊断中普遍存在。通常而言,不平衡数据正负样本的比例差异极大,如在Kaggle竞赛中的桑坦德银行交易预测和IEEE-CIS欺诈检测数据。对模型而言,不均衡数据构建的模型会更愿意偏向于多类别样本的标签,实际应用价值较低,如下图所示,为在不均衡数据下模型预测的概率分布。

不平衡数据的处理方法,常见方法有欠采样(under-sampling)和过采样(over-sampling)、在算法中增加不同类别的误分代价等方法。其中,过采样中的SMTOE、Borderline SMOTE和ADASYN是实现简单且常见的处理方法。
1 SMOTE
论文地址:http://xueshu.baidu.com/usercenter/paper/show?paperid=28300870422e64fd0ac338860cd0010a&site=xueshu_se
SMOTE(Synthetic Minority Oversampling Technique)合成少数类过采样技术,是在随机采样的基础上改进的一种过采样算法。实现过程如下图所示:

首先,从少数类样本中选取一个样本xi。其次,按采样倍率N,从xi的K近邻中随机选择N个样本xzi。最后,依次在xzi和xi之间随机合成新样本,合成公式如下:
x n = x i + β × ( x z i − x i ) x_{n}=x_{i}+\beta\times \left ( x_{zi} -x_{i} \right ) xn=xi+β×(xzi−xi)
SMOTE实现简单,但其弊端也很明显,由于SMOTE对所有少数类样本一视同仁,并未考虑近邻样本的类别信息,往往出现样本混叠现象,导致分类效果不佳。
SMOTE Python使用
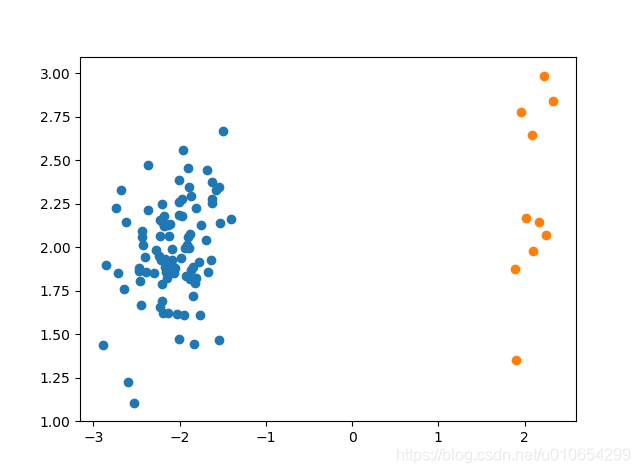
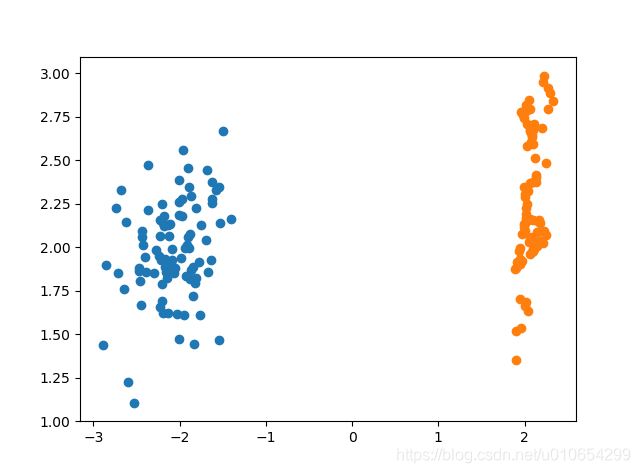
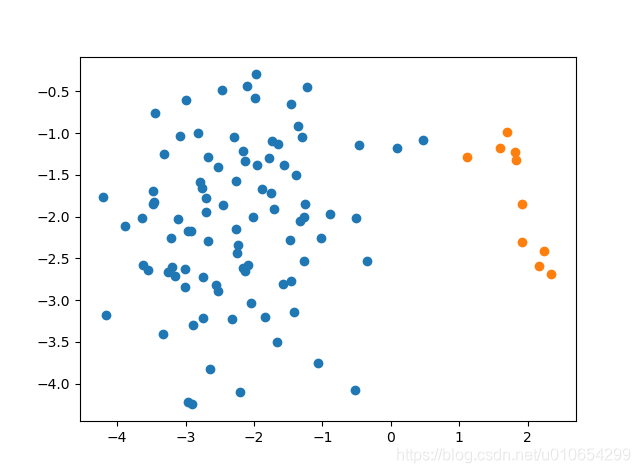
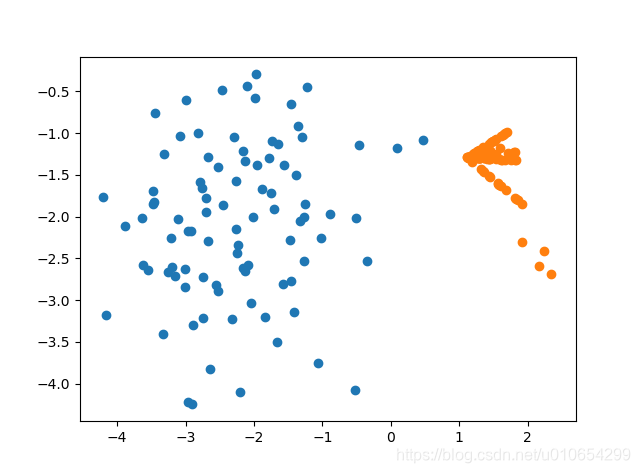
Python库中Imblearn是专门用于处理不平衡数据,imblearn库包含了SMOTE、SMOTEENN、ADASYN和KMeansSMOTE等算法。以下是SMOTE在Imblearn中使用的案例。
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=2, n_redundant=0, flip_y=0,
n_features=2, n_clusters_per_class=1, n_samples=100,random_state=10)
print('Original dataset shape %s' % Counter(y))
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)
print('Resampled dataset shape %s' % Counter(y_res))
SMOTE采样前后对比
2 Borderline SMOTE
论文地址:https://sci2s.ugr.es/keel/keel-dataset/pdfs/2005-Han-LNCS.pdf
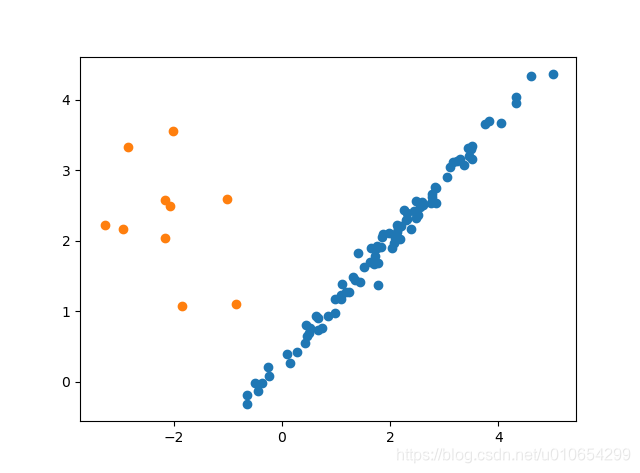
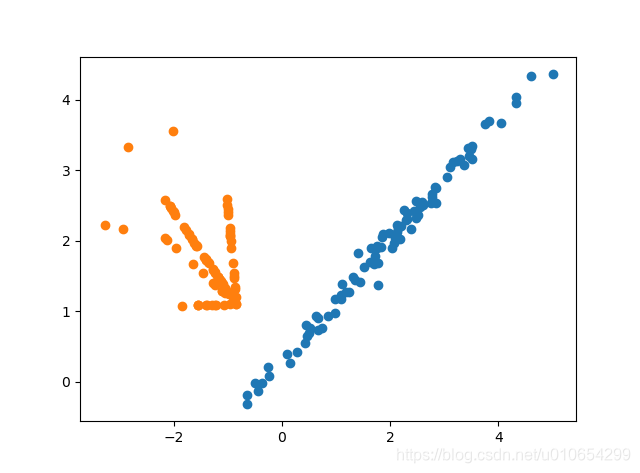
Borderline SMOTE是在SMOTE基础上改进的过采样算法,该算法仅使用边界上的少数类样本来合成新样本,从而改善样本的类别分布。
Borderline SMOTE采样过程是将少数类样本分为3类,分别为Safe、Danger和Noise,具体说明如下。最后,仅对表为Danger的少数类样本过采样。
Safe,样本周围一半以上均为少数类样本,如图中点A
Danger:样本周围一半以上均为多数类样本,视为在边界上的样本,如图中点B
Noise:样本周围均为多数类样本,视为噪音,如图中点C

Borderline-SMOTE又可分为Borderline-SMOTE1和Borderline-SMOTE2,Borderline-SMOTE1在对Danger点生成新样本时,在K近邻随机选择少数类样本(与SMOTE相同),Borderline-SMOTE2则是在k近邻中的任意一个样本(不关注样本类别)
Borderline-SMOTE Python使用
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import BorderlineSMOTE
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=2, n_redundant=0, flip_y=0,
n_features=2, n_clusters_per_class=1, n_samples=100, random_state=9)
print('Original dataset shape %s' % Counter(y))
sm = BorderlineSMOTE(random_state=42,kind="borderline-1")
X_res, y_res = sm.fit_resample(X, y)
print('Resampled dataset shape %s' % Counter(y_res))
Borderline SMOTE 采样前后对比
3 ADASYN
论文地址:https://sci2s.ugr.es/keel/pdf/algorithm/congreso/2008-He-ieee.pdf
ADASYN (adaptive synthetic sampling)自适应合成抽样,与Borderline SMOTE相似,对不同的少数类样本赋予不同的权重,从而生成不同数量的样本。具体流程如下:
步骤1:计算需要合成的样本数量,公式如下:
G = ( m l − m s ) × β G=\left ( m_{l}-m_{s} \right )\times \beta G=(ml−ms)×β
其中,ml为多数类样本数量,ms为少数类样本数量,β∈[0,1]随机数,若β等于1,采样后正负比例为1:1。
步骤2:计算K近邻中多数类占比,公式如下:
r i = Δ i / K r_{i}=\Delta _{i}/K ri=Δi/K
其中,∆i为K近邻中多数类样本数,i = 1,2,3,……,ms
步骤3:对ri标准化,公式如下:
r ^ i = r i / ∑ i = 1 m s r i \hat{r}_{i}=r_{i}/\sum_{i=1}^{m_{s}}r_{i} r^i=ri/i=1∑msri
步骤4:根据样本权重,计算每个少数类样本需生成新样本的数目,公式如下:
g = r ^ i × G g=\hat{r}_{i}\times G g=r^i×G
步骤5:根据g计算每个少数样本需生成的数目,根据SMOTE算法生成样本,公式如下:
s i = x i + ( x z i − x i ) × λ s_{i}=x_{i}+\left ( x_{zi}-x_{i} \right )\times \lambda si=xi+(xzi−xi)×λ
其中,si为合成样本,xi是少数类样本中第i个样本,xzi是xi的K近邻中随机选取一个少数类样本 λ∈[0,1]的随机数。
ADASYN Python使用
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import ADASYN
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1, n_samples=1000,
random_state=10)
print('Original dataset shape %s' % Counter(y))
ada = ADASYN(random_state=42)
X_res, y_res = ada.fit_resample(X, y)
print('Resampled dataset shape %s' % Counter(y_res))
ADASYN 采样前后对比

















 1563
1563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









