






严格来讲,编码器只会告诉你改如何定位,要如何执行,是需要靠数控系统(或者PLC之类控制器)控制伺服或者步进电机来实现定位的,编码器好比人的眼睛,知道电机轴或者负载处于当前某个位置,工业上用的一般是光电类型编码器,下边简单说明一下:
01
编码原理和位置测量
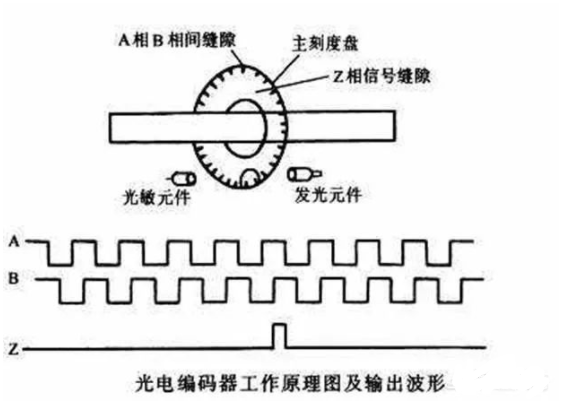
光电编码器是在一个很薄很轻的圆盘子上,通过紧密仪器来腐蚀雕刻了很多条细小的缝,相当于把一个360度,细分成很多等分,比如成1024组,这样每组之间的角度差是360/1024度=0.3515625度。
然后有个精密的发光源,安装在码盘的一面,码盘的另外一面,会有个接收器之类的,使用了光敏电阻这些元件加放大和整形电路组成,这样码盘转动时候,有缝隙的地方会透光过去,接收器会瞬间收到光脉冲,经过电路处理后,输出一个电脉冲信号,这样码盘旋转了一周,会对应输出1024个脉冲,第一个脉冲位置如果是0,第二个脉冲位置就是0.3515625°,第三个脉冲位置是0.3515625°*2,以此类推,这样只要有仪器能读到脉冲个数,就可以知道码盘对应在什么位置了。
如果把编码器安装到电机的轴上,电机轴和码盘是刚性连接,两者的位置关系会一一对应,通过读编码器脉冲,就可以知道电机的轴位置。

而电机轴,比如会通过同步带,齿轮,链条等带动一些负载,比如控制丝杆,这样会有个所谓电子齿轮比的关系,电机转一圈,丝杆会前进多少毫米,这样读到了对应编码器上输出多少给脉冲,通过脉冲数就可以反推出当前丝杆的位置。

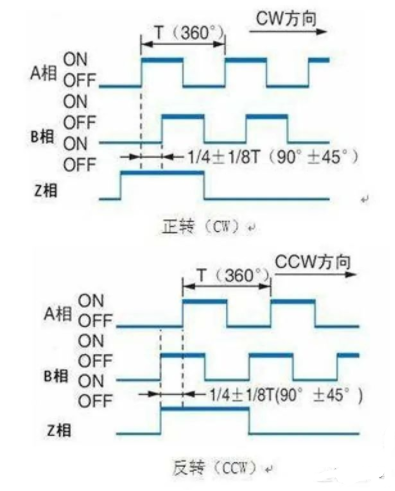
但是编码器是圆的,如果无限制旋转下去,角度会无穷大,所以设计了一种增量型的编码器,转一圈,会输出三组信号ABZ,其中AB是一样的脉冲,比如上边说的一圈有1024个脉冲,AB相脉冲对应一圈内的圆周角度,而且两种脉冲是处于正交状态的,如果是正反转,通过判断AB相脉冲的上升沿和下降沿的先后顺序,就可以知道编码器当前是顺时针还是逆时针方向旋转的,
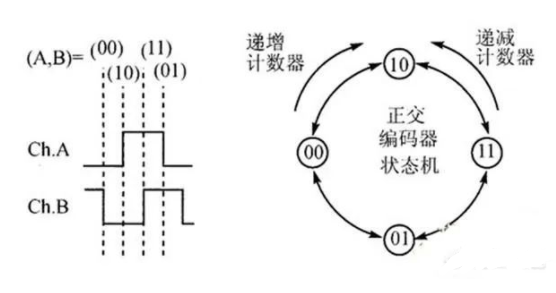
另外有个z相脉冲,是因为圆周虽然会不停转下去,角度会无穷无尽,但是都是一周一周的重复而已,零相脉冲固定在圆周某个位置,编码器每转一圈,只输出一个零相脉冲,这样如果以Z相脉冲为基准点,这样每次读到这个脉冲时候,系统就清零一次,就可以让角度最大值控制在360°以内,相当于一个零基准点了。这样即使系统断掉了,重新上电,只要能找到这个基准点,就可以知道丝杆的初始位置在什么地方了。
以上这种定位叫增量坐标系,所以编码器就是增量型编码器,应用比较广泛,因为灵活而且价格便宜。
如果只设备只需要转一圈的,也就是角度在360°内的,编码器可以细分精密一点,比如有13位,相当于2^13次方个脉冲一圈,对应着360°,这种脉冲数和角度一一对应,不怕系统断电需要重新调整零位,这种编码器叫单圈绝对值编码器。如果负载需要转多圈的,但是这个圈数也不能非常多,比如5圈,相当于5*360°=1800°,这样脉冲和1800°一一对应,这些在一些高档的数控机床上应用比较多,可以知道丝杆或者一些旋转工作的当前精密位置,而且不用担心系统断电归零问题。
此外,编码器还有磁电方式的,比如在码盘上加工了很多个南北间隔的小磁铁,通过霍尔去读小磁铁信号,输出信号,同样经过放大和整形变成了电脉冲,这点和光电编码器是类似的,而且价格会便宜点,可靠性会高,但是精度就比光电要差点。
02
PLC如何通过编码器判断位置
PLC能输入开关量,也就是一高一低的电平电压,而编码器脉冲信号,可以理解一定时间内,用极快的速度完成的一组开关量。但是因为这种开关量的频率太高了,所以PLC的普通I/O口是无法准确读到这些脉冲的个数的,因为PLC工作过程中存在扫描周期,需要每个一段时间才去刷新一下普通I/O口的数据,而编码器的精度太高了,单位时间内输出的脉冲个数太多,普通I/O是无法胜任的。
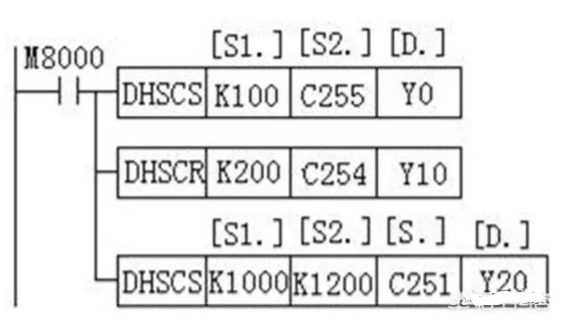
一般PLC会设计有高速计数端口,本质是利用了底层单片机的硬件逻辑来完成这些编码器计数的,避开了扫描周期问题,PLC都设计有专门的高速计数指令,使用的时候,直接调用这些指令就可以读到当前的脉冲值了。
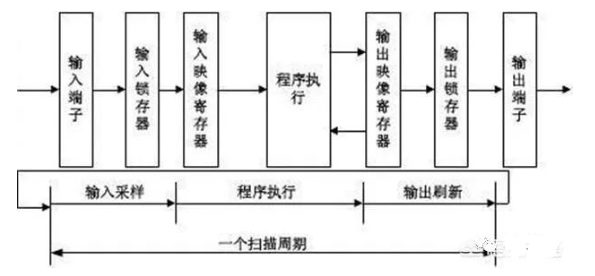
但是脉冲的计算和输出上,由于扫描周期存在,往往也会存在着滞后影响,如果用来控制一些执行机构,比如气缸来动作裁切动作,这样要考虑提前量的补偿问题。
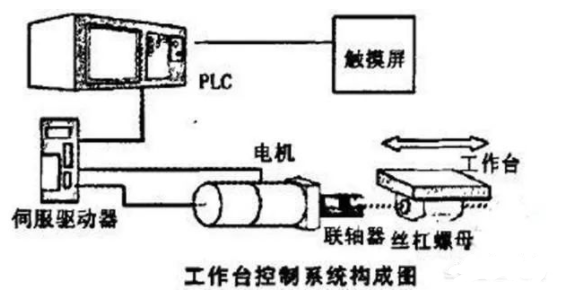
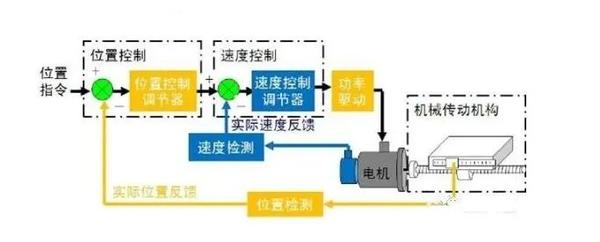
提醒一下,如果想用PLC来控制伺服或者步进系统,往往并不需要通过编码器反馈来判断位置,通过一些PLS指令之类的来发出位置脉冲给伺服驱动器,位置环在伺服驱动器内部构成就好,而PLC这边只是一个指令机构,并没有构成位置闭环,当然如果是专门定位模块控制,使用了NC之类的控制方式,是可以在里边构建位置闭环的。

















 3314
3314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









