






概述
ARM高级SIMD体系结构、相关实现和支持软件通常被称为NEON技术。AArch32(相当于ARMv7 NEON指令)和AArch64都有NEON指令集。这两种方法都可以大大加快大型数据集上的重复操作。这在音视频编解码器等应用程序中非常有用。
AArch64的NEON架构使用32×128位寄存器,是ARMv7的两倍。这些寄存器与浮点指令使用的寄存器相同。所有编译的代码和子例程都符合EABI,EABI规定了哪些寄存器可能被破坏,哪些寄存器必须保留在特定的子例程中。编译器可以在代码中的任意点自由地使用任何NEON/VFP寄存器作为浮点值或NEON数据。
所有标准ARMv8实现都需要浮点和NEON。但是,针对特定市场的实施可能支持以下组合:
- No NEON or floating-point
- 完整的浮点和SIMD支持,具有异常捕获功能
- 完全支持浮点和SIMD,无异常捕获
1、AArch64中NEON和浮点的新功能
AArch64 NEON基于现有的AArch32 NEON,有以下更改:
- 现在有32个128位寄存器,而不是适用于ARMv7的16个
- 较小的寄存器不再打包到较大的寄存器中,而是一一映射到128位寄存器的较低阶位。单精度浮点值使用低位32位,而双精度值使用128位寄存器的低位64位。参见第7-4页的NEON和浮点体系结构
- ARMv7-A NEON指令中的V前缀已被删除
- 向向量寄存器写入64位或更少的数据会导致高位归零
- 在AArch64中,没有在通用寄存器上操作的SIMD或饱和算术指令。此类操作使用NEON寄存器
- 添加了新的通道插入和提取指令,以支持新的寄存器打包方案
- 提供了用于生成或使用128位向量寄存器的前64位的附加指令。数据处理指令将生成多个结果寄存(扩展到256位向量)或使用两个源(缩小到128位向量),并被拆分为单独的指令。
- 一组新的矢量减少操作提供了across-lane sum、最小值和最大值
- 一些现有指令已扩展为支持64位整数值。例如,比较、加法、绝对值和求反,包括饱和版本
- 饱和指令已扩展为将无符号累加包含到有符号中,并将有符号累加包含到无符号累加中
- AArch64 NEON支持双精度浮点和完整IEEE754操作,包括舍入模式、非规范化数字和NaN处理
通过以下更改,AArch64中的浮点功能得到了增强:
-
ARMv7-A浮点指令中的V前缀已替换为F
-
支持IEEE 754浮点标准定义的单精度(32位)和双精度(64位)浮点向量数据类型和算法,支持FPCR舍入模式字段、默认NaN控件、刷新到零控件和(在实现支持的情况下)异常陷阱启用位
-
FP/NEON寄存器的加载/存储寻址模式与整数加载/存储相同,包括加载或存储一对浮点寄存器的能力
-
浮点FCSEL和Select与COMPAR指令,等效于已添加的整数CSEL和CCMP
-
浮点FCMP、FCMPE、FCCMP和FCCMP设置PSTATE.{N,Z,C,V}标志基于浮点比较的结果,不修改浮点状态寄存器(FPSR)中的条件标志,如ARMv7中的情况
-
所有浮点乘加和乘减指令都是融合的。
融合乘法是在VFPv4中引入的,这意味着乘法的结果在用于加法之前不会四舍五入。
在早期的ARM浮点体系结构中,乘法累加操作将执行中间结果和最终结果的舍入,这可能会导致精度的一些损失。 -
提供了额外的转换操作,例如,64位整数和浮点之间以及半精度和双精度之间的转换操作
将浮点转换为整数(FCVTxU、FCVTxS)指令对定向舍入模式进行编码:趋近于0、趋近于正无穷、趋近于负无穷、Nearest with ties to even、Nearest with ties to away -
添加了浮点格式(FRINTx)的四舍五入浮点到最接近的整数,具有相同的定向舍入模式,以及根据环境舍入模式进行舍入
-
一种新的双精度到单精度下变频指令,具有不精确舍入到奇数的功能,适用于正在进行的下变频到具有正确舍入的半精度(FCVTXN)
-
添加了FMINNM和FMAXNM指令,它们实现IEEE754-2008 minNum()和maxNum()操作。如果其中一个操作数是静态NaN,则返回数值
-
增加了加速浮点向量规范化的指令(FRECPX、FMULX)
2、NEON和浮点架构
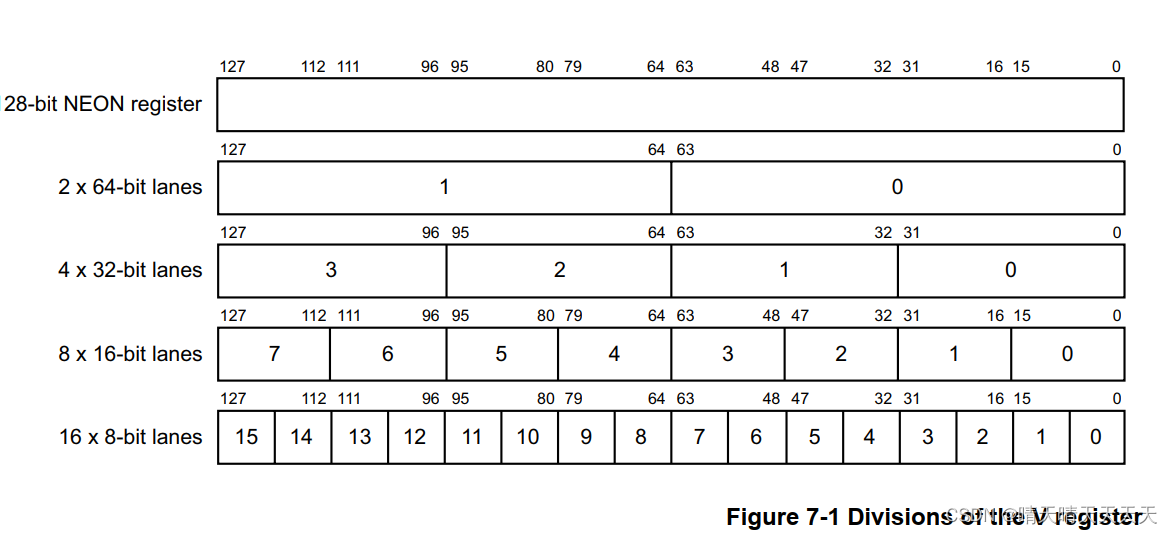
NEON寄存器的内容是相同数据类型元素的向量。矢量被划分为通道,每个通道包含一个称为元素的数据值。
NEON矢量中的通道数取决于矢量的大小和矢量中的数据元素。
通常,每个NEON指令有n个并行操作,其中n是输入向量划分的通道数。
从一条通道到另一条通道不能有进站或溢流。向量中元素的顺序是从最低有效位开始的。这意味着元素0使用寄存器的最低有效位。
NEON和浮点指令对以下类型的元素进行操作:
- 32位单精度和64位双精度浮点。支持16位浮点,但仅作为转换。数据处理操作不支持它
- 8位、16位、32位或64位无符号和有符号整数
- 8位和16位多项式
多项式类型用于使用两个有限域的幂或{0,1}上的简单多项式的代码,如纠错。普通ARM整数代码通常使用查找表进行有限域运算。AArch64 NEON提供了使用大型查找表的说明。
多项式运算很难从其他运算中合成出来,因此有一个基本的乘法运算是很有用的,从这个乘法运算可以合成其他更大的运算。
NEON装置将寄存器文件视为:
32×128位四字寄存器,V0-V31,每个寄存器如图7-1所示:
32个64位D或双字寄存器D0-D31,每个寄存器如第7-5页图7-2所示:

所有这些寄存器都可以随时访问。软件不必在它们之间显式切换,因为使用的指令决定了适当的视图。
2.1 Floating-point
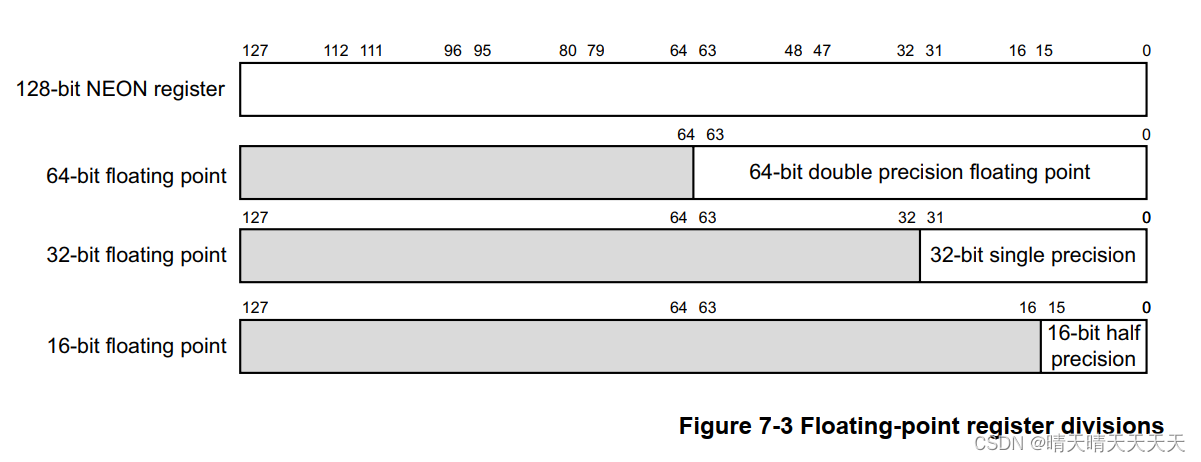
在AArch64中,浮点单元将NEON寄存器文件视为:
- 32×64位D寄存器D0-D31。D寄存器称为双精度寄存器,包含双精度浮点值
- 32×32位S寄存器S0-S31。S寄存器称为单精度寄存器,包含单精度浮点值
- 32×16位H寄存器H0-H31。H寄存器称为半精度寄存器,包含半精度浮点值
- 上述寄存器的组合
2.2 标量数据与NEON
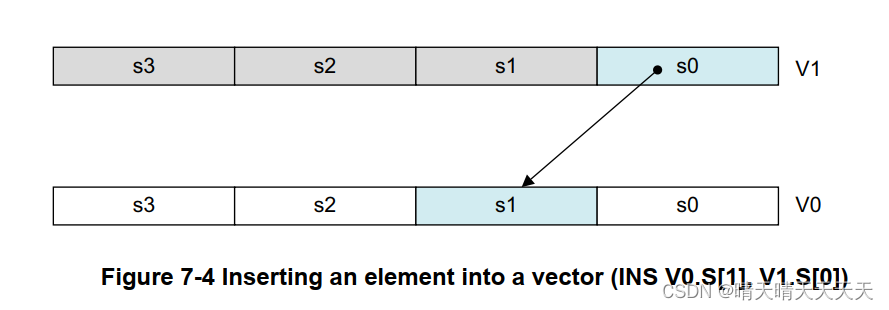
标量数据指的是单个值,而不是包含多个值的向量。有些指令使用标量操作数。寄存器中的标量通过索引进入值向量来访问。
访问向量各个元素的通用数组表示法为:
< Instruction > Vd.Ts[index1], Vn.Ts[index2]
Vd是目的寄存器
Vn是第一个源寄存器
Ts是元素大小说明符
index是元素索引
例如:INS V0.S[1], V1.S[0]
指令MOV V0.B[3],W0,将寄存器W0的最低有效字节复制到寄存器V0的第四个字节。
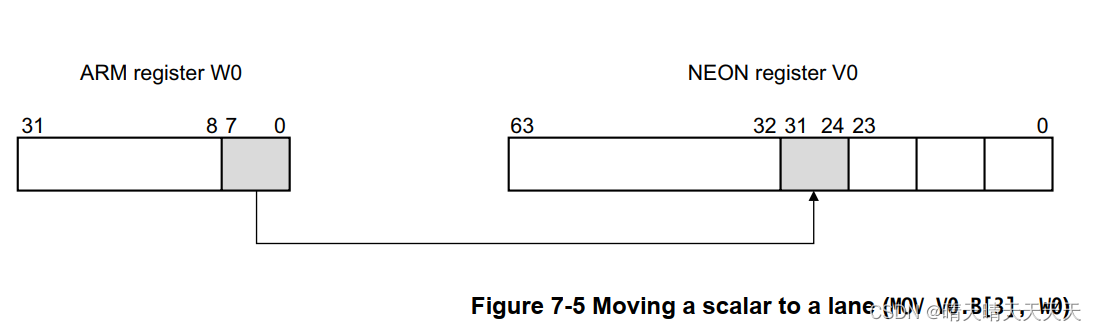
EON标量可以是8位、16位、32位或64位值。除了乘法指令,访问标量的指令可以访问寄存器文件中的任何元素。
乘法指令只允许16位或32位标量,并且只能访问寄存器文件中的前128个标量:
- 16位标量仅限于寄存器Vn.H[x],0 ≤ n ≤ 15
- 32位标量仅限于寄存器Vn.S[x]
2.3 浮点参数
使用浮点寄存器将浮点值传递给函数(并从函数返回)。整数(通用)寄存器和浮点寄存器可以同时使用。这意味着浮点参数在浮点H、S或D寄存器中传递,其他参数在整数X或W寄存器中传递。AArch64过程调用标准要求在需要浮点运算的地方使用硬件浮点,因此AArch64状态下没有软件浮点链接。
ARMv8-A体系结构参考手册中给出了详细的说明列表,但此处列出了主要的浮点数据处理操作,以说明可以执行的操作:
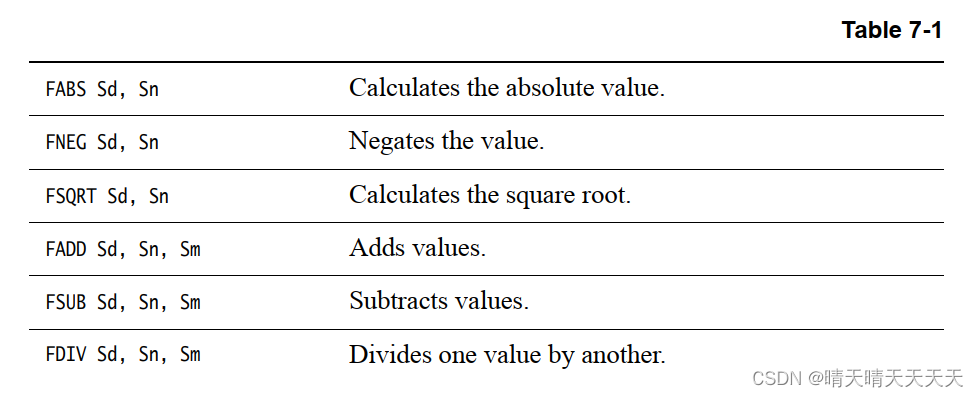
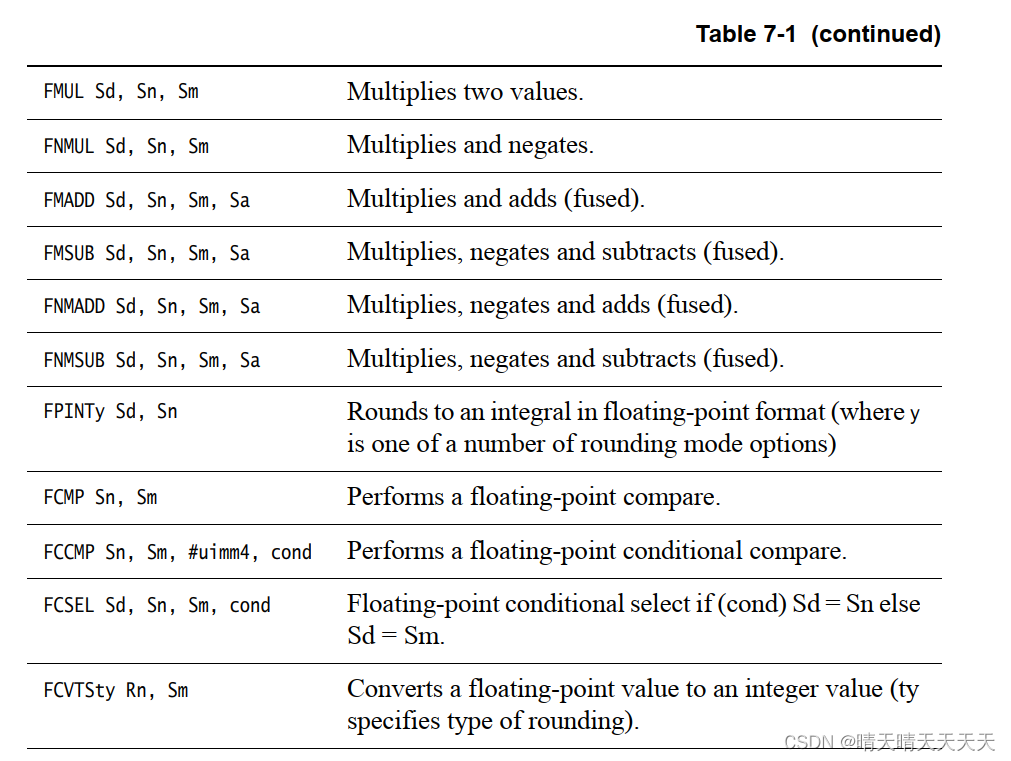
3、AArch64 NEON指令格式
NEON指令和浮点指令的语法已经做了许多更改,以与AArch64核心整数和标量浮点指令集语法相协调。指令助记符基于ARMv7。
- 已删除ARMv7 NEON指令的V前缀。
某些助记符已被重命名,其中删除V前缀导致与ARM核心指令集助记符冲突。这意味着,例如,现在有具有相同名称的指令执行相同的操作,可以是ARM核心指令、NEON指令或浮点指令,具体取决于指令的语法,例如:

- 添加了S、U、F或P前缀以指示有符号、无符号、浮点或多项式(仅其中一种)数据类型。此助记符指示操作的数据类型。例如:PMULL V0.8B, V1.8B, V2.8B
- 向量组织(元素大小和车道数)由寄存器限定符描述。例如:ADD Vd.T, Vn.T, Vm.T
其中Vd、Vn和Vm是寄存器名,T是要使用的寄存器的细分。对于本例,T是排列说明符,是8B、16B、4H、8H、2S、4S或2D中的一个。根据使用的是64位、32位、16位还是8位数据,以及使用的是寄存器的64位还是128位,可以使用其中任何一个。要添加2×64位通道,使用ADD V0.2D, V1.2D, V2.2D - 正如在ARMv7中一样,一些NEON数据处理指令有普通、长、宽、窄和饱和版本。长型、宽型和窄型变体用后缀表示:
普通指令可以对任何向量类型进行操作,并生成与操作数向量大小相同、类型通常相同的结果向量。
长指令或加长指令对双字向量操作数进行操作,并生成四字向量结果。结果元素是操作数宽度的两倍。长指令使用附加到指令的L指定。例如:SADDL V0.4S, V1.4H, V2.4H
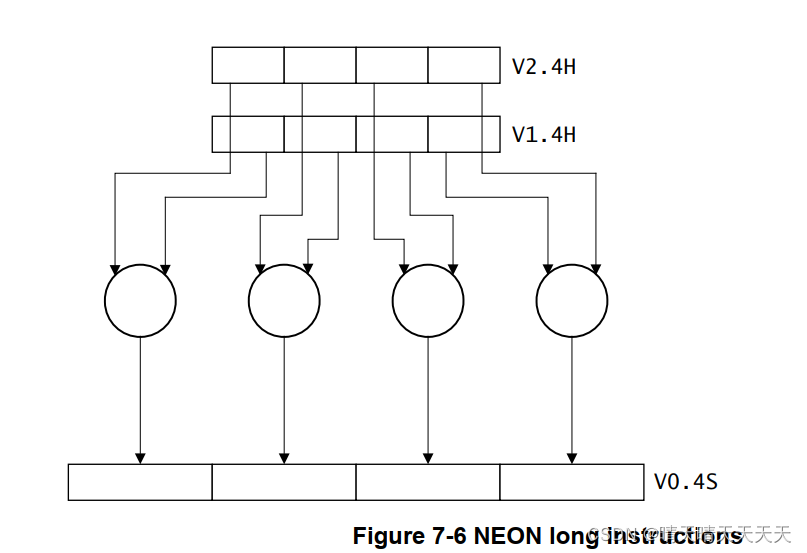
宽指令或加宽指令对双字向量操作数和四字向量操作数进行操作,生成四字向量结果。结果元素和第一个操作数的宽度是第二个操作数元素的两倍。宽指令在指令后附加了一个W。
例如:SADDW V0.4S, V1.4H, V2.4S
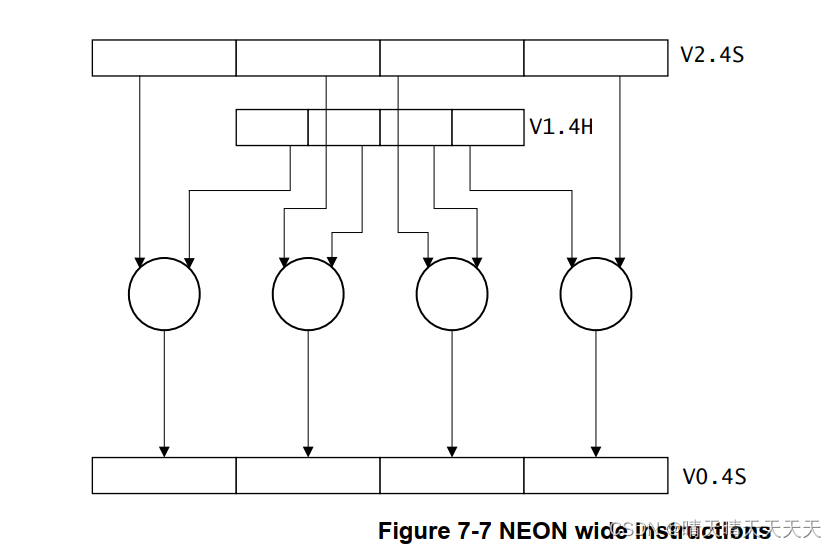
窄化或窄化指令对四字向量操作数进行操作,并生成双字向量结果。结果元素通常是操作数元素宽度的一半。窄指令是使用附加到指令的N指定的。例如:SUBHN V0.4H, V1.4S, V2.4S
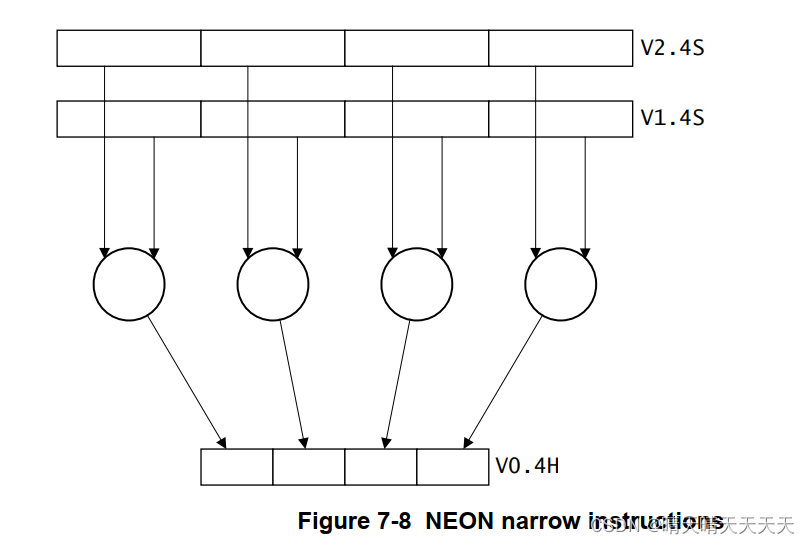
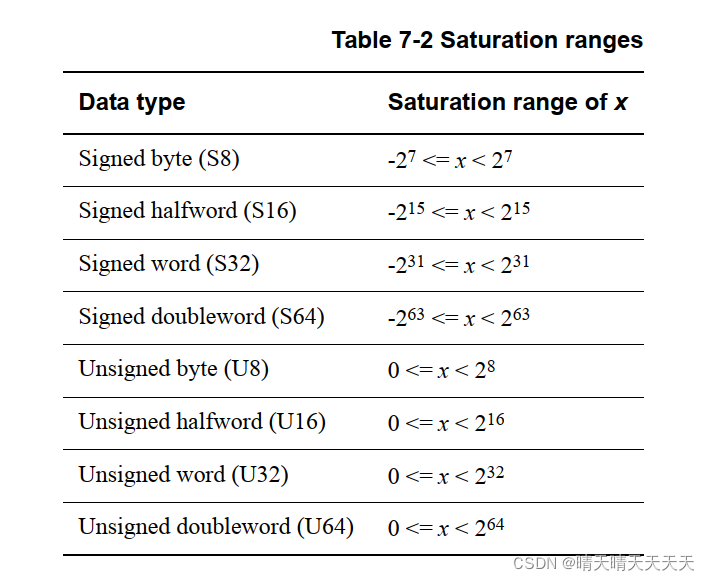
- 有符号和无符号饱和变量(由SQ或UQ前缀标识)可用于许多指令,如SQADD和UQADD。如果结果将超过数据类型的最大值或最小值,则饱和指令将返回该最大值或最小值。饱和限制取决于指令的数据类型。
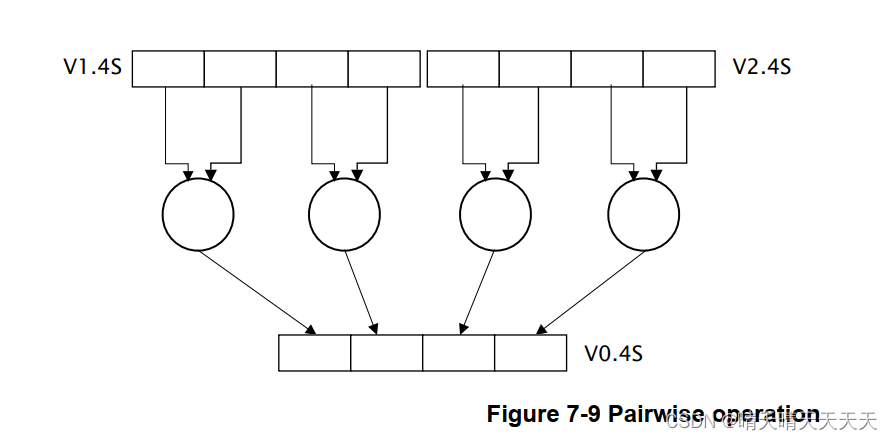
- 成对操作的ARMv7 P前缀现在是ARMv8中的后缀,例如在ADDP中。成对指令对相邻的双字或四字操作数对进行操作。例如:ADDP V0.4S, V1.4S, V2.4S
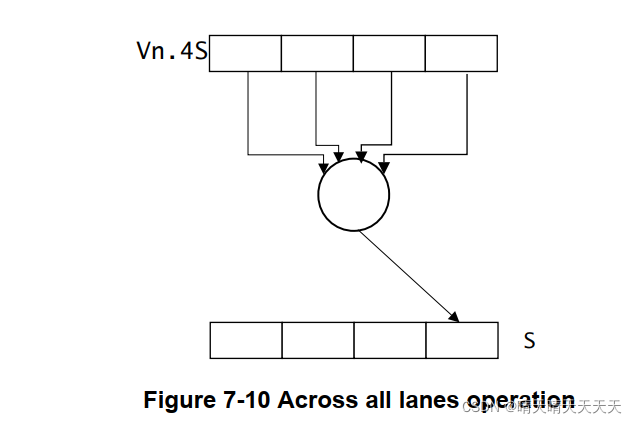
- 已为跨所有车道(整个寄存器)操作添加V后缀,例如,在ADDV中。例如:ADDV S0, V1.4S
- 为新的加宽、变窄或加长第二部分说明添加了一个2后缀,称为第二部分和上半部分说明符。如果存在,它会导致在保存较窄元素的寄存器的高64位上执行操作:
后缀为2的加宽指令从包含较窄值的向量的高位通道获取输入数据,并将扩展结果写入128位目标。例如:SADDW2 V0.2D, V1.2D, V2.4S

后缀为2的窄化指令从128位源操作数获取其输入数据,并将其窄化结果插入128位目标的高位通道,保持低位通道不变。例如:XTN2 V0.4S, V1.2D
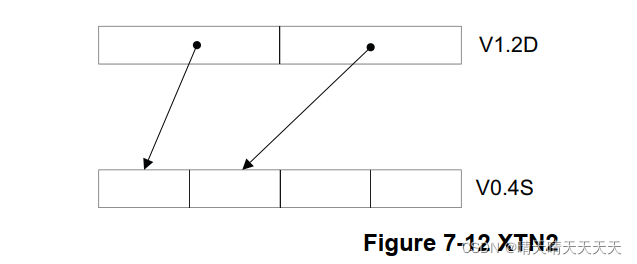
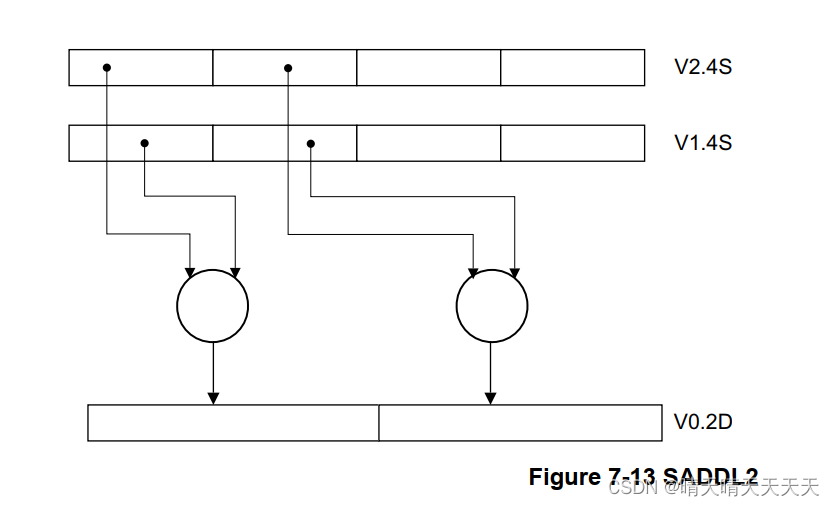
后缀为2的加长指令从128位源向量的高位通道获取输入数据,并将加长结果写入128位目标。
例如:SADDL2 V0.2D, V1.4S, V2.4S
- 比较指令现在使用条件代码名来指示条件是什么以及条件是有符号的还是无符号的(如果适用),例如,CMGT和CMHI、CMGE和CMHS。
4、可替代的NEON代码指令
NEON代码可以用多种方式编写。这里简要列出了这些代码(但有关详细信息,请参阅ARM NEON程序员指南)。这些包括使用内部函数,C代码的自动矢量化,库的使用,当然还有直接用汇编语言编写。
本质是C或C++伪函数调用,编译器用适当的NEON替换。这允许您使用NEON实现中可用的数据类型和操作,同时允许编译器处理指令调度和寄存器分配。这些内部函数在ARMC语言扩展文档中定义。
自动矢量化由ARM编译器6中的-fvectorize选项控制,但在更高的优化级别(-O2及以上)时自动启用。即使指定了-fvectorize,自动矢量化也会在-O0处禁用。因此,您可以使用以下命令在-O1启用自动矢量化:armclang --target=armv8a-arm-none-eabi -fvectorize -O1 -c file.c
有各种库可以使用NEON代码。这些库的确切状态会随着时间的推移而变化,因此本指南不包括当前的支持。
尽管在技术上可以手动优化NEON组装,但这可能非常困难,因为管道和内存访问计时具有复杂的相互依赖性。ARM强烈建议使用Intrinsic,而不是直接使用汇编:
- 使用instrinsic编写代码比使用汇编助记符更容易
- instrinsic为跨平台开发提供了良好的可移植性
- 无需担心管道和内存访问时间
- 对于大多数情况,性能较好
如果您不是一个有经验的汇编语言程序员,内部语言通常可以比汇编语言获得更好的性能。
内部函数提供的功能几乎与编写汇编语言一样多,但将寄存器的分配交给编译器,这样您就可以专注于算法部分。这比使用汇编语言更易于维护源代码。
Intrinsics是使用C语言的方式对NEON寄存器进行操作,因为相比于传统的使用纯汇编语言,具有可读性强,开发速度快等优势
如果需要在代码中调用NEON Intrinsics函数,需要加入头文件"arm_neon.h"。关于neon的所有函数,可以参考官网

















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









