







 博客描述了作者在使用MongoDB进行数据查询时遇到的卡顿问题,尤其是在使用DBCursor时每6000多条数据会出现长时间卡顿。问题可能是由于内存管理不当,尽管数据量不大,但内存映射可能导致性能问题。作者尝试每10000条数据开启和关闭DBCursor以减少内存泄露,但这并未解决问题。MongoDB的内存占用持续上升,表明数据在连接开启时被保留在内存中。文章探讨了MongoDB的内存映射机制、journal的影响以及可能的查询优化策略。
博客描述了作者在使用MongoDB进行数据查询时遇到的卡顿问题,尤其是在使用DBCursor时每6000多条数据会出现长时间卡顿。问题可能是由于内存管理不当,尽管数据量不大,但内存映射可能导致性能问题。作者尝试每10000条数据开启和关闭DBCursor以减少内存泄露,但这并未解决问题。MongoDB的内存占用持续上升,表明数据在连接开启时被保留在内存中。文章探讨了MongoDB的内存映射机制、journal的影响以及可能的查询优化策略。
这两天从Remote MongoDB读数据的时候遇到了一个很奇葩的问题,就是使用DBCursor读数据的时候每六千多条就卡顿很久,这个六千多是一个固定的数。然后是58w的数据每次到20w putty终端就会卡死,然后MongoDB也会退出。虽然到现在问题还没解决,但是先把资料做一下汇总,看能不能有所帮助。
阿里云服务器只有1G内存,但是数据大概也只有320M。
首先从这个链接http://huoding.com/2011/08/19/107看到一些MongoDB内存的基本介绍,可知MongoDB使用的是内存映射存储引擎,具体就是MMap,MongoDB采用操作系统底层提供的内存文件映射(MMap)的方式来实现对数据库记录文件的访问,MMAP可以把磁盘文件的全部内容直接映射到进程的内存空间,这样文件中的每条数据记录就会在内存中有对应的地址,这时对文件的读写可以直接通过操作内存来完成。同时操作的是虚拟内存,所以最好人为控制一下数据量,最好小于物理内存,否则可能会有性能问题。
MongoDB的工作基本上都是在内存完成的,这也是它高性能的原因之一,特别是插入的时候,在java中实例化Mongo客户端插入重复 _id 数据会迅速的被重写就是因为操作是在内存中完成,MongoClient则修改了这一机制,插入重复_id会抛出异常。我在查询的时候使用了skip,但据说skip也是要一条一条数过去。
自带的mongostat工具可以监控内存占用情况,下面是截取的一部分
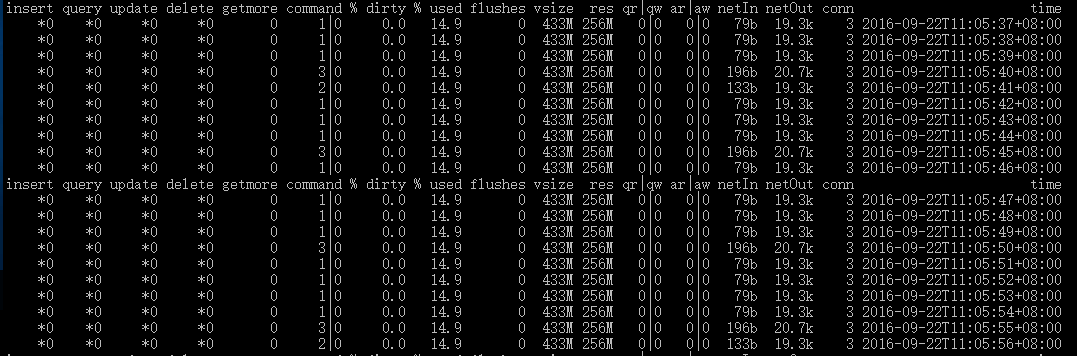
visz
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









