







文章目录
Dubbo3核心源码
Dubbo是和ServiceComb中Java-Chassis并驾齐驱的RPC框架实现,简化微服务之间的相互调用,在设计架构中总是出奇的相似,优秀的开源框架,总是在实现理念上如出一辙,ServiceComb请参考上一篇博文。
- 面向职责链接口编程,中间预留众多可扩展的接口,支持内部模块和第三方模块动态扩展框架功能。
- 事件总线模块,解耦内部模块起到非常大的作用,在关键点总会发送出事件出来撒。
- 定制的SPI动态加载机制,支持使能、优先级、初始化、生命周期,灵活的动态扩展功能。
- 通过文本文件(yaml或属性文件)动态编排类的能力,更加灵活的组合功能模块。
- 未完待续
Consumer到Provicer整体流程
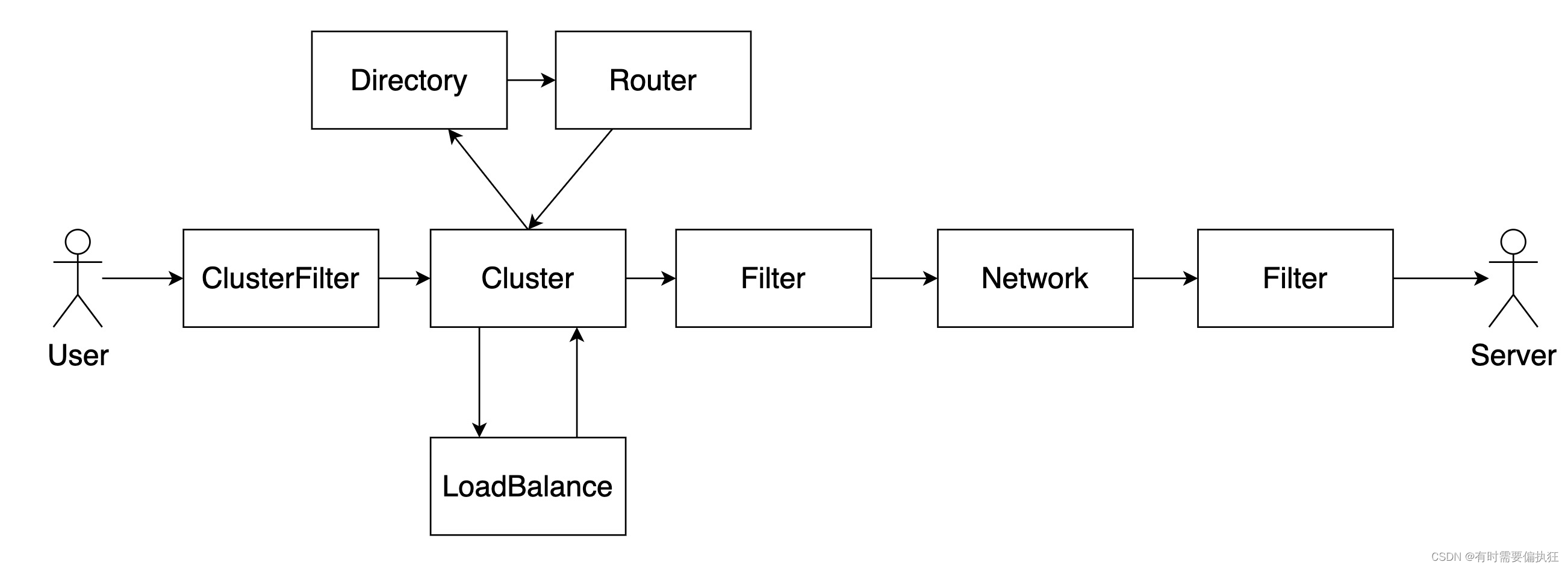
如上图所示,从服务调用的角度来看,Dubbo 在链路中提供了丰富的扩展点,覆盖了负载均衡方式、选址前后的拦截器、服务端处理拦截器等。
简单来说 Dubbo 发起远程调用的时候,主要工作流程可以分为消费端和服务端两个部分。
消费端的工作流程如下:
- 通过 Stub 接收来自用户的请求,并且封装在
Invocation对象中 - 将
Invocation对象传递给ClusterFilter(扩展点)做选址前的请求预处理,如请求参数的转换、请求日志记录、限流等操作都是在此阶段进行的 - 将
Invocation对象传递给Cluster(扩展点)进行集群调用逻辑的决策,如快速失败模式、安全失败模式等决策都是在此阶段进行的Cluster调用Directory获取所有可用的服务端地址信息Directory调用StateRouter(扩展点,推荐使用) 和Router(扩展点) 对服务端的地址信息进行路由筛选,此阶段主要是从全量的地址信息中筛选出本次调用允许调用到的目标,如基于打标的流量路由就是在此阶段进行的Cluster获得从Directory提供的可用服务端信息后,会调用LoadBalance(扩展点)从多个地址中选择出一个本次调用的目标,如随机调用、轮询调用、一致性哈希等策略都是在此阶段进行的Cluster获得目标的Invoker以后将Invocation传递给对应的Invoker,并等待返回结果,如果出现报错则执行对应的决策(如快速失败、安全失败等)
- 经过上面的处理,得到了带有目标地址信息的
Invoker,会再调用Filter(扩展点)进行选址后的请求处理(由于在消费端侧创建的Filter数量级和服务端地址量级一致,如无特殊需要建议使用ClusterFilter进行扩展拦截,以提高性能) - 最后
Invocation会被通过网络发送给服务端
服务端的工作流程如下:
- 服务端通信层收到请求以后,会将请求传递给协议层构建出
Invocation - 将
Invocation对象传递给Filter(扩展点)做服务端请求的预处理,如服务端鉴权、日志记录、限流等操作都是在此阶段进行的 - 将
Invocation对象传递给动态代理做真实的服务端调用
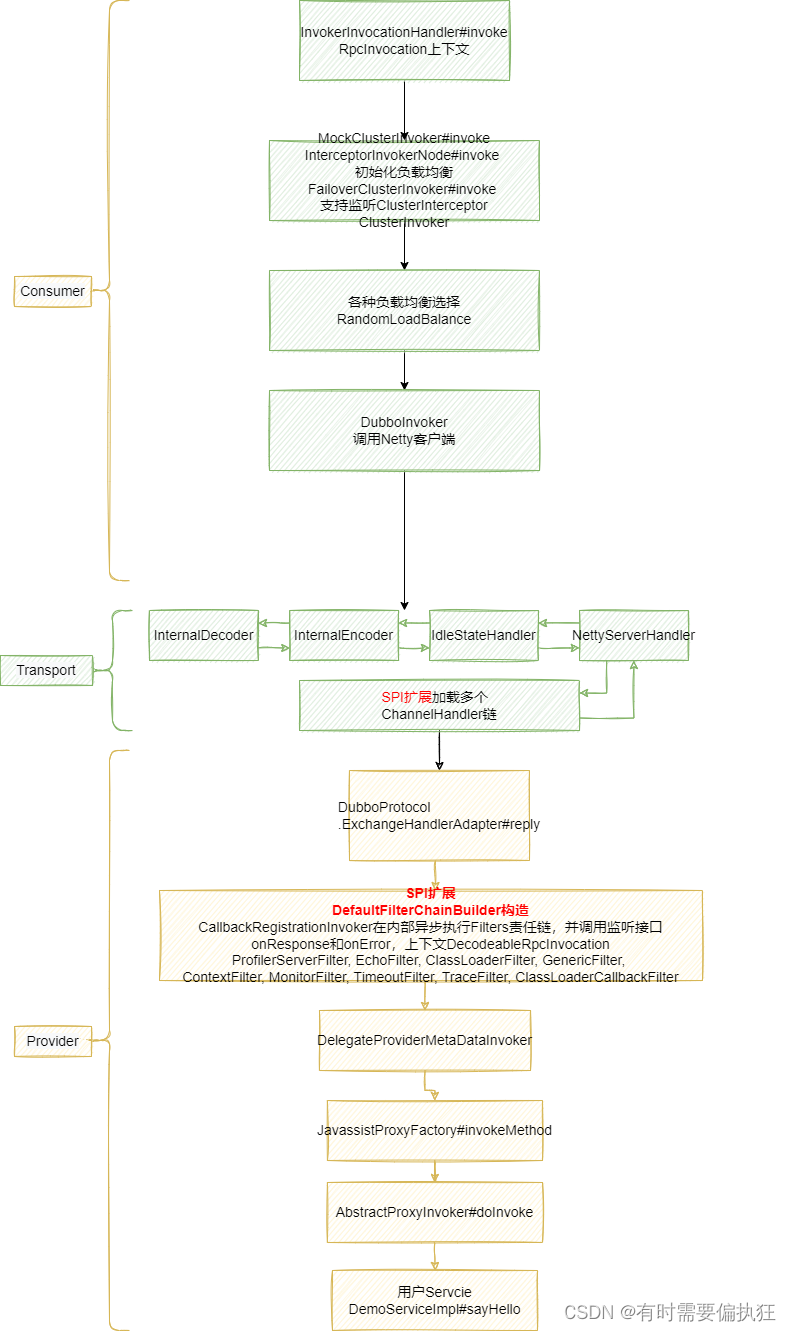
SPI扩展机制
Dubbo扩展理念
-
可扩展性是一种设计理念,代表了我们对未来的一种预想,我们希望在现有的架构或设计基础上,当未来某些方面发生变化的时候,我们能够以最小的改动来适应这种变化。
-
可扩展性的优点主要表现模块之间解耦,它符合开闭原则,对扩展开放,对修改关闭。当系统增加新功能时,不需要对现有系统的结构和代码进行修改,仅仅新增一个扩展即可。
-
一般来说,系统会采用 Factory、IoC、OSGI 等方式管理扩展(插件)生命周期。考虑到 Dubbo 的适用面,不想强依赖 Spring 等 IoC 容器。 而自己造一个小的 IoC 容器,也觉得有点过度设计,所以选择最简单的 Factory 方式管理扩展(插件)。在 Dubbo 中,所有内部实现和第三方实现都是平等的
-
扩展点只封装一个变化因子(单个接口),最大化复用。每个扩展点的实现者,往往都只是关心一件事。如果用户有需求需要进行扩展,那么只需要对其关注的扩展点进行扩展就好,极大的减少用户的工作量
Dubbo扩展特点
Dubbo 中的扩展能力是从 JDK 标准的 SPI 扩展点发现机制加强而来,它改进了 JDK 标准的 SPI 以下问题:
- JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
- 如果扩展点加载失败,连扩展点的名称都拿不到了。比如:JDK 标准的 ScriptEngine,通过 getName() 获取脚本类型的名称,但如果 RubyScriptEngine 因为所依赖的 jruby.jar 不存在,导致 RubyScriptEngine 类加载失败,这个失败原因被吃掉了,和 ruby 对应不起来,当用户执行 ruby 脚本时,会报不支持 ruby,而不是真正失败的原因。
用户能够基于 Dubbo 提供的扩展能力,很方便基于自身需求扩展其他协议、过滤器、路由等。下面介绍下 Dubbo 扩展能力的特性。
- 按需加载。Dubbo 的扩展能力不会一次性实例化所有实现,而是用扩展类实例化,减少资源浪费。
- 增加扩展类的 IOC 能力。Dubbo 的扩展能力并不仅仅只是发现扩展服务实现类,而是在此基础上更进一步,如果该扩展类的属性依赖其他对象,则 Dubbo 会自动的完成该依赖对象的注入功能。
- 增加扩展类的 AOP 能力。Dubbo 扩展能力会自动的发现扩展类的包装类,完成包装类的构造,增强扩展类的功能。
- 具备动态选择扩展实现的能力。Dubbo 扩展会基于参数,在运行时动态选择对应的扩展类,提高了 Dubbo 的扩展能力。
- 可以对扩展实现进行排序。能够基于用户需求,指定扩展实现的执行顺序。
- 提供扩展点的 Adaptive 能力。该能力可以使的一些扩展类在 consumer 端生效,一些扩展类在 provider 端生效。
扩展实现
Dubbo实现SPI加载机制比Java自带的SPI功能更加完善包括了IOC和AOP的功能在里面。
- 读取特定目录下的配置文件,然后解析出全类名,通过反射机制来实例化这个类,然后将这个类放在集合中存起来。
- 实现类了IOC和 AOP 的功能。
- IOC在构造完扩展类,会从
SpiExtensionFactory/SpringExtensionFactory获取依赖,并调用其setter方法进行属性注入。 - AOP 指的是什么了?这个说的是 Dubbo 能够为扩展类注入其包装类。比如 DubboProtocol 是 Protocol 的扩展类,ProtocolListenerWrapper 是 DubboProtocol 的包装类。
- IOC在构造完扩展类,会从
// 1、SPI接口
@SPI
public interface DemoSpi {
void say();
}
// 2、实现类
public class DemoSpiImpl implements DemoSpi {
public void say() {
}
}
// 3、配置文件名为接口全路径,内容为kv的形式,k为扩展名,v为实现全类名
demoSpiImpl = com.xxx.xxx.DemoSpiImpl(为 DemoSpi 接口实现类的全类名)
// 4、使用 获取Loader并获取名字的扩展点
ExtensionLoader<DemoSpi> extensionLoader = ExtensionLoader.getExtensionLoader(DemoSpi.class);
DemoSpi dmeoSpi = extensionLoader.getExtension("demoSpiImpl");
- 从Loader中获取扩展的,简单来说如果
ConcurrentHashMap有则直接返回,否则从资源文件中加载全部的是放入Map映射表。
public T getExtension(String name) {
if (name == null || name.length() == 0)
throw new IllegalArgumentException("Extension name == null");
if ("true".equals(name)) {
// 获取默认的拓展实现类
return getDefaultExtension();
}
// Holder,顾名思义,用于持有目标对象
Holder<Object> holder = cachedInstances.get(name);
// 这段逻辑保证了只有一个线程能够创建 Holder 对象
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<Object>());
holder = cachedInstances.get(name);
}
Object instance = holder.get();
// 双重检查
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
// 创建拓展实例
instance = createExtension(name);
// 设置实例到 holder 中
holder.set(instance);
}
}
}
return (T) instance;
}
private T createExtension(String name, boolean wrap) {
// 从配置文件中加载所有的拓展类,可得到“配置项名称”到“配置类”的映射关系表
Class<?> clazz = getExtensionClasses().get(name);
// 如果没有该接口的扩展,或者该接口的实现类不允许重复但实际上重复了,直接抛出异常
if (clazz == null || unacceptableExceptions.contains(name)) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
// 这段代码保证了扩展类只会被构造一次,也就是单例的.
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.getDeclaredConstructor().newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 向实例中注入依赖
injectExtension(instance);
// 如果启用包装的话,则自动为进行包装.
// 比如我基于 Protocol 定义了 DubboProtocol 的扩展,但实际上在 Dubbo 中不是直接使用的 DubboProtocol, 而是其包装类
// ProtocolListenerWrapper
if (wrap) {
List<Class<?>> wrapperClassesList = new ArrayList<>();
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
// 循环创建 Wrapper 实例
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
for (Class<?> wrapperClass : wrapperClassesList) {
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
if (wrapper == null
|| (ArrayUtils.contains(wrapper.matches(), name) && !ArrayUtils.contains(wrapper.mismatches(), name))) {
// 将当前 instance 作为参数传给 Wrapper 的构造方法,并通过反射创建 Wrapper 实例。
// 然后向 Wrapper 实例中注入依赖,最后将 Wrapper 实例再次赋值给 instance 变量
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
}
}
// 初始化
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}
-
如何控制某些类带有生命周期/排序/销毁?从实现的接口就可以看出这个类要做什么事情,接口就是类功能的抽象,功能分类将每个类要对外暴露的功能点抽象。
定义排序和生命周期的接口,控制中心在操作这些类的时候,探测是否有实现这两个接口,然后面向接口的编程对这些类排序及初始化,这是一种模板的设计模式,实质上就是面向接口编程,将类的功能点做抽象分类,并以接口的形式承载,如何炉火纯清的使用设计模式?
这个策略在Tomcat/Spring里面都有很多实现。
// component支持销毁资源的功能
public interface Disposable {
void destroy();
}
// component支持生命周期的功能
public interface Lifecycle extends Disposable {
/**
* Initialize the component before {@link #start() start}
*
* @return current {@link Lifecycle}
* @throws IllegalStateException
*/
void initialize() throws IllegalStateException;
/**
* Start the component
*
* @return current {@link Lifecycle}
* @throws IllegalStateException
*/
void start() throws IllegalStateException;
/**
* Destroy the component
*
* @throws IllegalStateException
*/
void destroy() throws IllegalStateException;
}
// 优先级排序的功能,one和two对比的方式这里值得学习
public interface Prioritized extends Comparable<Prioritized> {
Comparator<Object> COMPARATOR = (one, two) -> {
boolean b1 = one instanceof Prioritized;
boolean b2 = two instanceof Prioritized;
if (b1 && !b2) { // one is Prioritized, two is not
return -1;
} else if (b2 && !b1) { // two is Prioritized, one is not
return 1;
} else if (b1 && b2) { // one and two both are Prioritized
return ((Prioritized) one).compareTo((Prioritized) two);
} else { // no different
return 0;
}
};
int MAX_PRIORITY = Integer.MIN_VALUE;
int MIN_PRIORITY = Integer.MAX_VALUE;
int NORMAL_PRIORITY = 0;
default int getPriority() {
return NORMAL_PRIORITY;
}
@Override
default int compareTo(Prioritized that) {
return compare(this.getPriority(), that.getPriority());
}
}
Filter(拦截器)
拦截器可以实现服务提供方和服务消费方调用过程拦截,Dubbo 本身的大多功能均基于此扩展点实现,每次远程方法执行,该拦截都会被执行,请注意对性能的影响。
其中在消费端侧,ClusterFilter 用于选址前的拦截和 Filter 用于选址后的拦截。如无特殊需要使用 ClusterFilter 进行扩展拦截,以提高性能。

在 Dubbo 3 中,Filter 和 ClusterFilter 的接口签名被统一抽象到 BaseFilter 中,开发者可以分别实现 Filter 或 ClusterFilter 的接口来实现自己的拦截器。
如果需要拦截返回状态,可以直接实现 BaseFilter.Listener 的接口,Dubbo 将自动识别,并进行调用。
package org.apache.dubbo.rpc;
public interface BaseFilter {
Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException;
interface Listener {
void onResponse(Result appResponse, Invoker<?> invoker, Invocation invocation);
void onError(Throwable t, Invoker<?> invoker, Invocation invocation);
}
}
package org.apache.dubbo.rpc;
@SPI(scope = ExtensionScope.MODULE)
public interface Filter extends BaseFilter {
}
package org.apache.dubbo.rpc.cluster.filter;
@SPI(scope = ExtensionScope.MODULE)
public interface ClusterFilter extends BaseFilter {
}
特别的,如果需要在 Consumer 侧生效 Filter 或 ClusterFilter,需要增加 @Activate 注解,并且需要指定 group 的值为 consumer。
@Activate(group = CommonConstants.CONSUMER)
如果需要在 Provider 侧生效 Filter 或 ClusterFilter,需要增加 @Activate 注解,并且需要指定 group 的值为 provider。
@Activate(group = CommonConstants.PROVIDER)
具体调用拦截扩展方式请参考
Router(路由选址)
路由选址提供从多个服务提供方中选择一批满足条件的目标提供方进行调用的能力。
Dubbo 的路由主要需要实现 3 个接口,分别是负责每次调用筛选的 route 方法,负责地址推送后缓存的 notify 方法,以及销毁路由的 stop 方法。
在 Dubbo 3 中推荐实现 StateRouter 接口,能够提供高性能的路由选址方式。
package org.apache.dubbo.rpc.cluster.router.state;
public interface StateRouter<T> {
BitList<Invoker<T>> route(BitList<Invoker<T>> invokers, URL url, Invocation invocation,
boolean needToPrintMessage, Holder<RouterSnapshotNode<T>> nodeHolder) throws RpcException;
void notify(BitList<Invoker<T>> invokers);
void stop();
}
package org.apache.dubbo.rpc.cluster;
public interface Router extends Comparable<Router> {
@Deprecated
List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
<T> RouterResult<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation,
boolean needToPrintMessage) throws RpcException;
<T> void notify(List<Invoker<T>> invokers);
void stop();
}
具体路由选址扩展方式请参考
Cluster(集群规则)
集群规则提供在有多个服务提供方时进行结果聚合、容错等能力。
package org.apache.dubbo.rpc.cluster.support;
public abstract class AbstractClusterInvoker<T> implements ClusterInvoker<T> {
protected abstract Result doInvoke(Invocation invocation, List<Invoker<T>> invokers,
LoadBalance loadbalance) throws RpcException;
}
具体集群规则扩展方式请参考
LoadBalance(负载均衡)
从多个服务提供方中选择一个目标提供方进行调用的能力,Invocation是控制中心的上下文Contex实例,最重载的实例类,职责链的实现必备此。
常用的第三方负载均衡软件有Nginx、LVS、HAProxy,专门在应用层做负载均衡。
业务内部简单的负载均衡算法有:
-
普通随机
-
带权重的随机算法:权重大被选中的机会多,用于后端服务器性能不均的情况
假设我们有一组服务器 servers = [A, B, C]
他们对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上。
[0, 5) 区间属于服务器 A
[5, 8) 区间属于服务器 B
[8, 10) 区间属于服务器 C。
接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字3会落到服务器 A 对应的区间上,此时返回服务器 A 即可。权重越大的机器,在坐标轴上对应的区间范围就越大,因此随机数生成器生成的数字就会有更大的概率落到此区间内。只要随机数生成器产生的随机数分布性很好,在经过多次选择后,每个服务器被选中的次数比例接近其权重比例。比如,经过一万次选择后,服务器 A 被选中的次数大约为5000次,服务器 B 被选中的次数约为3000次,服务器 C 被选中的次数约为2000次。
-
轮询
-
带权重的轮询:权重大分配的被选中的机会多
我们有三台服务器 A、B、C。我们将第一个请求分配给服务器 A,第二个请求分配给服务器 B,第三个请求分配给服务器 C,第四个请求再次分配给服务器 A。这个过程就叫做轮询。轮询是一种无状态负载均衡算法,实现简单,适用于每台服务器性能相近的场景下。但现实情况下,我们并不能保证每台服务器性能均相近。如果我们将等量的请求分配给性能较差的服务器,这显然是不合理的。因此,这个时候我们需要对轮询过程进行加权,以调控每台服务器的负载。经过加权后,每台服务器能够得到的请求数比例,接近或等于他们的权重比。比如服务器 A、B、C 权重比为 5:2:1。那么在8次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的2次请求,服务器 C 则收到其中的1次请求。
-
一致性Hash:节点压力均摊,基本可以减少单点的压力
首先根据 ip 或者其他的信息生成一个 hash,并将这个hash投射到 [0, 2^32 - 1]的Hash圆环上。当请求过来,则通过Hash请求生成一个hash值。然后在环上查找第一个大于或等于该hash值的节点来处理请求,并且同一个处理节点可以在环上Hash多个虚拟节点,用于解决单点问题。
-
最小活跃数:活跃数调用数量越小,被选中的机会越大,在Consumer端用HashMap记录每个Provider的methed对于此Consumer的活跃数。
活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求。此时应优先将请求分配给该服务提供者。在具体实现中,每个服务提供者对应一个活跃数 active。初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最小活跃数负载均衡算法的基本思想。除了最小活跃数,LeastActiveLoadBalance 在实现上还引入了权重值。所以准确的来说,**LeastActiveLoadBalance 是基于加权最小活跃数算法实现的。**举个例子说明一下,在一个服务提供者集群中,有两个性能优异的服务提供者。某一时刻它们的活跃数相同,此时 Dubbo 会根据它们的权重去分配请求,权重越大,获取到新请求的概率就越大。如果两个服务提供者权重相同,此时随机选择一个即可。
-
最短响应:后端服务器的响应时间来分配请求,响应时间短的优先分配
public class TestLoader {
private static List<String> list = Arrays.asList("A", "B", "C");
private static List<Integer> weight = Arrays.asList(5, 1, 1);
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
System.out.println(smoothWeightRoundRobin());
}
}
// 随机
public static String randomLoadBalance() {
ThreadLocalRandom random = ThreadLocalRandom.current();
return list.get(random.nextInt(list.size()));
}
// 带权重的随机
public static String weightRandomLoadBalance() {
// 权重对应关系如下,只需要计算随机数落在哪个区间
// [0,5) -> ip-1
// [5,7) -> ip-2
long total = weight.stream().count();
ThreadLocalRandom random = ThreadLocalRandom.current();
// 找出随机值落在的区间
int nextInt = random.nextInt((int) total);
for (int index = 0; index < weight.size(); index++) {
if (nextInt <= weight.get(index)) {
return list.get(index);
}
nextInt -= weight.get(index);
}
return list.get(ThreadLocalRandom.current().nextInt(list.size())); // 输入权重不合理
}
// 轮询
private static Integer count = 0;
public static String roundRobin() {
return list.get(Math.abs(count++) % list.size());
}
// 带权重的轮询,A的能力更强权重给大,但是对A的操作过于集中
// servers = [A, B, C]
// weight = [5, 1, 1]
// -> A A A A A B C
public static String weightRoundRobin() {
long total = weight.stream().count(); // 总权重
int current = (Math.abs(count++) % list.size()); // 当前轮询的值
for (int index = 0; index < weight.size(); index++) { // 找到区间
if (current <= weight.get(index)) {
return list.get(index);
}
current -= weight.get(index);
}
return list.get(ThreadLocalRandom.current().nextInt(list.size())); // 兜底则随机选择
}
// 平滑带权重的轮询 参考Nginx,A的能力更强权重给大,并将一轮的操作打散
// current都为0,每一轮迭代都和原始相加,并从current中找出最大的index,并将最大的减去总权重,继续下一轮迭代
// servers = [A, B, C]
// weight = [5, 1, 1]
// -> A A B A C A A
static int[] orgWeight = new int[]{5, 1, 1};
static int[] currentWeight = new int[]{0, 0, 0};
public static String smoothWeightRoundRobin() {
// 1、和原始求和
int sum = Arrays.stream(orgWeight).sum();
int maxIndex = 0;
int max = 0;
for (int index = 0; index < orgWeight.length; index++) {
currentWeight[index] += orgWeight[index];
if (currentWeight[index] > max) {
max = currentWeight[index];
maxIndex = index;
}
}
currentWeight[maxIndex] -= sum;
return list.get(maxIndex);
}
}
Dubbo扩展实现
package org.apache.dubbo.rpc.cluster;
public interface LoadBalance {
@Adaptive("loadbalance")// 会根据URL参数自动选择负载均衡的方式,invokers-Provider提供列表,Invocation上下文
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}
-
AbstractLoadBalance抽象的实现类,将公共Function继续抽象,如基于select又抽象了一个doSelect的抽象方法供子类实现。
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) { if (CollectionUtils.isEmpty(invokers)) { return null; } if (invokers.size() == 1) { return invokers.get(0); } return doSelect(invokers, url, invocation); }支持获取单个invoker的权重,通过invoker的三个传参计算得出来
static int calculateWarmupWeight(int uptime, int warmup, int weight) { int ww = (int) ( uptime / ((float) warmup / weight)); return ww < 1 ? 1 : (Math.min(ww, weight)); }















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











