








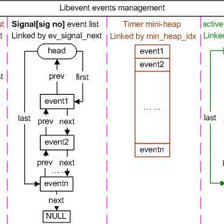
在Libevent中,用到了双向链表和小根堆,双向链表直接使用的linux内核里面的queue.h。对于信号事件、IO事件以及就绪事件全部都是通过双向链表连接在一起,对于定时器事件则通过小根堆连接在一起,所以理解着两种数据结构是分析后续代码的关键。
1、tail queue
下面头文件定义了双向链表的关键性操作。双向链表的实现和平常自己实现的不太一样,一般实现就是一个节点里面除了存放自定义数据外,还存放两个指针,一个可以指向下一个节点,一个指向上一个节点。但是这里存放的两个指针有点不同,一个指向下一个节点,另外一个指向下一个节点的某一个成员变量。下面是宏定义的双向链表全部操作。
/*
* Tail queue definitions.
*/
#define TAILQ_HEAD(name, type) \
struct name { \
struct type *tqh_first; /* first element */ \
struct type **tqh_last; /* addr of last next element */ \
}//头结点宏定义
#define TAILQ_HEAD_INITIALIZER(head) \
{ NULL, &(head).tqh_first }//头结点初始化
#define TAILQ_ENTRY(type) \
struct { \
struct type *tqe_next; /* next element */ \
struct type **tqe_prev; /* address of previous next element */ \
}//结点中存放地址的变量
/*
* tail queue access methods
*/
#define TAILQ_FIRST(head) ((head)->tqh_first)
#define TAILQ_END(head) NULL
#define TAILQ_NEXT(elm, field) ((elm)->field.tqe_next)
#define TAILQ_LAST(head, headname) \
(*(((struct headname *)((head)->tqh_last))->tqh_last))
/* XXX */
#define TAILQ_PREV(elm, headname, field) \
(*(((struct headname *)((elm)->field.tqe_prev))->tqh_last))
#define TAILQ_EMPTY(head) \
(TAILQ_FIRST(head) == TAILQ_END(head))
#define TAILQ_FOREACH(var, head, field) \
for((var) = TAILQ_FIRST(head); \
(var) != TAILQ_END(head); \
(var) = TAILQ_NEXT(var, field))
#define TAILQ_FOREACH_REVERSE(var, head, headname, field) \
for((var) = TAILQ_LAST(head, headname); \
(var) != TAILQ_END(head); \
(var) = TAILQ_PREV(var, headname, field))
/*
* Tail queue functions.
*/
#define TAILQ_INIT(head) do { \
(head)->tqh_first = NULL; \
(head)->tqh_last = &(head)->tqh_first; \
} while (0)
#define TAILQ_INSERT_HEAD(head, elm, field) do { \
if (((elm)->field.tqe_next = (head)->tqh_first) != NULL) \
(head)->tqh_first->field.tqe_prev = \
&(elm)->field.tqe_next; \
else \
(head)->tqh_last = &(elm)->field.tqe_next; \
(head)->tqh_first = (elm); \
(elm)->field.tqe_prev = &(head)->tqh_first; \
} while (0)
#define TAILQ_INSERT_TAIL(head, elm, field) do { \
(elm)->field.tqe_next = NULL; \
(elm)->field.tqe_prev = (head)->tqh_last; \
*(head)->tqh_last = (elm); \
(head)->tqh_last = &(elm)->field.tqe_next; \
} while (0)
#define TAILQ_INSERT_AFTER(head, listelm, elm, field) do { \
if (((elm)->field.tqe_next = (listelm)->field.tqe_next) != NULL)\
(elm)->field.tqe_next->field.tqe_prev = \
&(elm)->field.tqe_next; \
else \
(head)->tqh_last = &(elm)->field.tqe_next; \
(listelm)->field.tqe_next = (elm); \
(elm)->field.tqe_prev = &(listelm)->field.tqe_next; \
} while (0)
#define TAILQ_INSERT_BEFORE(listelm, elm, field) do { \
(elm)->field.tqe_prev = (listelm)->field.tqe_prev; \
(elm)->field.tqe_next = (listelm); \
*(listelm)->field.tqe_prev = (elm); \
(listelm)->field.tqe_prev = &(elm)->field.tqe_next; \
} while (0)
#define TAILQ_REMOVE(head, elm, field) do { \
if (((elm)->field.tqe_next) != NULL) \
(elm)->field.tqe_next->field.tqe_prev = \
(elm)->field.tqe_prev; \
else \
(head)->tqh_last = (elm)->field.tqe_prev; \
*(elm)->field.tqe_prev = (elm)->field.tqe_next; \
} while (0)
#define TAILQ_REPLACE(head, elm, elm2, field) do { \
if (((elm2)->field.tqe_next = (elm)->field.tqe_next) != NULL) \
(elm2)->field.tqe_next->field.tqe_prev = \
&(elm2)->field.tqe_next; \
else \
(head)->tqh_last = &(elm2)->field.tqe_next; \
(elm2)->field.tqe_prev = (elm)->field.tqe_prev; \
*(elm2)->field.tqe_prev = (elm2); \
} while (0)分析一个例子
仅仅看上面的代码可能有点绕,暂时先看一个使用上面头文件的例子:
#include "queue.h"
#include <stdio.h>
#include <stdlib.h>
struct QUEUE_ITEM{//首先定义节点结构体
int value;
TAILQ_ENTRY(QUEUE_ITEM) entries;
};
TAILQ_HEAD(QUEUE_HEAD,QUEUE_ITEM);//然后定义头结点结构体
int main(int argc,char **argv){
struct QUEUE_HEAD queue_head;//定义头结点
struct QUEUE_ITEM *New_Item;
TAILQ_INIT(&queue_head);//初始化头结点,后面就可以插入和删除元素进入双向链表了
for(int i = 0 ; i < 10 ; i += 2){
New_Item = (QUEUE_ITEM *)malloc(sizeof(struct QUEUE_ITEM));//分配节点
New_Item->value = i;
TAILQ_INSERT_TAIL(&queue_head, New_Item, entries);//插入链表尾部
}
struct QUEUE_ITEM *Temp_Item;
Temp_Item = (QUEUE_ITEM *)malloc(sizeof(struct QUEUE_ITEM));//在分配一个节点
Temp_Item->value = 100;
TAILQ_INSERT_BEFORE(New_Item,Temp_Item,entries);//插入尾部节点之前
Temp_Item = TAILQ_FIRST(&queue_head);//取出第一个节点
printf("first element is %d\n",Temp_Item->value);
Temp_Item = TAILQ_NEXT(Temp_Item,entries);//下一个节点
printf("next element is %d\n",Temp_Item->value);
Temp_Item = TAILQ_NEXT(Temp_Item,entries);//下一个节点
printf("next element is %d\n",Temp_Item->value);
Temp_Item = TAILQ_NEXT(Temp_Item , entries);//下一个节点
printf("next element is %d\n",Temp_Item->value);
Temp_Item = TAILQ_PREV(Temp_Item , QUEUE_HEAD, entries);//前一个节点
printf("prev element is %d\n",Temp_Item->value);
}首先将上述宏定义展开可以得到节点以及头结点结构体定义:并且注意头结点struct QUEUE_HEAD里面数据成员类型以及内存布局和struct QUEUE_ITEM里面的entries成员变量相一致,全部都是struct QUEUE_ITEM类型的指针。
struct QUEUE_ITEM{//首先定义节点结构体
int value;//自定义数据
struct {
struct QUEUE_ITEM *tqe_next;
struct QUEUE_ITEM **tqe_prev;
} entries;//指针变量
};
struct QUEUE_HEAD{
struct QUEUE_ITEM *tqh_first;
struct QUEUE_ITEM **tqh_last;
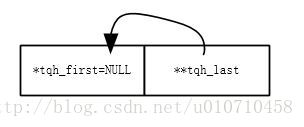
}1、经过了TAILQ_INIT(&queue_head);之后双向链表头结点初始化的布局如下:
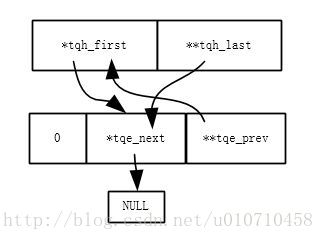
2、插入一个节点之后,双向链表链接如下,其中可以看出tpe_prev始终指向前一个节点的tpe_next成员即保存tpe_next的地址,所以tpe_prev是指针的指针变量,因为tpe_next是一个指针。
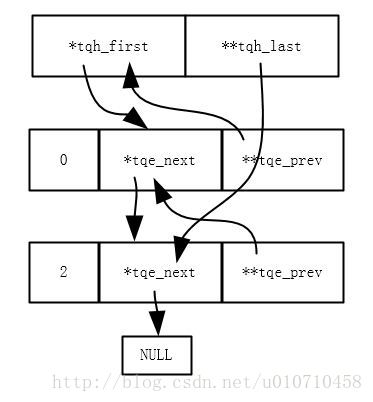
3、再次插入一个节点之后,双向链表如下,结合宏定义很容易看清楚。
4、再次插入一个节点之后,双向链表如下。
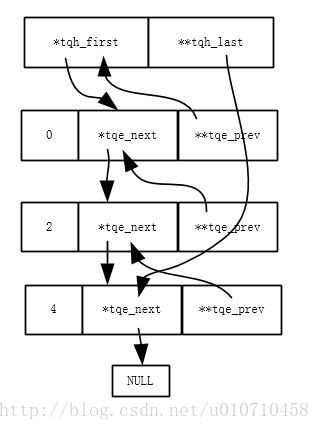
分析宏定义
记住前面链表的结构过程,那么分析下面的宏定义很容易。
1、TAILQ_INSERT_TAIL
#define TAILQ_INSERT_TAIL(head, elm, field) do { \
(elm)->field.tqe_next = NULL; \
(elm)->field.tqe_prev = (head)->tqh_last; \
*(head)->tqh_last = (elm); \
(head)->tqh_last = &(elm)->field.tqe_next; \
} while (0)从尾部插入成员,首先将新成员的tqe_next指向空。通过(head)->tqh_last可以获取原链表最后节点的tqe_next的地址,然后将新成员tqe_prev指向上一个节点的tqe_next。然后通过(head)->tqh_last将原链表最后节点的tqe_next指向新节点,最后将(head)->tqh_last指向新节点的tqe_next成员,方便后续继续插入新的节点。这个过程描述起来优点复杂,但是结合上面的图很容易理解。
2、TAILQ_PREV
这个宏定义是最难理解的地方,双向链表的优点在于,可以从后面的节点知道前面节点的地址,可是这里后面节点存放的是前面节点某个成员变量(tqe_next)的地址,而不是节点的首地址,这里就有一个问题,如何通过结构体的某个成员地址,获取结构体的地址?方法主要有两种,第一可以通过求得成员变量在整个结构体中的偏移地址,然后就可以获得结构体的地址;第二通过地址强制进行转换以及内存布局一样来获取地址。这里就是通过第二种方法获取。通过上面例子中的TAILQ_PREV调用讲解。
假如Temp_Item是前面含有成员变量为4的节点的首地址,那么这个宏定义可以分为下面4个步骤:
- 1、通过
Temp_Item->entries.tqe_prev获取前一个节点的tqe_next地址。 - 2、
(struct QUEUE_HEAD*)( Temp_Item->entries.tqe_prev ),然后将此地址强制转换成struct QUEUE_HEAD *类型,这里必须注意的是struct QUEUE_HEAD里面的成员内存布局和Temp_Item->entries里面内存布局一样。其二不论是指针的指针还是指针全部都是存储在内存上面的数据而已,类型只是为了告诉编译器取数据从首地址开始取多少字节截止。例如在32位机器上面,指针变量占用4字节。 - 3、
( (struct QUEUE_HEAD *)( Temp_Item->entries.tqe_prev )->tqh_last )可以获取Temp_Item的前一个节点(含有值2的节点)的tqe_prev成员变量的值,并且类型是struct QUEUE_ITEM *。 - 4、
*( (struct QUEUE_HEAD *)( Temp_Item->entries.tqe_prev )->tqh_last )取出了含有值为0的成员的tqe_next的值,刚刚这个成员变量指向2号节点,那么就取出了2号节点的首地址,可以通过首地址访问。
#define TAILQ_PREV(elm, headname, field) \
(*( ( (struct headname *)( (elm)->field.tqe_prev) )->tqh_last))
Temp_Item = TAILQ_PREV(Temp_Item , QUEUE_HEAD, entries);第二种方法的讲解可以参考这里的第三点,也是内核里面实现的一种方法。
3、TAILQ_LAST
这个宏定义和前面的类似,分析过程一样,重点在于理解指针以及指针的类型。告诉编译器如何组织对应的内存即可。
#define TAILQ_LAST(head, headname) \
(*(((struct headname *)((head)->tqh_last))->tqh_last))
/* XXX */2、min_heap
简单介绍
堆一般通过数组实现,数组对应的索引,表示完全二叉树对应的顶点。所以堆是可以表示成一颗完全二叉树。最大堆就是父节点的值总是大于等于子节点,也就是第一个节点永远是最大值;最小堆就是父节点的值总是小于等于子节点,第一个节点用于是最小值。一个最小堆如下图:
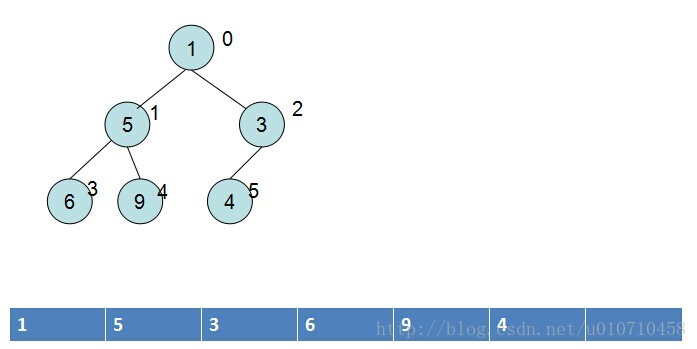
上图圆圈旁边的数字代表其在数组中的下标。堆一般是用数组来存储的,也就是说实际存储结构是连续的,只是逻辑上是一棵树的结构。这样做的好处是很容易找到堆顶的元素,对Libevent来说,很容易就可以找到距当前时间最近的timeout事件。
现在想想看我们要插入一个元素,我们要怎么移动数组中元素的位置,使其逻辑上仍然是一个小堆?结合下图很容易看出来:
1、假设我们要插入的元素为6大于其父节点的值2。则把元素放在数组相应的index上,插入完成。
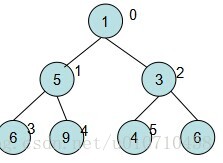
2、假设我们要插入的为2小于其父节点的值3。则交换该节点与其父节点的值。对于下图来说,交换完毕后插入就算完成了。那要是交换完后发现index=2的元素还小于其父节点index=0的呢?就又得在一次交换,如此循环,直到达到根节点或是其不大于父节点。
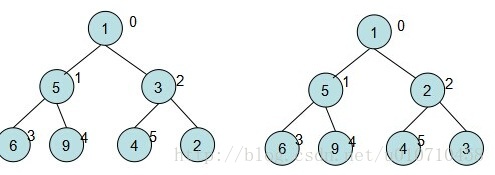
3、假如我们要取出堆中的最小值,那么只需要取出index=0出的数值,如下返回最小元素。
libevent实现
typedef struct min_heap
{
struct event** p;//动态连续内存指针
unsigned n, a;//n表示堆中元素的个数,a表示使用的空间
} min_heap_t;上述是堆结构体定义,后面通过动态分配连续内存完成最小堆。
1、下沉操作
此操作就是将在hole_index位置上面的e元素,下沉到满足最小堆定义合适的位置。通常在取出最小元素的时候使用。
void min_heap_shift_down_(min_heap_t* s, unsigned hole_index, struct event* e)//下沉操作,将位于hole_index的e节点下沉
{
unsigned min_child = 2 * (hole_index + 1);
while(min_child <= s->n)
{
//找出较小子节点index
min_child -= min_child == s->n || min_heap_elem_greater(s->p[min_child], s->p[min_child - 1]);
//e比 较小的子节点还小,达到边界条件可跳出循序
if(!(min_heap_elem_greater(e, s->p[min_child])))
break;
//e比较小的子节点大,则更好位置
(s->p[hole_index] = s->p[min_child])->min_heap_idx = hole_index;
hole_index = min_child;//继续比较
min_child = 2 * (hole_index + 1);
}
min_heap_shift_up_(s, hole_index, e);
}2、上浮操作
此操作就是将在hole_index位置上面的e元素,上浮到满足最小堆定义合适的位置。通常在插入元素的时候使用。
void min_heap_shift_up_(min_heap_t* s, unsigned hole_index, struct event* e)//上浮操作,将位于hole_index的e节点上浮合适位置
{
unsigned parent = (hole_index - 1) / 2;//找出父节点
while(hole_index && min_heap_elem_greater(s->p[parent], e))//父节点大于子节点就循环。
{
(s->p[hole_index] = s->p[parent])->min_heap_idx = hole_index;//将父节点下移交换位置
hole_index = parent;//下一次迭代
parent = (hole_index - 1) / 2;
}
(s->p[hole_index] = e)->min_heap_idx = hole_index;//最后将e放到合适的位置
}3、堆空间调整
因为此处堆空间是动态分配的,所以在插入元素需要通过realloc重新分配内存空间即可。刚开始
int min_heap_reserve(min_heap_t* s, unsigned n)//堆空间调整
{
if(s->a < n)
{
struct event** p;
unsigned a = s->a ? s->a * 2 : 8;
if(a < n)
a = n;
if(!(p = (struct event**)realloc(s->p, a * sizeof *p)))
return -1;
s->p = p;
s->a = a;
}
return 0;
}3、最小堆插入元素
结合上面的两个函数,实现起来超级简单,首先扩容,然后将位于n位置的元素e上浮到合适的位置即可。
int min_heap_push(min_heap_t* s, struct event* e)//从尾部插入成员,并将成员上浮至合适位置
{
if(min_heap_reserve(s, s->n + 1))//先扩容
return -1;
min_heap_shift_up_(s, s->n++, e);//插入
return 0;
}4、最小堆弹出元素
超级简单,相当于就是存储最小堆index为0的节点值,然后索引为0的节点和索引末尾的节点位置交换使末尾节点成为头结点,然后将头节点下沉到合适的位置即可。在libevent实现过程中,没有进行交换,直接将0位置的末尾节点下沉,相当于交换了。
struct event* min_heap_pop(min_heap_t* s)//从头部弹出成员,并下沉到合适位置。
{
if(s->n)
{
struct event* e = *s->p;//取出第一个成员。
min_heap_shift_down_(s, 0u, s->p[--s->n]);//将最后元素放在0位置,并且下沉到其他合适的位置。
e->min_heap_idx = -1;//事件e此时已经不在堆中,索引标记为-1。
return e;//返回事件e的指针。
}
return 0;
}5、总结
堆这种结构在逻辑上的这种二叉树的关系,其插入也好,删除也好,就是一个与父节点或是子节点比较然后调整位置,这一过程循环往复直到达到边界条件的过程。记住这一点,就不难写出代码了。在这里因为使用了索引0,所以二叉树节点i的父节点为(i-1)/2。子节点为2i+1和2(i+1)。并且在libevent中,一个定时器事件仅仅需要记录两个数值即可,一个是在最小堆中的索引min_heap_idx,另外一个是在最小堆比较的时间数值ev_timeout。
3、max_heap
最大堆的实现和最小堆有异曲同工之处,关于最大堆的实现请参考博客之堆排序,比libevent里面实现简单也比它容易理解
















 7449
7449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











