







这一章节中有两个概念让我很受教:
依赖反转:让模块间解耦,增加系统的独立部署能力
事件溯源:我们可以不借助临时变量,通过记录系统历史变化,进行回溯历史的当前、历史状态。
1- 依赖反转--面向对象编程
刚开始读这一小节的时候,一头雾水,等到读第二遍的时候,突然顿悟。感觉这种设计思想很好。不仅适用于面向对象编程,对于C的面向过程编程也有用到(内核的分层设计)。
这种依赖反转的最大好处是:上层和底层解耦,任何一个模块变动都不会影响另一个模块,可以独立部署。
摘抄文字如下:
程序应该与设备无关。这个经验从何而来呢?因为一度所有程序都是设备相关的,但是后来我们发现自己其实真正需要的是在不同的设备上实现同样的功能。
例如,我们曾经写过一些程序,需要从卡片盒中的打孔卡片读取数据,同时要通过在新的卡片上打孔来输出数据。后来,客户不再使用打孔卡片,而开始使用磁带卷了。这就给我们带来了很多麻烦,很多程序都需要重写。于是我们就会想,如果这段程序可以同时操作打孔卡片和磁带那该多好。
插件式架构就是为了支持这种 IO 不相关性而发明的,它几乎在随后的所有系统中都有应用。但即使多态有如此多优点,大部分程序员还是没有将插件特性引入他们自己的程序中,因为函数指针实在是太危险了。
而面向对象编程的出现使得这种插件式架构可以在任何地方被安全地使用。
众多源代码依赖关系都可以通过引入接口的方式来进行反转。
通过这种方法,软件架构师可以完全控制采用了面向对象这种编程方式的系统中所有的源代码依赖关系,而不再受到系统控制流的限制。不管哪个模块调用或者被调用,软件架构师都可以随意更改源代码依赖关系。
这就是面向对象编程的好处,同时也是面向对象编程这种范式的核心本质至少对一个软件架构师来说是这样的。
这种能力有什么用呢?在下面的例子中,我们可以用它来让数据库模块和用户界面模块都依赖于业务逻辑模块(见图 5.3),而非相反。
原始的架构设计如下图:

采用这种方式,上层UI和数据库操作依赖于业务,如果业务变化,UI和数据库相关代码将无法复用。
通过增加抽象层,进行依赖反转
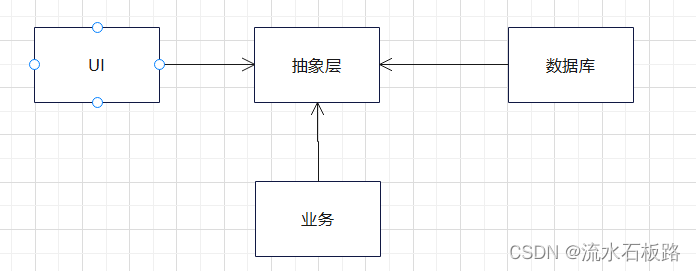
采用这种方式,UI和数据库对于业务的依赖转为对于抽象层的依赖,就算业务模型变化,只要我们规定了业务和抽象层的接口,UI和数据库功能模块仍可以复用。
例如linux驱动中,不论是串口设备、led设备还是键盘设备,都有file_operation结构体,这个结构体是业务层(驱动层)和抽象层(系统调用层)约定好的接口。就算底层设备改变,我们上层一个用函数都可以通过open打开设别,read接口读写设备。
这意味着我们让用户界面和数据库都成为业务逻辑的插件。也就是说,业务逻辑模块的源代码不需要引入用户界面和数据库这两个模块。
这样一来,业务逻辑、用户界面以及数据库就可以被编译成三个独立的组件或者部署单元(例如 jar 文件、DLL 文件、Gem 文件等)了,这些组件或者部署单元的依赖关系与源代码的依赖关系是一致的,业务逻辑组件也不会依赖于用户界面和数据库这两个组件。
于是,业务逻辑组件就可以独立于用户界面和数据库来进行部署了,我们对用户界面或者数据库的修改将不会对业务逻辑产生任何影响,这些组件都可以被分另独立地部署。
简单来说,当某个组件的源代码需要修改时,仅仅需要重新部署该组件,不需要更改其他组件,这就是独立部署能力。
如果系统中的所有组件都可以独立部署,那它们就可以由不同的团队并行开发,这就是所谓的独立开发能力。
面向对象编程到底是什么?业界在这个问题上存在着很多不同的说法和意见。然而对一个软件架构师来说,其含义应该是非常明确的:面向对象编程就是以对象为手段来对源代码中的依赖关系进行控制的能力,这种能力让软件架构师可以构建出某种插件式架构,让高层策略性组件与底层实现性组件相分离,底层组件可必编译成插件,实现独立于高层组件的开发和部署。
2- 事件溯源--函数式编程
读书中的下段文字时,直接让我卧槽。
为什么不可变性是软件架构设计需要考虑的重点呢?为什么软件架构帅要操心变量的可变性呢?答案显而易见:所有的竞争问题、死锁问题、并发更新问题都是由可变变量导致的。如果变量永远不会被更改,那就不可能产生竞争或者并发更新问题。如果锁状态是不可变的,那就永远不会产生死锁问题。
软件架构师应该着力于将大部分处理逻辑都归于不可变组件中,可变状态组件的逻辑应该越少越好。
假设某个银行应用程序需要维护客户账户余额信息,当它放行存取款事务时,就要同时负责修改余额记录。
如果我们不保存具体账户余额,仅仅保存事务日志,那么当有人想查询账户余额时。我们就将全部交易记录取出,并且每次都得从最开始到当下进行累计。当然,这样的设计就不需要维护任何可变变量了。
但显而易见,这种实现是有些不合理的。因为随着时间的推移,事务的数目会无限制增长,每次处理总额所需要的处理能力很快就会变得不能接受。如果想使这种设计永远可行的话,我们将需要无限容量的存储,以及无限的处理能力。
但是可能我们并不需要这个设计永远可行,而且可能在整个程序的生命周期内,我们有足够的存储和处理能力来满足它。
这就是事件溯源,在这种体系下,我们只存储事务记录,不存储具体状态。当需要具体状态时,我们只要从头开始计算所有的事务即可。
在存储方面,这种架构的确需要很大的存储容量。如今离线数据存储器的增长是非常快的,现在 1 TB 对我们来说也已经不算什么了。
更重要的是,这种数据存储模式中不存在删除和更新的情况,我们的应用程序不是 CRUD,而是 CR。因为更新和删除这两种操作都不存在了,自然也就不存在并发问题。
如果我们有足够大的存储量和处理能力,应用程序就可以用完全不可变的、纯函数式的方式来编程。
如果读者还是觉得这听起来不太靠谱,可以想想我们现在用的源代码管理程序,它们正是用这种方式工作的!















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









