







流分析
Event Time 和 Watermarks
介绍
flink支持三种时间语义:
- 事件时间:事件发生的时间,由产生(或存储)事件的设备记录
- 摄入时间:Flink在摄取事件时所记录的时间戳
- 处理时间:管道中的特定操作符处理事件的时间
对于可重现的结果,例如,当计算股票在某一天交易的第一个小时内达到的最高价格时,您应该使用事件时间。这样,结果就不依赖于何时执行计算。这种实时应用程序有时使用处理时间来执行,但结果是由在该小时内碰巧处理的事件决定的,而不是当时发生的事件。基于处理时间的计算分析导致不一致,并使重新分析历史数据或测试新实现变得困难。
处理事件时间
如果要使用事件时间,还需要提供时间戳提取器和水印生成器,Flink将使用它们来跟踪事件时间的进度。这将在下面的使用水印一节中讨论,但首先我们应该解释什么是水印。
水印又称水位线
让我们通过一个简单的例子来说明为什么需要水印,以及它们是如何工作的。
在这个示例中,您有一个带时间戳的事件流,这些事件到达的顺序有些混乱,如下所示。显示的数字是时间戳,表示这些事件实际发生的时间。到达的第一个事件发生在时间4,紧随其后的是发生在时间2更早的事件,依此类推:
··· 23 19 22 24 21 14 17 13 12 15 9 11 7 2 4 →
现在假设您正在尝试创建一个流排序器。这意味着应用程序将处理来自流的每个事件,并发出包含相同事件的新流,但按照它们的时间戳排序。
一些观察:
(1)你的流排序器看到的第一个元素是4,但你不能立即释放它作为排序流的第一个元素。它可能已经出现了故障,更早的事件可能还会出现。事实上,您已经对流的未来有了一定的了解,并且您可以看到您的流排序器应该至少等到2出现时才产生可能的结果。
一些缓冲和延迟是必要的。
(2)如果你做错了,你可能会永远等下去。首先,排序器看到时间4的事件,然后是时间2的事件。时间戳小于2的事件会出现吗?也许吧。也许不是。你可以一直等,永远看不到1。
最终你必须勇敢地将2作为排序流的开始。
(3)然后,您需要某种类型的策略,定义对于任何给定的时间戳事件,何时停止等待早期事件的到来。
这正是水印的作用——它们定义何时停止等待早期事件。
Flink中的事件时间处理依赖于在流中插入特殊时间标记元素(称为水印)的水印生成器。时间t的水印是流(可能)现在通过时间t完成的断言。
这个流排序器什么时候应该停止等待,并推出2来启动排序流?当水印的时间戳大于等于2时。
(4)您可能会设想不同的策略来决定如何生成水印。
每个事件都有一定的延迟,而这些延迟各不相同,因此有些事件的延迟比其他事件更严重。一种简单的方法是假设这些延迟受某个最大延迟的限制。Flink将这种策略称为有界无序水印。我们很容易想象更复杂的水印方法,但对于大多数应用来说,固定的延迟就足够了。
延迟和完整性
另一种考虑水印的方式是,它们为流应用程序的开发人员提供了在延迟和完整性之间进行权衡的控制。与批处理不同的是,在批处理中,在产生任何结果之前,可以拥有输入的完整知识,而使用流处理时,您最终必须停止等待,以看到更多的输入,并产生某种结果。
您可以通过短的有界延迟积极地配置您的水印,从而冒着在输入信息相当不完整的情况下产生结果的风险——例如,一个可能是错误的结果,但很快就产生了。或者您可以等待更长的时间,并产生利用对输入流有更完整知识的结果。
还可以实现快速生成初始结果的混合解决方案,然后在处理额外(后期)数据时提供对这些结果的更新。对于某些应用程序来说,这是一种很好的方法。
延迟
延迟是相对于水印定义的。水印(t)断言流在时间t之前是完整的;在该水印之后的任何时间戳≤t的事件都是迟到的。
使用水印
为了执行基于事件时间的事件处理,Flink需要知道与每个事件相关的时间,它还需要流包含水印。
实践练习中使用的Taxi数据源会为您处理这些细节。但是在您自己的应用程序中,您必须自己处理这个问题,这通常是通过实现一个类来完成的,这个类从事件中提取时间戳,并根据需要生成水印。最简单的方法是使用WatermarkStrategy:
DataStream<Event> stream = ...;
WatermarkStrategy<Event> strategy = WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withTimestampAssigner((event, timestamp) -> event.timestamp);
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(strategy);
窗口
Flink具有非常富有表现力的窗口语义。
本节,需要关注以下三点:
- 如何使用窗口计算未绑定流上的聚合
- Flink支持哪种类型的窗口
- 以及如何使用窗口聚合实现DataStream程序
介绍
当进行流处理时,很自然地想要对流的有限子集计算聚合分析,以便回答这样的问题:
- 每分钟的页面浏览数
- 每用户每周的会话数
- 每分钟的最高温度每个传感器
使用Flink计算窗口分析依赖于两个主要的抽象:将事件分配给窗口的窗口赋值器(根据需要创建新的窗口对象),以及应用于分配给窗口的事件的窗口函数。
Flink的窗口API还有触发器的概念,触发器决定何时调用窗口函数,而剔除器可以删除收集在窗口中的元素。
在它的基本形式中,你像这样对键控流应用窗口:
stream.
.keyBy(<key selector>)
.window(<window assigner>)
.reduce|aggregate|process(<window function>);
你也可以对非键流使用窗口,但要记住,在这种情况下,处理将不会并行完成:
stream.
.windowAll(<window assigner>)
.reduce|aggregate|process(<window function>);
Window Assigners
Flink有几种内置的窗口分配器,如下图所示:
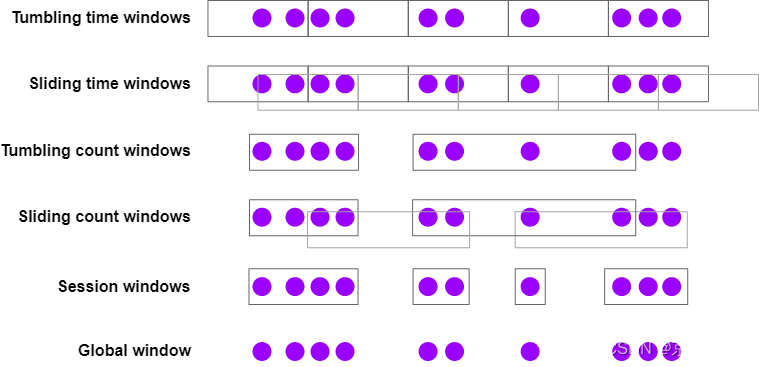
下面是一些窗口分配器的使用示例,以及如何指定它们:
- Tumbling time windows
- 每分钟浏览量
- TumblingEventTimeWindows.of(Time.minutes(1))
- Sliding time windows
- 每10秒计算一分钟的页面浏览量
- SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10))
- Session windows
- 每个会话的页面浏览量,会话之间的间隔至少为30分钟
- EventTimeSessionWindows.withGap(Time.minutes(30))
持续时间可以是Time.milliseconds(n)、Time.seconds(n)、Time.minutes(n)、Time.hours(n)和Time.days(n)中的任意一个。
基于时间的窗口分配器(包括会话窗口)分为事件时间和处理时间两种。这两种时间窗口之间存在显著的权衡。随着处理时间窗口,你必须接受以下限制:
- 不能正确处理历史数据,
- 不能正确处理乱序数据,
- 结果会不确定,
但有了低延迟的优势。
在处理基于计数的窗口时,请记住,这些窗口直到批处理完成后才会触发。没有超时和处理部分窗口的选项,但您可以使用自定义Trigger自己实现该行为。
全局窗口赋值器将每个事件(具有相同的键)分配给同一个全局窗口。只有当您要使用自定义触发器创建自定义窗口时,这才有用。在许多情况下,这可能看起来很有用,你最好使用另一节中描述的ProcessFunction。
窗口函数
对于如何处理窗口内容,有三个基本选项:
- 作为批处理,使用ProcessWindowFunction传递一个包含窗口内容的可迭代对象;
- 当每个事件被分配给窗口时,调用ReduceFunction或AggregateFunction;
- 或者两者结合使用,当窗口被触发时,ReduceFunction或AggregateFunction的预聚合结果被提供给ProcessWindowFunction。
下面是方法1和方法3的例子。每个实现在1分钟的事件时间窗口内从每个传感器找到峰值,并生成包含(key, end- window-timestamp, max_value)的元组流。
ProcessWindowFunction Example
DataStream<SensorReading> input = ...;
input
.keyBy(x -> x.key)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.process(new MyWastefulMax());
public static class MyWastefulMax extends ProcessWindowFunction<
SensorReading, // input type
Tuple3<String, Long, Integer>, // output type
String, // key type
TimeWindow> { // window type
@Override
public void process(
String key,
Context context,
Iterable<SensorReading> events,
Collector<Tuple3<String, Long, Integer>> out) {
int max = 0;
for (SensorReading event : events) {
max = Math.max(event.value, max);
}
out.collect(Tuple3.of(key, context.window().getEnd(), max));
}
}
在这个实现中有两件事需要注意:
- 所有分配给窗口的事件必须在键控闪烁状态下进行缓冲,直到窗口被触发。这可能相当昂贵。
- 我们的ProcessWindowFunction被传递了一个Context对象,它包含了关于窗口的信息。它的界面看起来像这样:
public abstract class Context implements java.io.Serializable {
public abstract W window();
public abstract long currentProcessingTime();
public abstract long currentWatermark();
public abstract KeyedStateStore windowState();
public abstract KeyedStateStore globalState();
}
windowState和globalState是您可以存储每个键、每个窗口或该键的所有窗口的全局每个键信息的地方。这可能很有用,例如,如果您想记录有关当前窗口的信息并在处理后续窗口时使用它。
Incremental Aggregation Example
DataStream<SensorReading> input = ...;
input
.keyBy(x -> x.key)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.reduce(new MyReducingMax(), new MyWindowFunction());
private static class MyReducingMax implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r1 : r2;
}
}
private static class MyWindowFunction extends ProcessWindowFunction<
SensorReading, Tuple3<String, Long, SensorReading>, String, TimeWindow> {
@Override
public void process(
String key,
Context context,
Iterable<SensorReading> maxReading,
Collector<Tuple3<String, Long, SensorReading>> out) {
SensorReading max = maxReading.iterator().next();
out.collect(Tuple3.of(key, context.window().getEnd(), max));
}
}
注意,Iterable将只包含一个读数——由MyReducingMax计算的预聚合的最大值。
迟到事件
默认情况下,当使用事件时间窗口时,延迟事件被删除。窗口API中有两个可选的部分可以让您对此进行更多控制。
您可以使用一种称为Side Outputs的机制,安排将被删除的事件收集到备用输出流中。下面是一个例子:
OutputTag<Event> lateTag = new OutputTag<Event>("late"){};
SingleOutputStreamOperator<Event> result = stream.
.keyBy(...)
.window(...)
.sideOutputLateData(lateTag)
.process(...);
DataStream<Event> lateStream = result.getSideOutput(lateTag);
您还可以指定允许的延迟时间间隔,在此期间,延迟事件将继续分配给适当的窗口(其状态将被保留)。默认情况下,每个延迟事件将导致窗口函数再次被调用(有时称为延迟触发)。
缺省情况下,允许的延迟时间为0。换句话说,水印后面的元素被丢弃(或发送到侧输出)。
for example:
stream.
.keyBy(...)
.window(...)
.allowedLateness(Time.seconds(10))
.process(...);
当允许的延迟大于0时,只有那些延迟到将被丢弃的事件被发送到侧输出(如果它已经配置)。
Surprises
Flink的窗口API的某些方面可能不符合您的预期。基于在flink-user邮件列表和其他地方常见的问题,这里有一些关于窗口的事实可能会让你感到惊讶。
滑动窗口复制
滑动窗口赋值器可以创建许多窗口对象,并将每个事件复制到每个相关窗口中。例如,如果您每15分钟有一个长度为24小时的滑动窗口,则每个事件将被复制到4 * 24 = 96个窗口中。
时间窗口与时代对齐
仅仅因为使用了一个小时的处理时间窗口并在12:05启动应用程序,并不意味着第一个窗口将在1:05关闭。第一个窗口将持续55分钟,1点关闭。
但是请注意,翻转和滑动窗口赋值器接受一个可选的偏移参数,该参数可用于更改窗口的对齐方式。详情请参阅翻滚窗口和滑动窗口。
Windows可以跟随Windows
例如,它是这样工作的:
stream
.keyBy(t -> t.key)
.window(<window assigner>)
.reduce(<reduce function>)
.windowAll(<same window assigner>)
.reduce(<same reduce function>);
你可能希望Flink的运行时足够智能,可以为你做这个并行预聚合(前提是你正在使用ReduceFunction或AggregateFunction),但它不是。
之所以这样做,是因为时间窗口生成的事件是根据窗口结束时的时间分配的时间戳。因此,例如,由一个小时长的窗口生成的所有事件都将有时间戳来标记一个小时的结束。任何使用这些事件的后续窗口的持续时间应该与前一个窗口相同,或者是前一个窗口的倍数。
空timewindow没有结果
只有当事件被分配给Windows时,才会创建它们。因此,如果在给定的时间框架内没有发生事件,就不会报告结果。
晚事件可能导致晚合并
会话窗口基于可以合并的窗口的抽象。每个元素最初被分配给一个新窗口,之后当窗口之间的间隙足够小时就合并它们。通过这种方式,一个晚发生的事件可以弥合两个以前分开的会话之间的差距,从而产生一个晚合并。
事件驱动的应用程序
process functions
介绍
ProcessFunction将事件处理与计时器和状态结合在一起,使其成为流处理应用程序的强大构建块。这是使用Flink创建事件驱动应用程序的基础。它非常类似于RichFlatMapFunction,但添加了计时器。
举个栗子
如果你已经在流分析章节中做了动手练习,你会记得它使用一个tumbbingeventtimewindow来计算每个司机在每个小时的提示的总和,像这样:
// compute the sum of the tips per hour for each driver
DataStream<Tuple3<Long, Long, Float>> hourlyTips = fares
.keyBy((TaxiFare fare) -> fare.driverId)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.process(new AddTips());
使用KeyedProcessFunction做同样的事情是相当简单的,而且具有教育意义。让我们开始用下面的代码替换上面的代码:
// compute the sum of the tips per hour for each driver
DataStream<Tuple3<Long, Long, Float>> hourlyTips = fares
.keyBy((TaxiFare fare) -> fare.driverId)
.process(new PseudoWindow(Time.hours(1)));
在这段代码段中,一个名为PseudoWindow的KeyedProcessFunction被应用到一个键值流,其结果是DataStream<Tuple3<Long, Long, Float>>(使用Flink内置时间窗口的实现产生的相同类型的流)。
伪窗口的整体轮廓如下:
// Compute the sum of the tips for each driver in hour-long windows.
// The keys are driverIds.
public static class PseudoWindow extends
KeyedProcessFunction<Long, TaxiFare, Tuple3<Long, Long, Float>> {
private final long durationMsec;
public PseudoWindow(Time duration) {
this.durationMsec = duration.toMilliseconds();
}
@Override
// Called once during initialization.
public void open(Configuration conf) {
. . .
}
@Override
// Called as each fare arrives to be processed.
public void processElement(
TaxiFare fare,
Context ctx,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
. . .
}
@Override
// Called when the current watermark indicates that a window is now complete.
public void onTimer(long timestamp,
OnTimerContext context,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
. . .
}
}
注意事项:
- processfunction有几种类型——这是KeyedProcessFunction,但也有coprocessfunction、broadcastprocessfunction等。
- KeyedProcessFunction是RichFunction的一种。作为一个RichFunction,它可以访问处理托管键控状态所需的open和getRuntimeContext方法。
- 有两个回调需要实现:processElement和onTimer。每个传入事件都会调用processselement;当计时器触发时调用onTimer。这些计时器可以是事件时间计时器,也可以是处理时间计时器。processElement和onTimer都提供了一个上下文对象,该对象可用于与TimerService(以及其他内容)进行交互。两个回调函数还被传递给一个Collector,该Collector可用于发出结果。
open() 方法
// Keyed, managed state, with an entry for each window, keyed by the window's end time.
// There is a separate MapState object for each driver.
private transient MapState<Long, Float> sumOfTips;
@Override
public void open(Configuration conf) {
MapStateDescriptor<Long, Float> sumDesc =
new MapStateDescriptor<>("sumOfTips", Long.class, Float.class);
sumOfTips = getRuntimeContext().getMapState(sumDesc);
}
由于票价事件可能会乱序到达,因此有时需要在完成前一个小时的结果计算之前处理事件一个小时。事实上,如果水印延迟比窗口长度长得多,那么可能有多个窗口同时打开,而不是只有两个。该实现通过使用MapState来支持这一点,它将每个窗口结束的时间戳映射到该窗口的提示总和。
processElement()方法
public void processElement(
TaxiFare fare,
Context ctx,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
long eventTime = fare.getEventTime();
TimerService timerService = ctx.timerService();
if (eventTime <= timerService.currentWatermark()) {
// This event is late; its window has already been triggered.
} else {
// Round up eventTime to the end of the window containing this event.
long endOfWindow = (eventTime - (eventTime % durationMsec) + durationMsec - 1);
// Schedule a callback for when the window has been completed.
timerService.registerEventTimeTimer(endOfWindow);
// Add this fare's tip to the running total for that window.
Float sum = sumOfTips.get(endOfWindow);
if (sum == null) {
sum = 0.0F;
}
sum += fare.tip;
sumOfTips.put(endOfWindow, sum);
}
}
思考点:
- 对于最近的事件会发生什么?水位(即,延迟)之后的事件正在被删除。如果您想做得更好,可以考虑使用侧输出,这将在下一节中解释。
- 这个例子使用了一个MapState,其中键是时间戳,并为相同的时间戳设置了一个Timer。这是一个常见的模式;它使计时器触发时查找相关信息变得容易和高效。
onTimer() 方法
public void onTimer(
long timestamp,
OnTimerContext context,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
long driverId = context.getCurrentKey();
// Look up the result for the hour that just ended.
Float sumOfTips = this.sumOfTips.get(timestamp);
Tuple3<Long, Long, Float> result = Tuple3.of(driverId, timestamp, sumOfTips);
out.collect(result);
this.sumOfTips.remove(timestamp);
}
注意:
- 传递给 onTimer 的 OnTimerContext context 可用于确定当前 key。
- 我们的 pseudo-windows 在当前 Watermark 到达每小时结束时触发,此时调用 onTimer。 这个 onTimer 方法从 sumOfTips 中删除相关的条目,这样做的效果是不可能容纳延迟的事件。 这相当于在使用 Flink 的时间窗口时将 allowedLateness 设置为零。
性能考虑
Flink 提供了为 RocksDB 优化的 MapState 和 ListState 类型。 相对于 ValueState,更建议使用 MapState 和 ListState,因为使用 RocksDBStateBackend 的情况下, MapState 和 ListState 比 ValueState 性能更好。 RocksDBStateBackend 可以附加到 ListState,而无需进行(反)序列化, 对于 MapState,每个 key/value 都是一个单独的 RocksDB 对象,因此可以有效地访问和更新 MapState。
旁路输出(Side Outputs)
简介
有几个很好的理由希望从 Flink 算子获得多个输出流,如下报告条目:
- 异常情况(exceptions)
- 格式错误的事件(malformed events)
- 延迟的事件(late events)
- operator 告警(operational alerts),如与外部服务的连接超时
旁路输出(Side outputs)是一种方便的方法。除了错误报告之外,旁路输出也是实现流的 n 路分割的好方法。
示例
现在你可以对上一节中忽略的延迟事件执行某些操作。
Side output channel 与 OutputTag 相关联。这些标记拥有自己的名称,并与对应 DataStream 类型一致。
private static final OutputTag<TaxiFare> lateFares = new OutputTag<TaxiFare>("lateFares") {};
上面显示的是一个静态 OutputTag ,当在 PseudoWindow 的 processElement 方法中发出延迟事件时,可以引用它:
if (eventTime <= timerService.currentWatermark()) {
// 事件延迟,其对应的窗口已经触发。
ctx.output(lateFares, fare);
} else {
. . .
}
以及当在作业的 main 中从该旁路输出访问流时:
// 计算每个司机每小时的小费总和
SingleOutputStreamOperator hourlyTips = fares
.keyBy((TaxiFare fare) -> fare.driverId)
.process(new PseudoWindow(Time.hours(1)));
hourlyTips.getSideOutput(lateFares).print();
或者,可以使用两个同名的 OutputTag 来引用同一个旁路输出,但如果这样做,它们必须具有相同的类型。
结语
在本例中,你已经了解了如何使用 ProcessFunction 重新实现一个简单的时间窗口。 当然,如果 Flink 内置的窗口 API 能够满足你的开发需求,那么一定要优先使用它。 但如果你发现自己在考虑用 Flink 的窗口做些错综复杂的事情,不要害怕自己动手。
此外,ProcessFunctions 对于计算分析之外的许多其他用例也很有用。 下面的实践练习提供了一个完全不同的例子。
ProcessFunctions 的另一个常见用例是清理过时 State。如果你回想一下 Rides and Fares Exercise , 其中使用 RichCoFlatMapFunction 来计算简单 Join,那么示例方案假设 TaxiRides 和 TaxiFares 两个事件是严格匹配为一个有效 数据对(必须同时出现)并且每一组这样的有效数据对都和一个唯一的 rideId 严格对应。如果数据对中的某个 TaxiRides 事件(TaxiFares 事件) 丢失,则同一 rideId 对应的另一个出现的 TaxiFares 事件(TaxiRides 事件)对应的 State 则永远不会被清理掉。 所以这里可以使用 KeyedCoProcessFunction 的实现代替它(RichCoFlatMapFunction),并且可以使用计时器来检测和清除任何过时 的 State。
通过状态快照实现容错处理
State Backends
由 Flink 管理的 keyed state 是一种分片的键/值存储,每个 keyed state 的工作副本都保存在负责该键的 taskmanager 本地中。另外,Operator state 也保存在机器节点本地。Flink 定期获取所有状态的快照,并将这些快照复制到持久化的位置,例如分布式文件系统。
如果发生故障,Flink 可以恢复应用程序的完整状态并继续处理,就如同没有出现过异常。
Flink 管理的状态存储在 state backend 中。Flink 有两种 state backend 的实现 – 一种基于 RocksDB 内嵌 key/value 存储将其工作状态保存在磁盘上的,另一种基于堆的 state backend,将其工作状态保存在 Java 的堆内存中。这种基于堆的 state backend 有两种类型:FsStateBackend,将其状态快照持久化到分布式文件系统;MemoryStateBackend,它使用 JobManager 的堆保存状态快照。
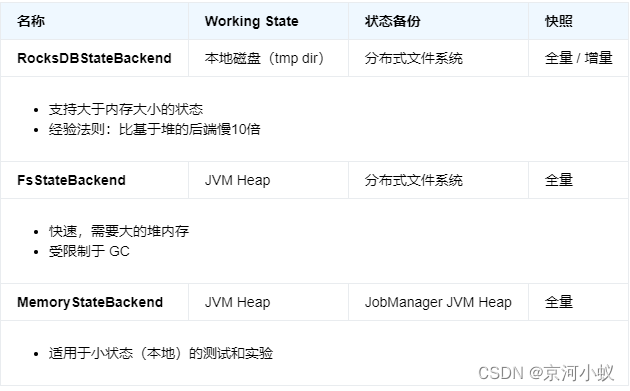
当使用基于堆的 state backend 保存状态时,访问和更新涉及在堆上读写对象。但是对于保存在 RocksDBStateBackend 中的对象,访问和更新涉及序列化和反序列化,所以会有更大的开销。但 RocksDB 的状态量仅受本地磁盘大小的限制。还要注意,只有 RocksDBStateBackend 能够进行增量快照,这对于具有大量变化缓慢状态的应用程序来说是大有裨益的。
所有这些 state backends 都能够异步执行快照,这意味着它们可以在不妨碍正在进行的流处理的情况下执行快照。
状态快照
定义
-
快照 – 是 Flink 作业状态全局一致镜像的通用术语。快照包括指向每个数据源的指针(例如,到文件或 Kafka 分区的偏移量)以及每个作业的有状态运算符的状态副本,该状态副本是处理了 sources 偏移位置之前所有的事件后而生成的状态。
-
Checkpoint – 一种由 Flink 自动执行的快照,其目的是能够从故障中恢复。Checkpoints 可以是增量的,并为快速恢复进行了优化。
-
外部化的 Checkpoint – 通常 checkpoints 不会被用户操纵。Flink 只保留作业运行时的最近的 n 个 checkpoints(n 可配置),并在作业取消时删除它们。但你可以将它们配置为保留,在这种情况下,你可以手动从中恢复。
-
Savepoint – 用户出于某种操作目的(例如有状态的重新部署/升级/缩放操作)手动(或 API 调用)触发的快照。Savepoints 始终是完整的,并且已针对操作灵活性进行了优化。
状态快照如何工作?
Flink 使用 Chandy-Lamport algorithm 算法的一种变体,称为异步 barrier 快照(asynchronous barrier snapshotting)。
当 checkpoint coordinator(job manager 的一部分)指示 task manager 开始 checkpoint 时,它会让所有 sources 记录它们的偏移量,并将编号的 checkpoint barriers 插入到它们的流中。这些 barriers 流经 job graph,标注每个 checkpoint 前后的流部分。
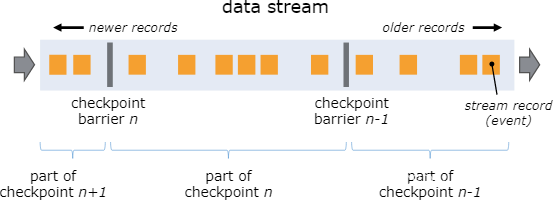
Checkpoint n 将包含每个 operator 的 state,这些 state 是对应的 operator 消费了严格在 checkpoint barrier n 之前的所有事件,并且不包含在此(checkpoint barrier n)后的任何事件后而生成的状态。
当 job graph 中的每个 operator 接收到 barriers 时,它就会记录下其状态。拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment) 以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。
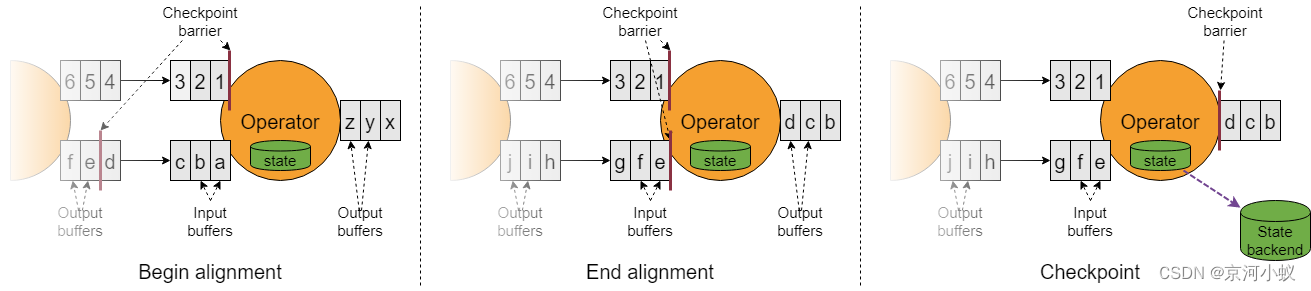
Flink 的 state backends 利用写时复制(copy-on-write)机制允许当异步生成旧版本的状态快照时,能够不受影响地继续流处理。只有当快照被持久保存后,这些旧版本的状态才会被当做垃圾回收。
确保精确一次(exactly once)
- Flink 不会从快照中进行恢复(at most once)
- 没有任何丢失,但是你可能会得到重复冗余的结果(at least once)
- 没有丢失或冗余重复(exactly once)
Flink 通过回退和重新发送 source 数据流从故障中恢复,当理想情况被描述为精确一次时,这并不意味着每个事件都将被精确一次处理。相反,这意味着 每一个事件都会影响 Flink 管理的状态精确一次。
Barrier 只有在需要提供精确一次的语义保证时需要进行对齐(Barrier alignment)。如果不需要这种语义,可以通过配置 CheckpointingMode.AT_LEAST_ONCE 关闭 Barrier 对齐来提高性能。
端到端精确一次
为了实现端到端的精确一次,以便 sources 中的每个事件都仅精确一次对 sinks 生效,必须满足以下条件:
- 你的 sources 必须是可重放的,并且
- 你的 sinks 必须是事务性的(或幂等的)















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











