






各位应该有过类似的经历,用着用着Cursor,感觉AI好像忘记了之前聊的内容,变的胡言乱语或者有一个内容改了好几次都改不对。
今天就从原理上给大家解读下这个问题,首先,我们都知道,Cursor本身是依靠Claude的大模型去回答我们的问题,因此我们需要了解一些关于AI大模型是如何生成回答的,雨飞简单给大家科普下。
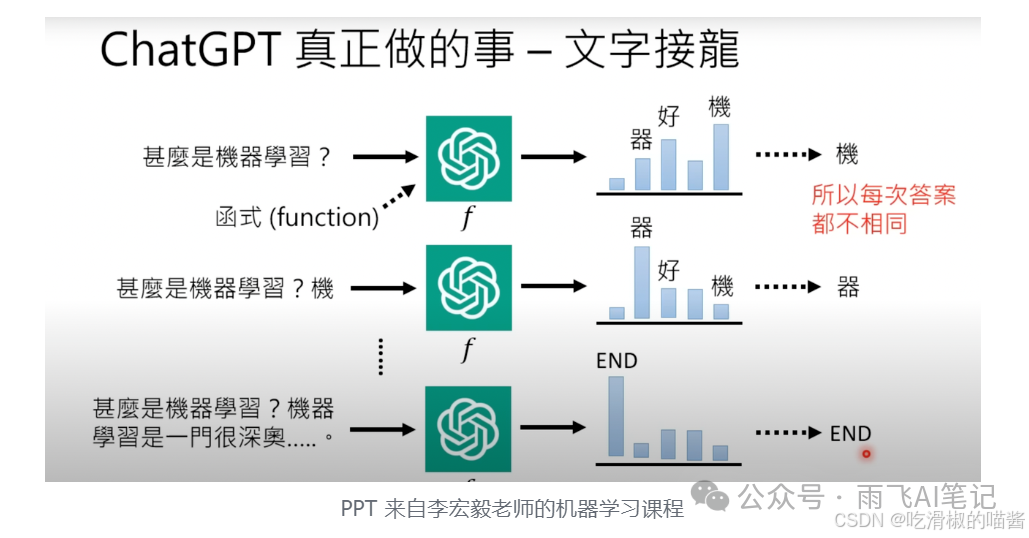
不管是ChatGPT还是Claude,这种AI大模型,本质上是在做一个文字接龙的游戏,就是会根据输入的内容,按照一定的规则选择下一个词应该是什么,并且每次都添加一个词。
这里的规则,就是我们可以控制的地方,有的人会认为应该选择概率最高的词,有的人会认为应该在概率排名靠前的TopK个中随机选一个效果会更好。这就是需要我们根据实际情况进行选择。这种随机性的引入,使得大模型能够生成更有创造力的文章,但同时就导致了就算我们使用相同的提示词,每次的输出也都可能得到不同的内容。
在我们每一次和Claude对话的时候,Cursor都会将之前的上下文信息携带上,输入给Claude,这样就导致了历史信息越多,输入的上下文就越多,而输出响应的时间就会变长。这也就是为何,我们一直在一个对话中不停的聊天,会导致这个页面出现卡顿的原因。
然而,由于算力以及响应时间等问题,上下文的长度是不可能无限扩展的,都是有一个上限值。在这里,我们一般用Token数进行衡量,Token就是大语言模型处理文本的时候,对文本进行切分的最小单位,可以是一个字,也可以是一个词组,这取决于大语言模型使用的编码策略。这个我们后面会给大家展示,现在稍作了解就可以。
在Cursor中,究竟支持多长的上下文呢。
在Cursor官方文档中,我们可以找到答案。文档中很明显的可以看到,在chat中支持2w的tokens,而在cmd-k中支持1w的tokens。因此,当我们聊天的上下文过长的时候,Cursor会删减一部分上下文记录以及相关代码,以便满足这个长度。

那么问题来了,1w的token大概是多少单词或者汉字呢。这里,我们可以简单的记忆,1000个token通常代表750个英文单词或500个汉字。这个方法还需要我们自己去简单估算下上下文的长度,雨飞这里给大家找了一个网站可以比较方便的显示token数。
网址:https://tokencounter.org/claude_counter
下面是展示截图,目前这个网站只能统计Claude模型所占的token数。

如果想统计GPT模型所占用的token数,可以使用下面这个网站。
网址:https://platform.openai.com/tokenizer
为此,我们可以非常清晰的知道自己输入了大概多少的内容,是否超出了模型上限。
如果非要添加上下文信息的话,可以先让AI把之前的聊天记录进行总结,写到文件中,然后引用这个文件再进行后面的提问。这样相当于把复杂的聊天记录进行了压缩,更节省token数,而且指令还更清晰。
如果你觉得这篇文章对你有启发,欢迎点赞收藏转发下。目前运营了两个Cursor交流群,付费、免费的都有,有想一起交流学习的可以添加下方的微信,邀你一起学习。
❤️常驻小尾巴❤️
加 1060687688,备注「CSDN」,送你一份「AI工具与副业变现指南」

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









