






解决的问题:HOI(Human Object Interaction,人物交互关系预测)
输入一张图片,预测(人,物,动作)三元组
 |  |
公开数据集:
HICO-DET
包含47,774张图片,包含了600类人物交互行为(使用verb-object对),像骑车,骑马,持电话
117种常见行为,像骑,喂,...,无交互行为标签
80种常见物体,像自行车,手机等标签
 |
朴素的想法:
对于一张图片先做目标检测,得到人体和物体所在区域,然后再提取①人②物③人∩物区域的特征,进行分类
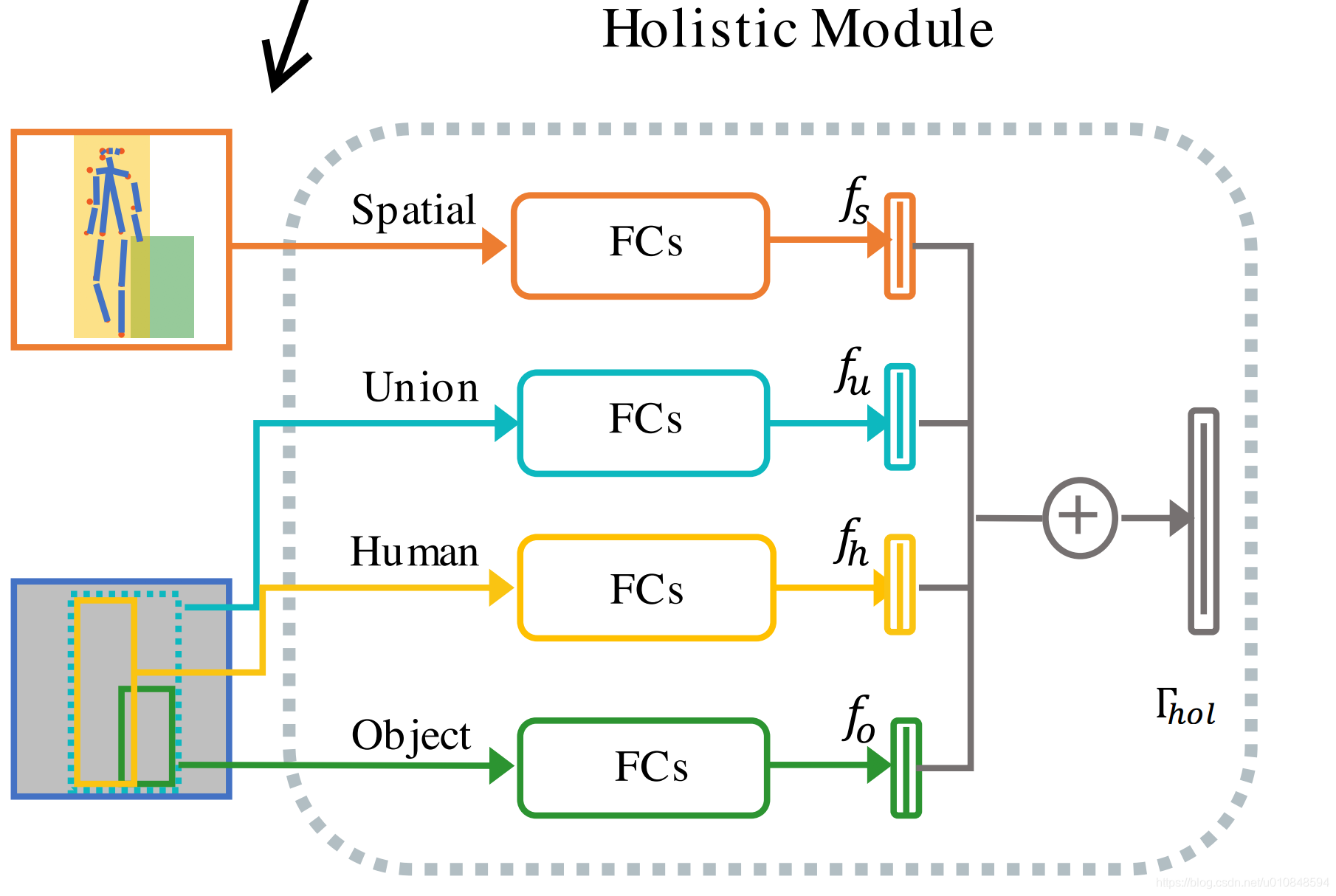
但是作者觉得这样的做法只能得到整体的一些特征,模型不容易学到一些局部特征,于是我们就使用人体关键点来作为指导,关键点所在区域当成attention mask,这样可以得到更多的局部特征

Pipeline

上述即为整体流程,backbone用来提特征,在得到特征图的基础上预测人物框,人体关键点,然后将相应的特征送到需要的模块中,做分类,即可得到结果
创新点:
1.使用Pose作指导,起到attention map的作用
2.pose可以起到全局和局部指导的作用















 802
802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









