







文章目录
- 一、增加数据
- 二、删除数据
- 三、修改数据
- 3.1 df.fillna()填充空值
- (1)value : 变量, 字典, Series, or DataFrame
- (2)method: {'backfill', 'bfill', 'pad', 'ffill', None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
- (3)axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。
- (4)inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
- (5)limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
- 3.2 填充异常值
- 四、查询数据
一、增加数据
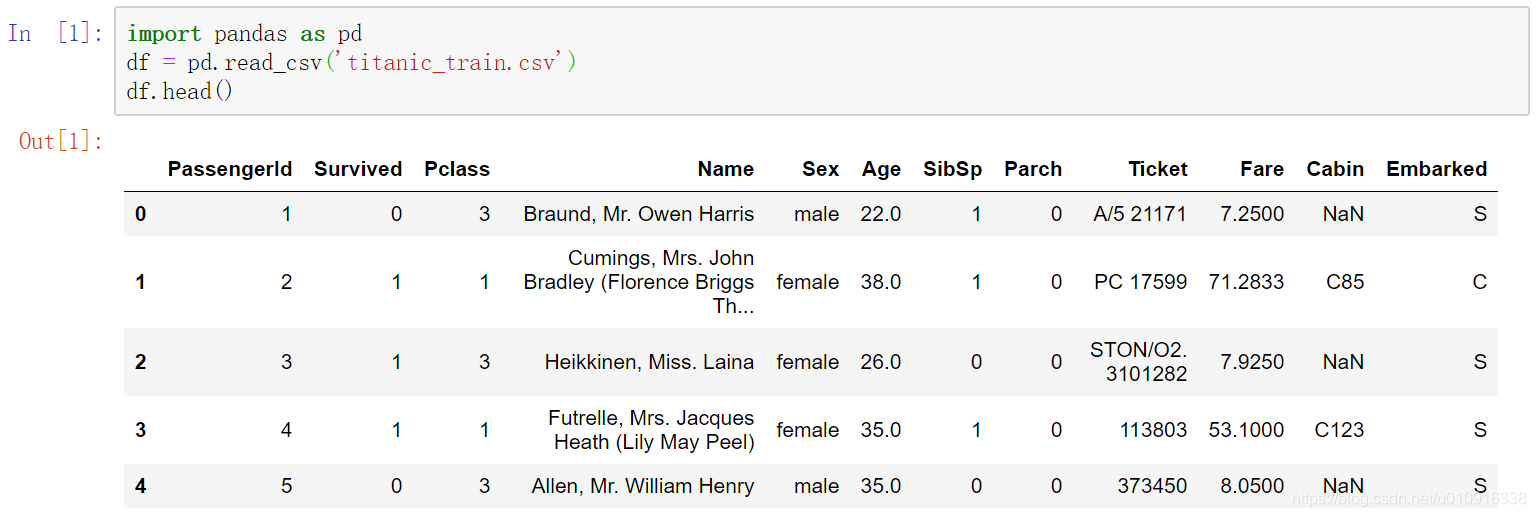
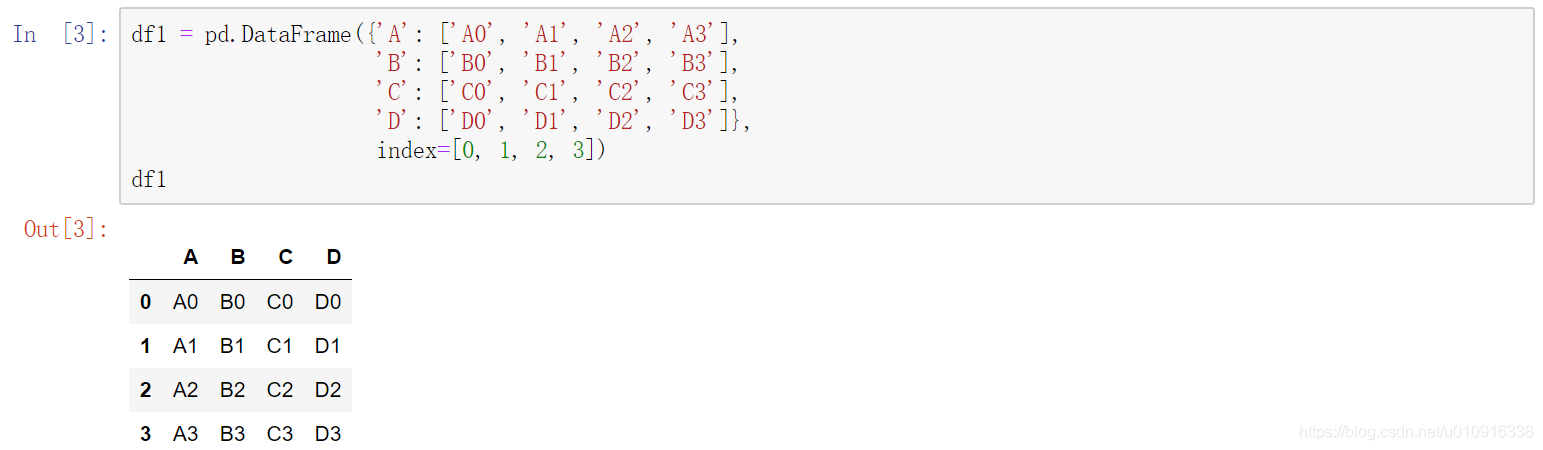
1.1 增加一行
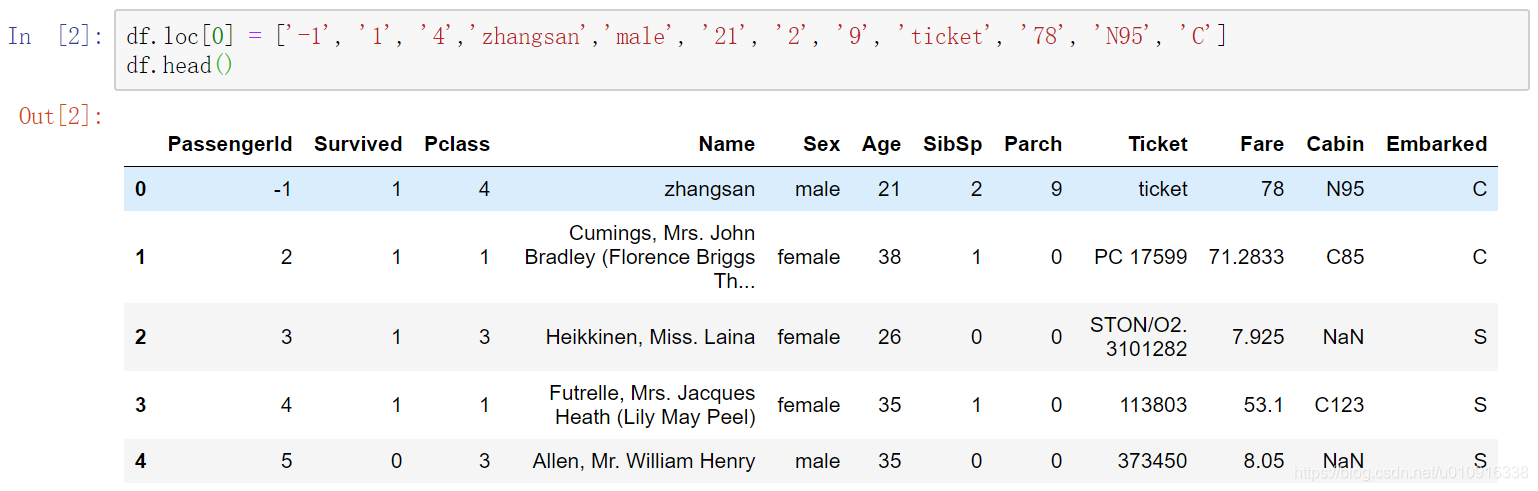
1.2 增加一列
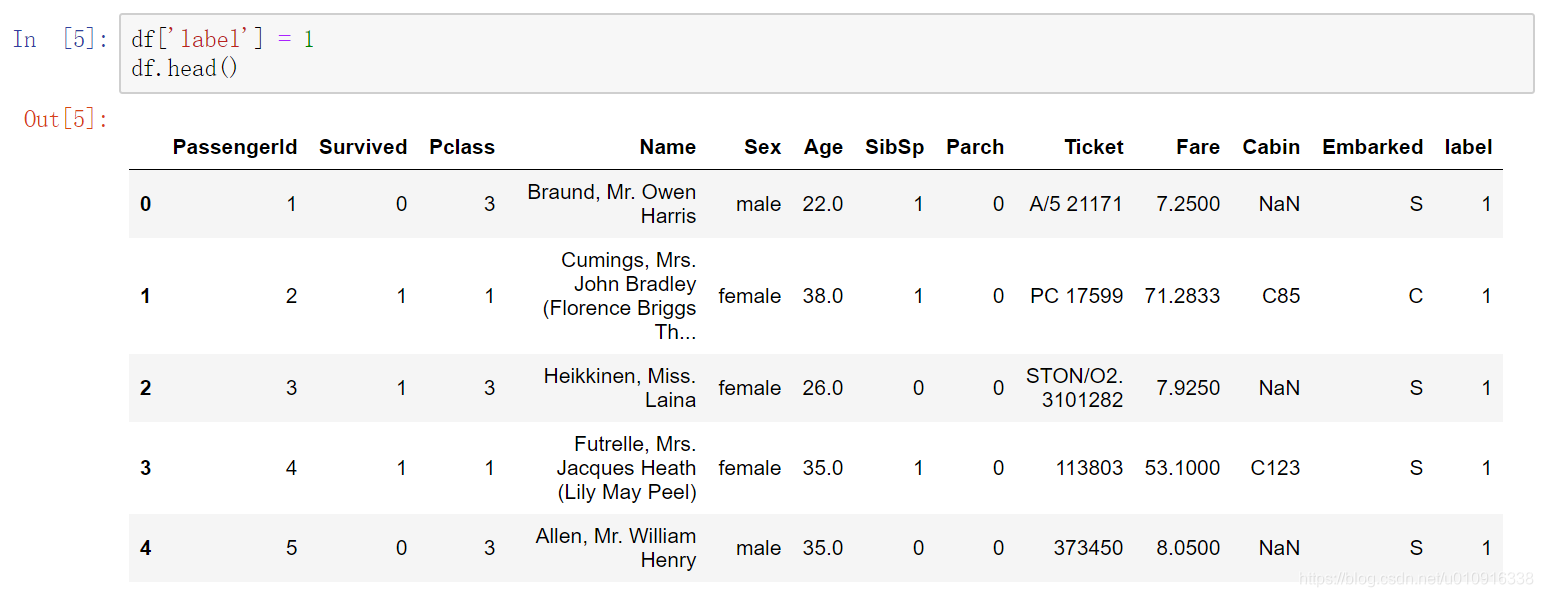
1.3 pd.concat()拼接数据
注:pd.concat()既可以增加行,又可以增加列
pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
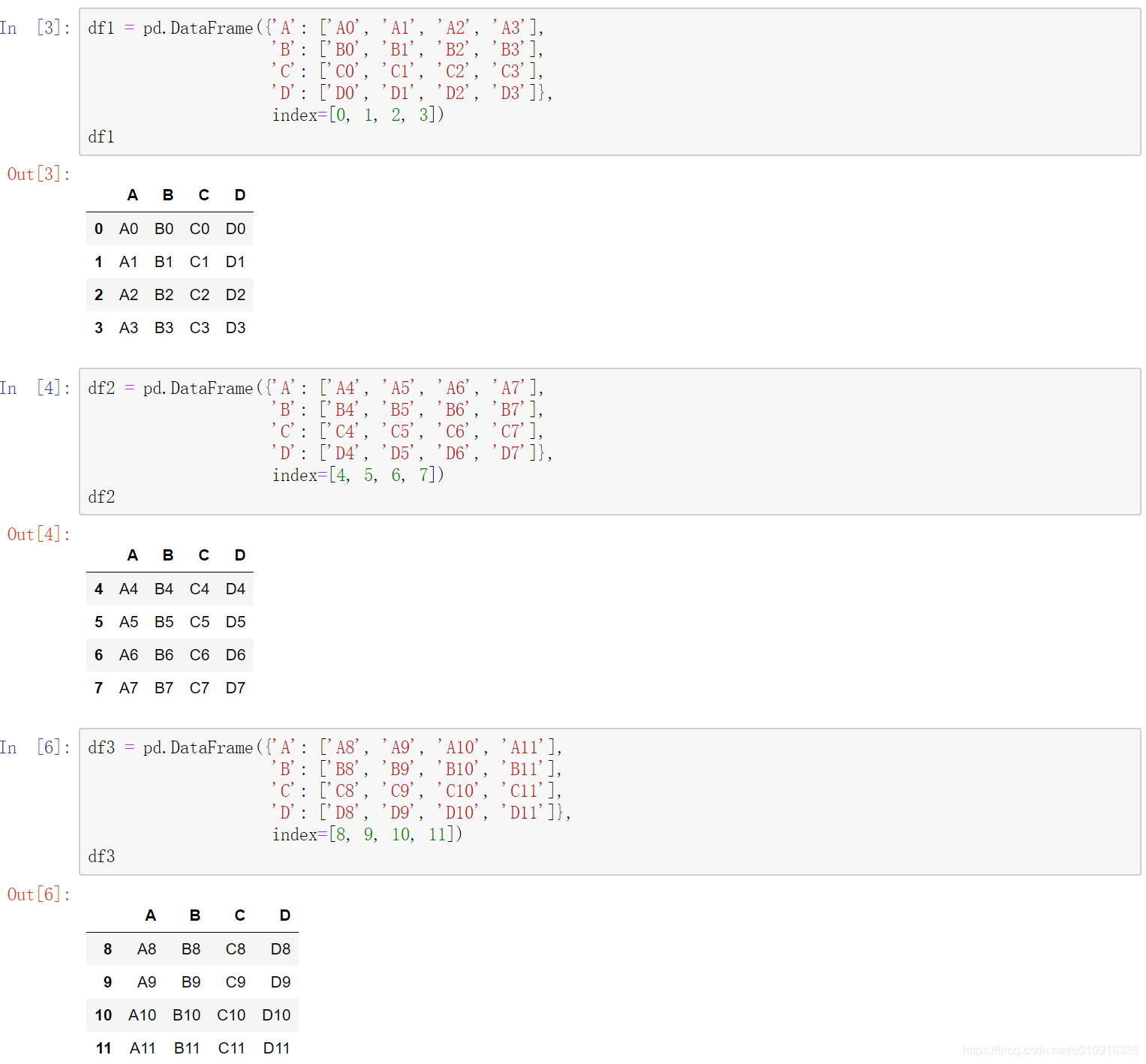
(1)objs:Series,DataFrame或Panel对象的序列或映射。
注:默认是纵向拼接,axis=0
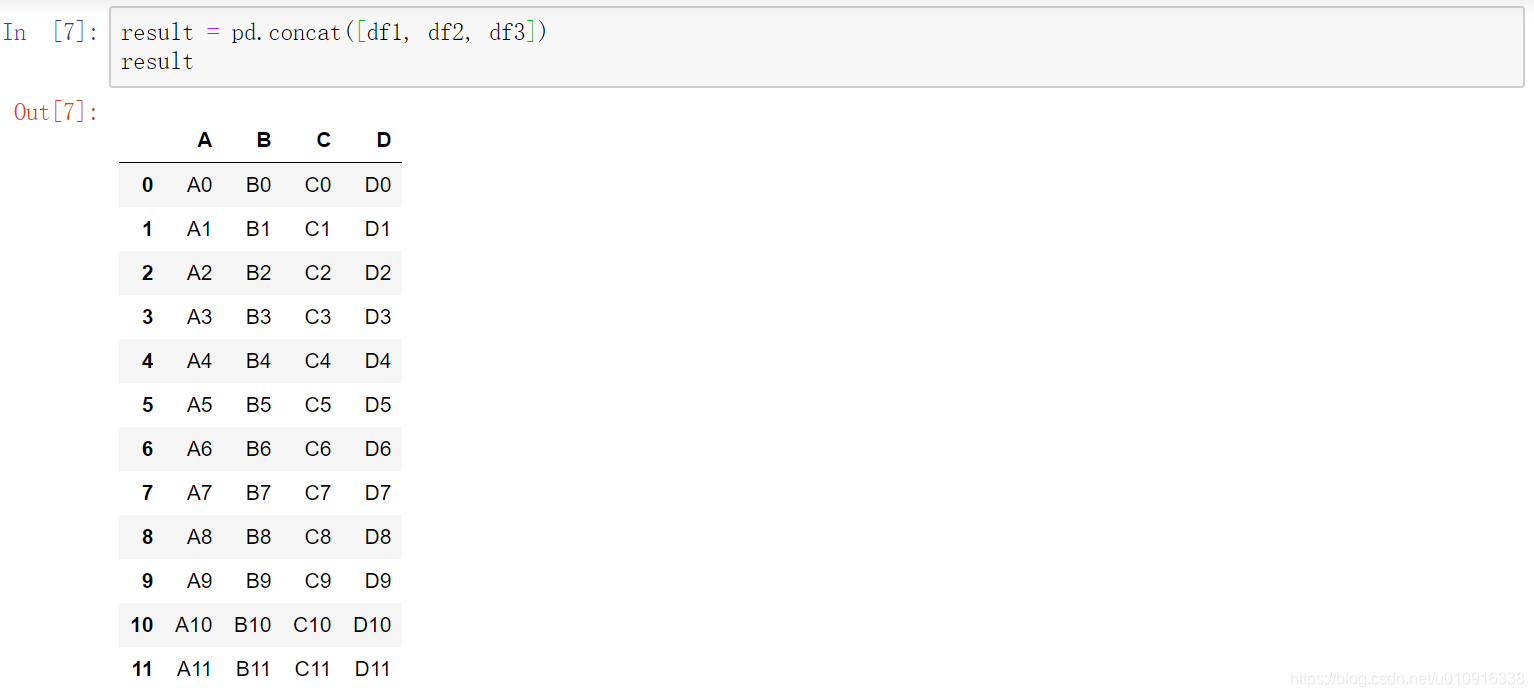
(2)axis:{0,1,…},默认为0。纵向拼接。
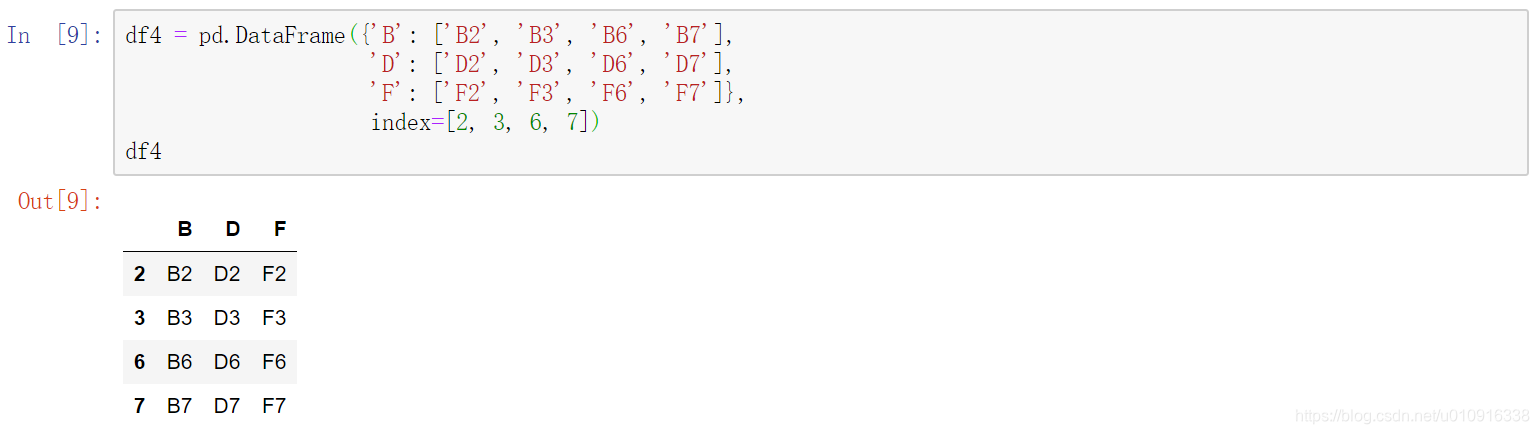
注:当axis=1横向拼接时,默认为并集
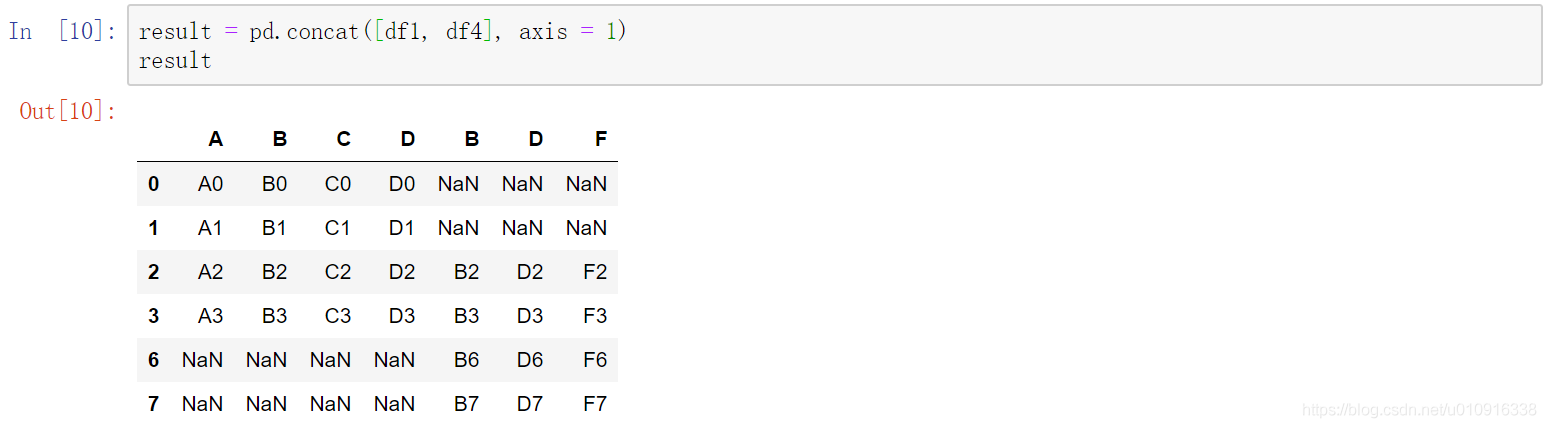
(3)join:{‘inner’,‘outer’},默认为“outer”。如何处理其他轴上的索引。outer为联合和inner为交集。

(4)ignore_index:boolean,default False。如果为True,索引重新排序。
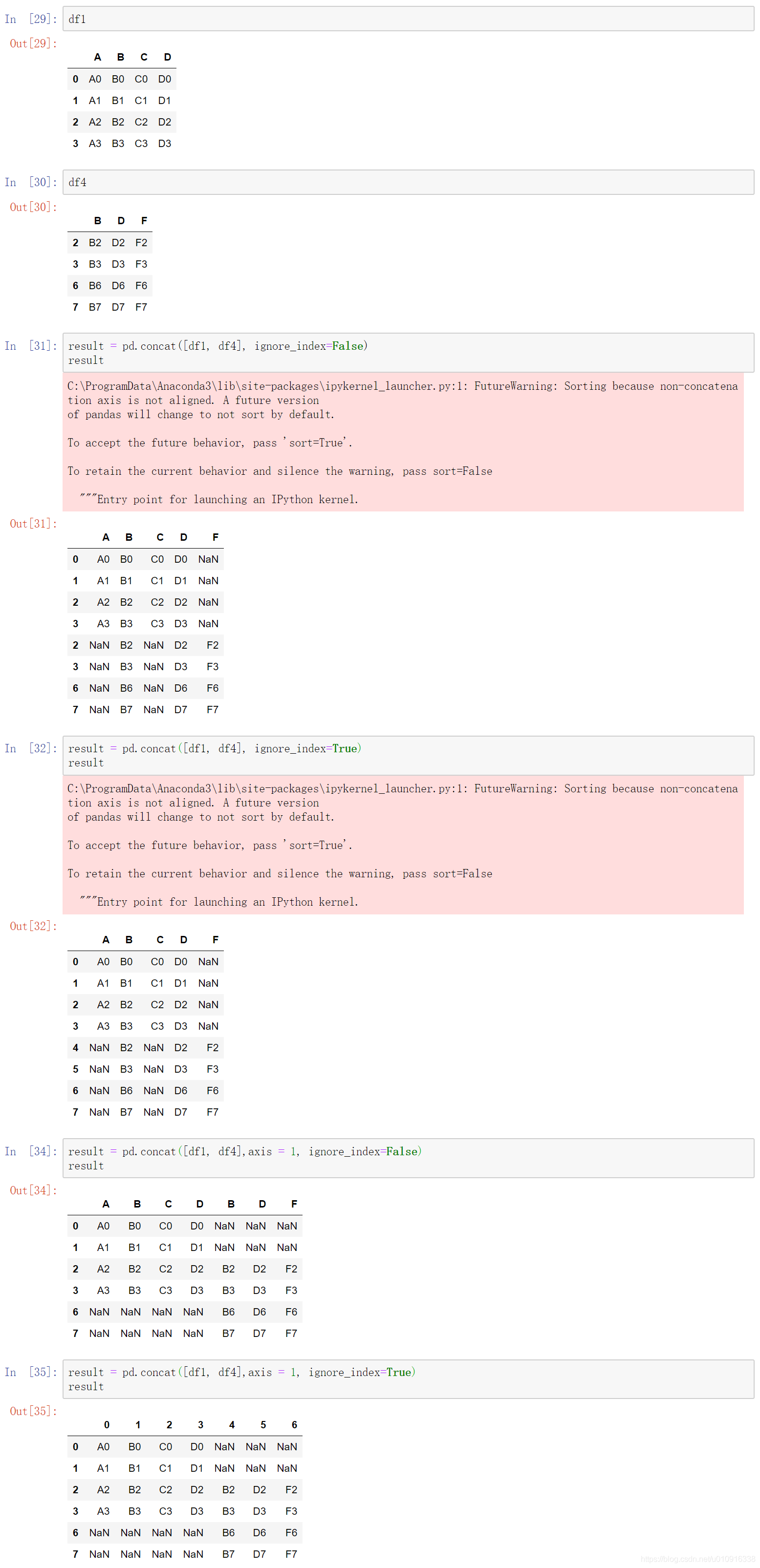
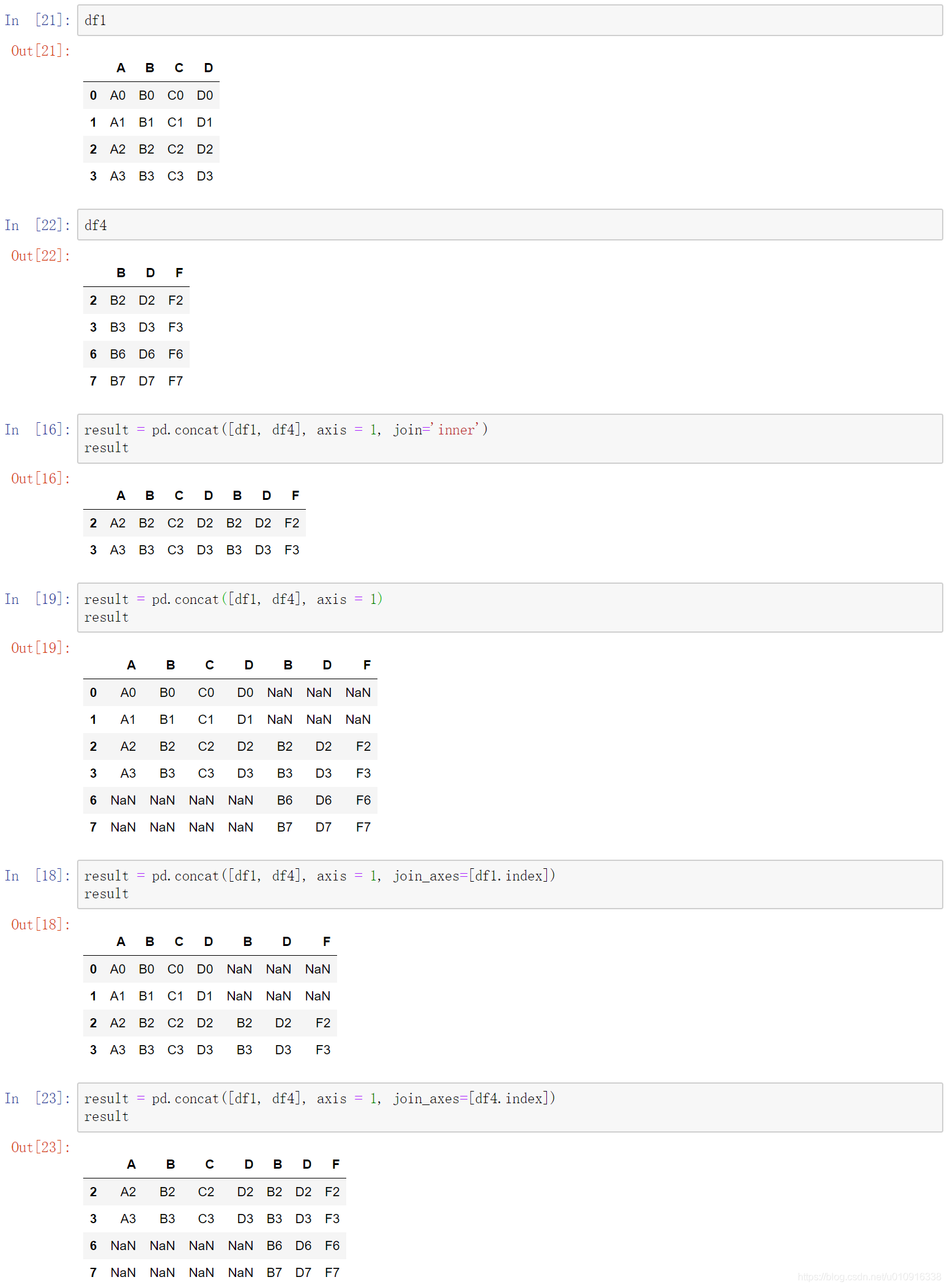
(5)join_axes:Index对象列表。outer外联之后,设置该参数能达到左连接和右连接的功能。
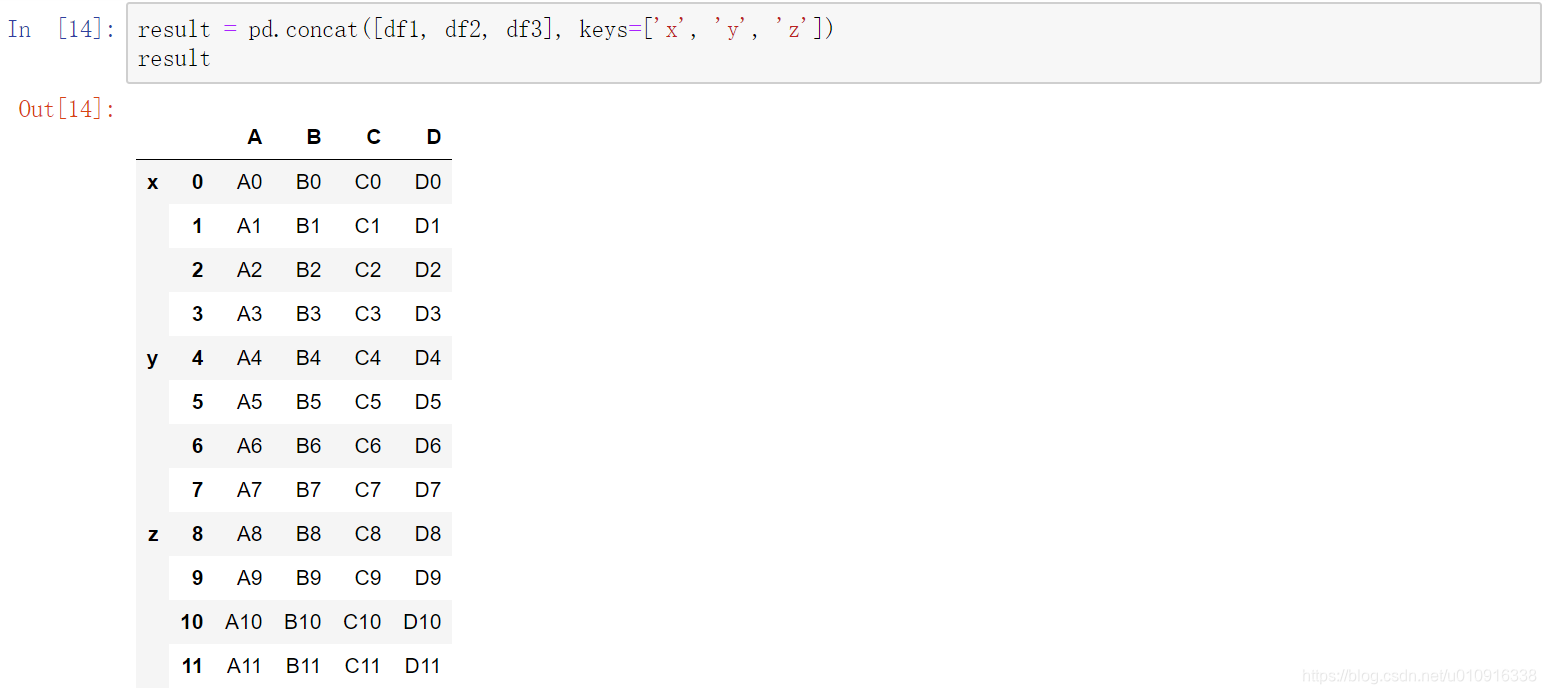
(6)keys:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。
levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。
names:list,default无。结果层次索引中的级别的名称。
verify_integrity:boolean,default False。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。
copy:boolean,default True。如果为False,请勿不必要地复制数据。
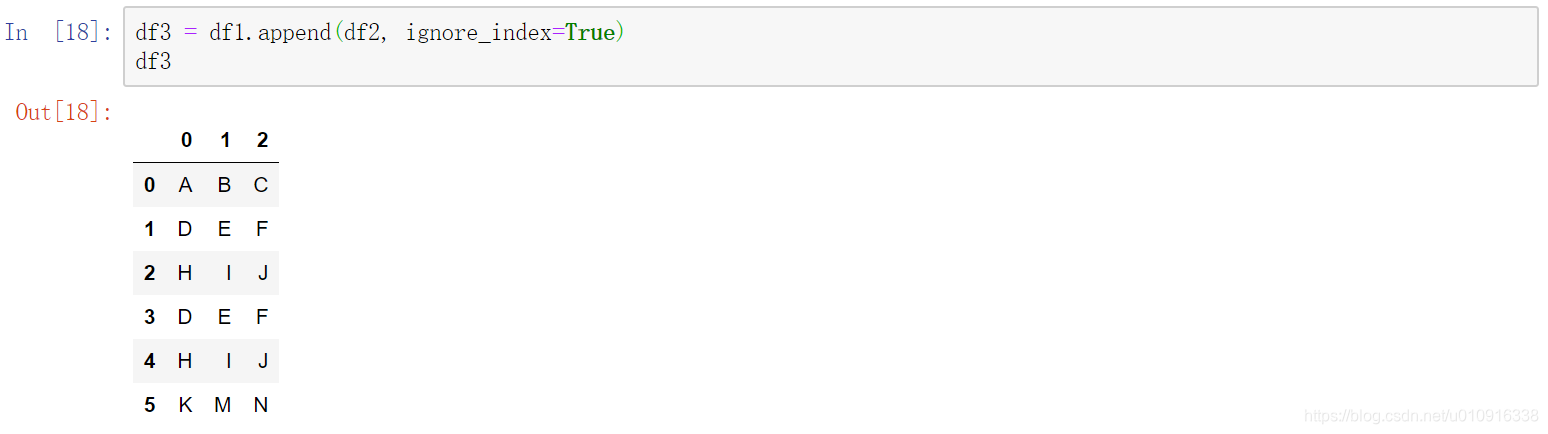
1.4 pd.append()拼接数据
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
将被 append 的对象添加到调用者的末尾(类似 list 的方法)。
注意:如果调用者是 DataFrame 而被 append 的对象是 Series,将会把 Series 作为一列添加到末尾。Series 和 DataFrame 均有此方法。
(1)other,可以是dataframe,可以是series
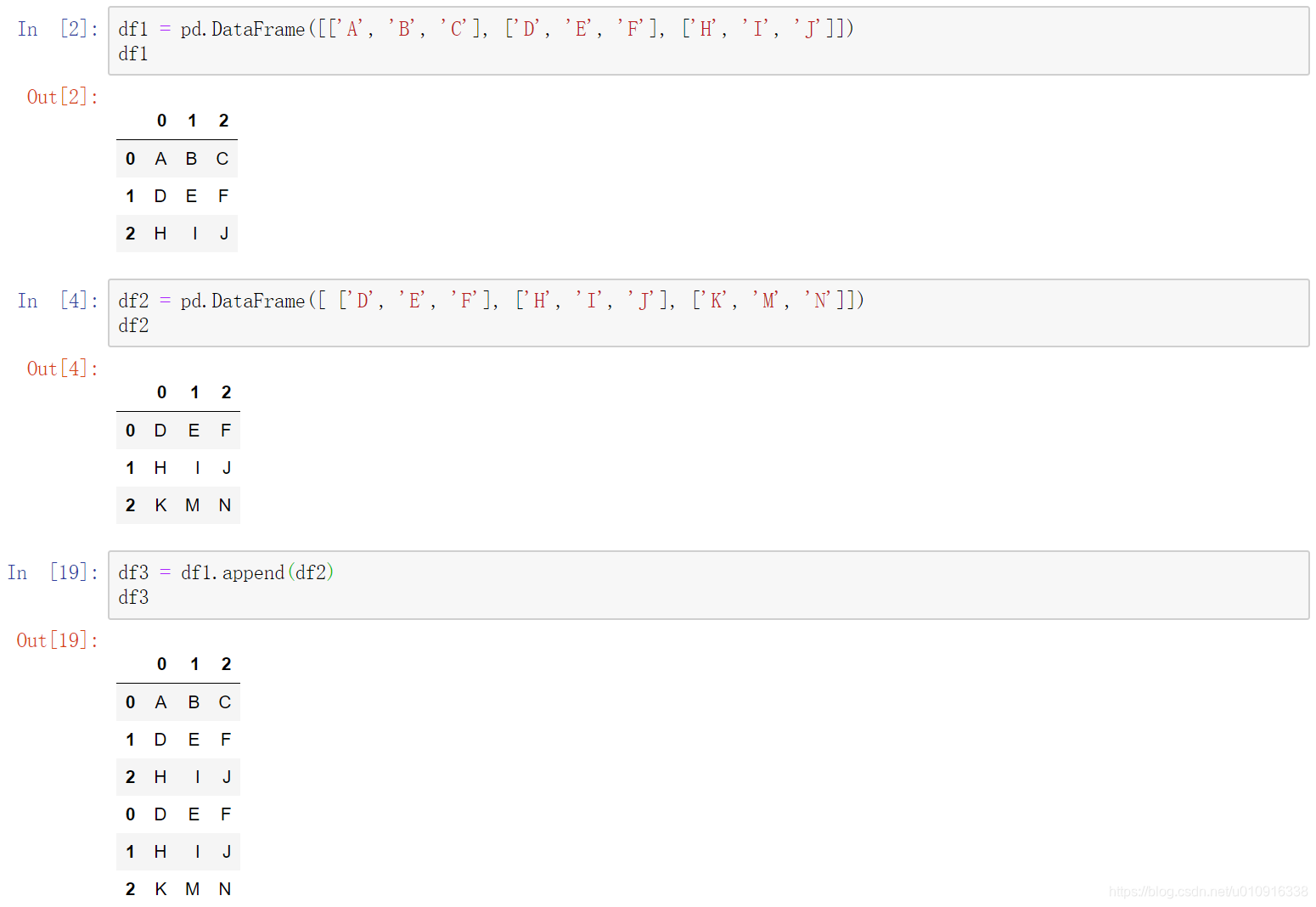
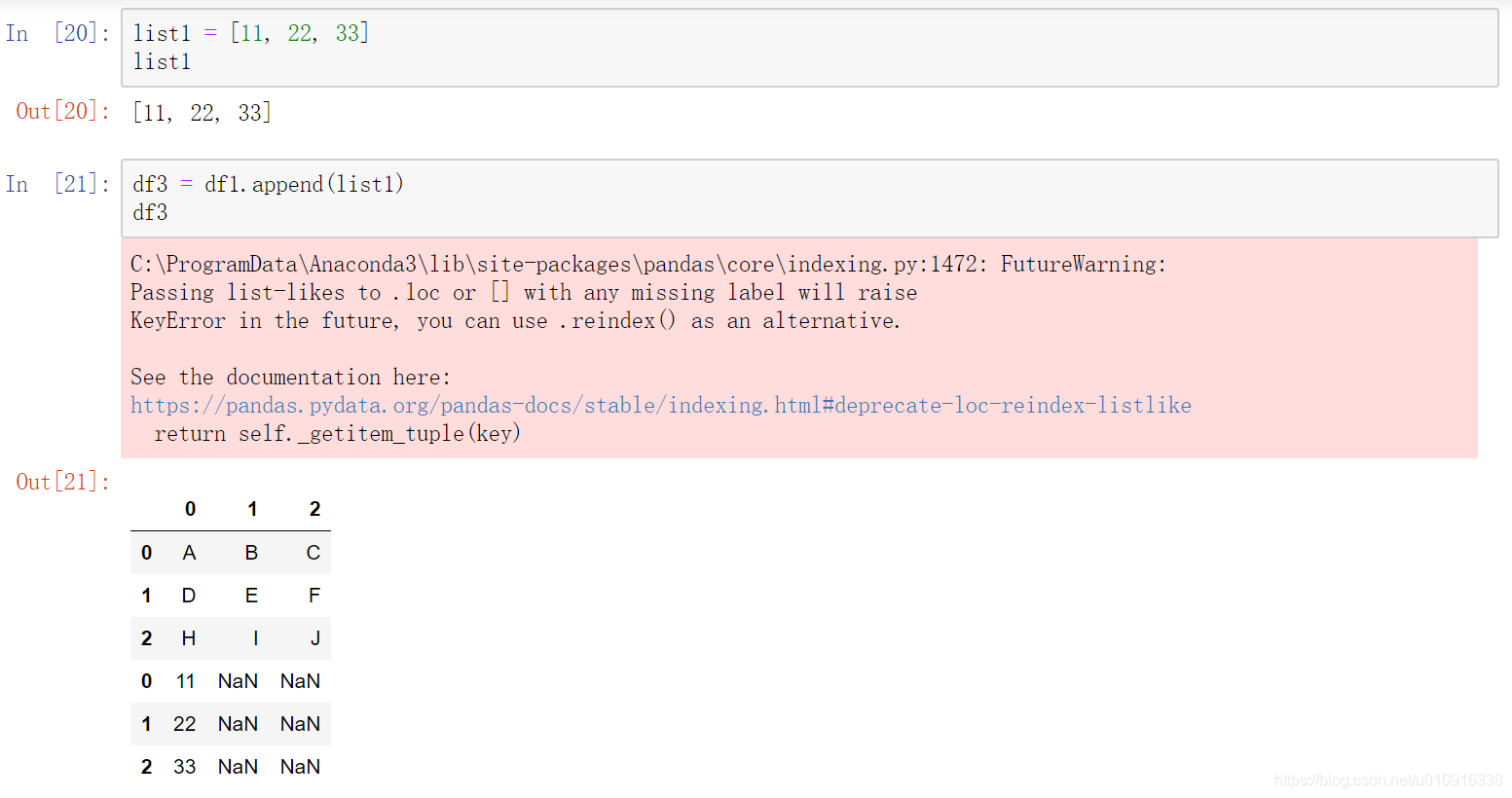
(2)ignore_index:boolean,default False。如果为True,索引重新排序。
二、删除数据
2.1 df.drop()
DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
- 注:
- (1)默认删除行
- (2)无论行列,数据中显示position位置只能按照position位置删除,显示label值则只能按照label值删除
(1)labels 就是要删除的行列的名字,用列表给定
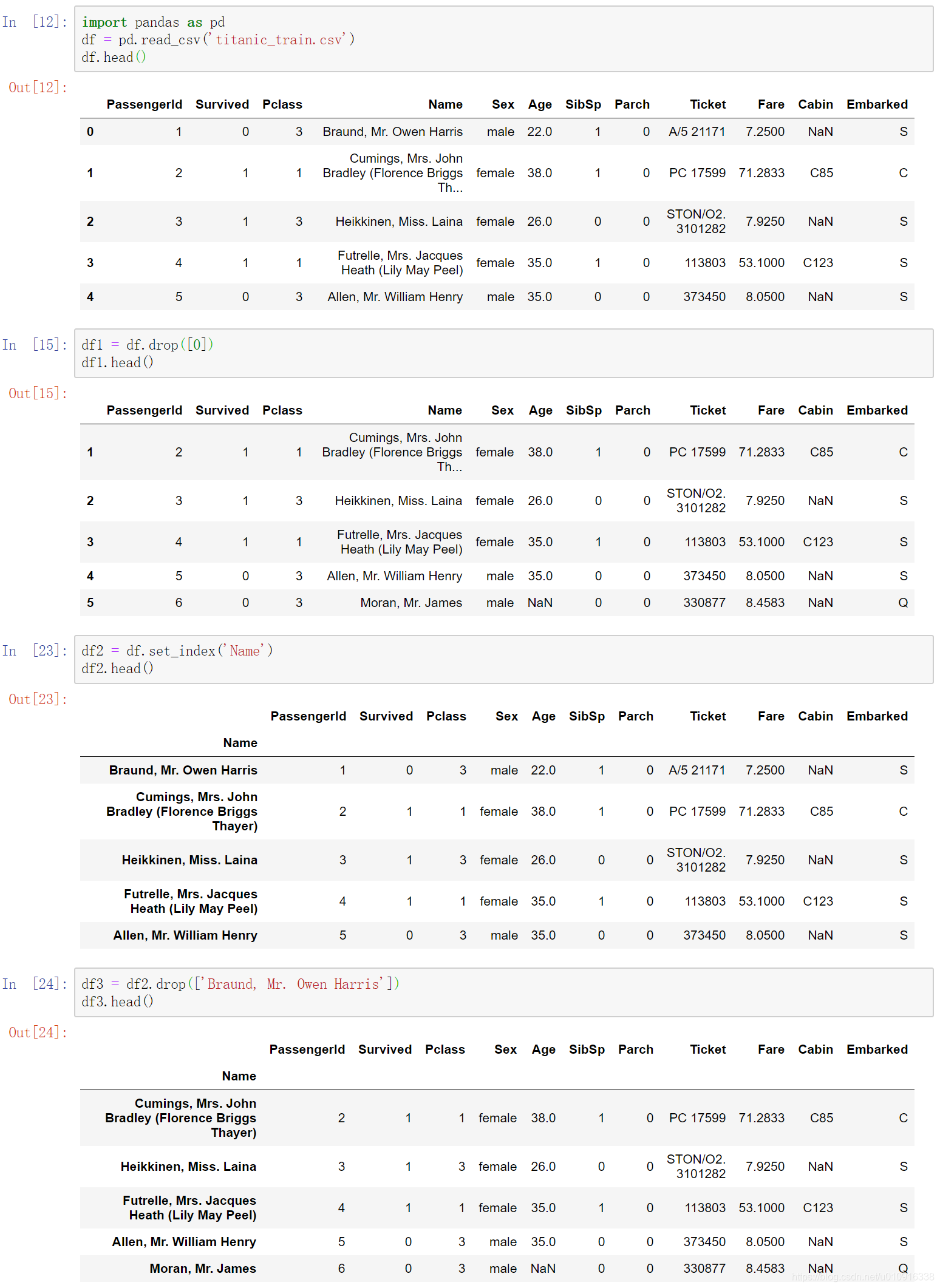
(2)axis 默认为0,指删除行,因此删除columns时要指定axis=1;
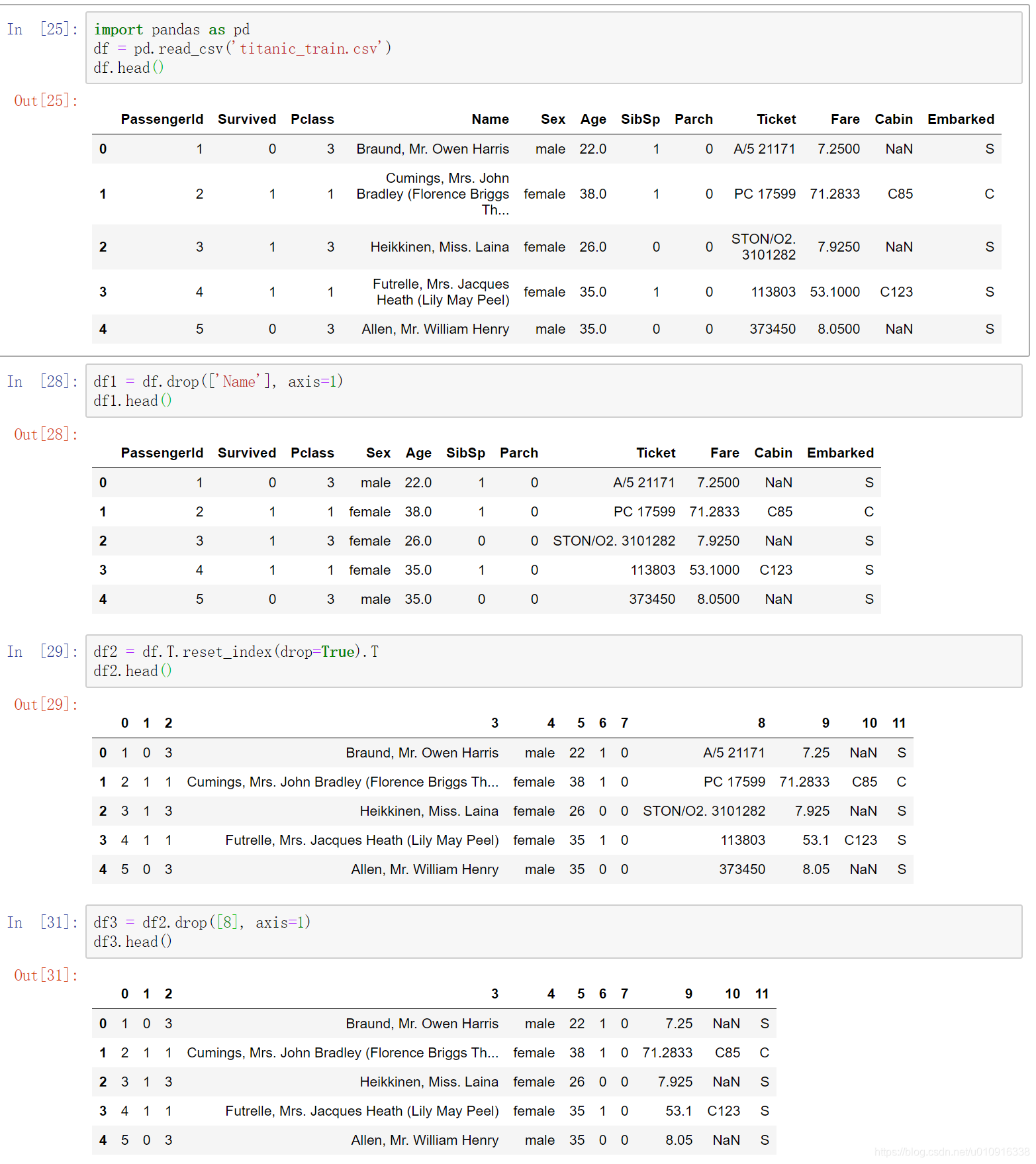
(3)index 直接指定要删除的行
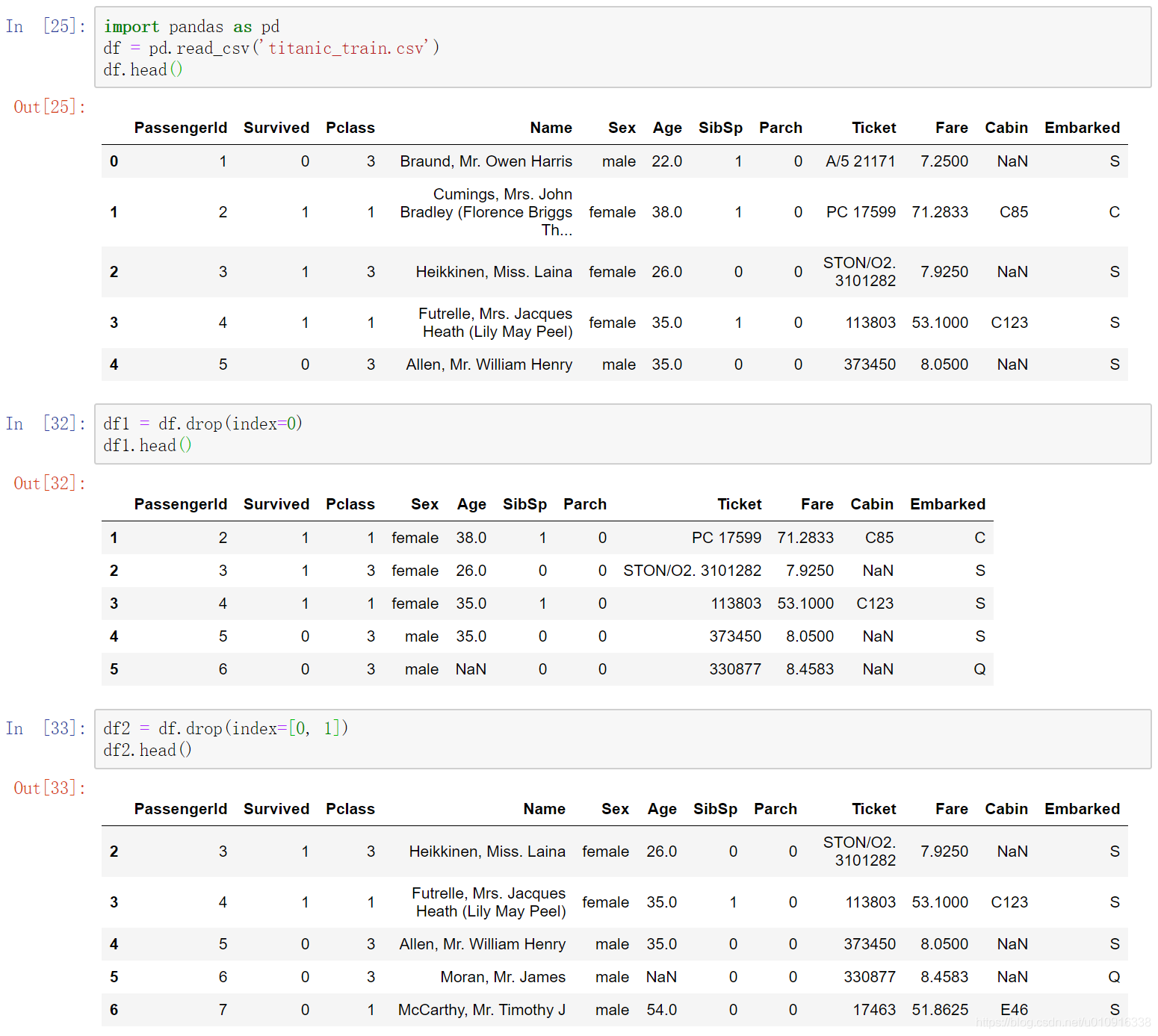
(4)columns 直接指定要删除的列
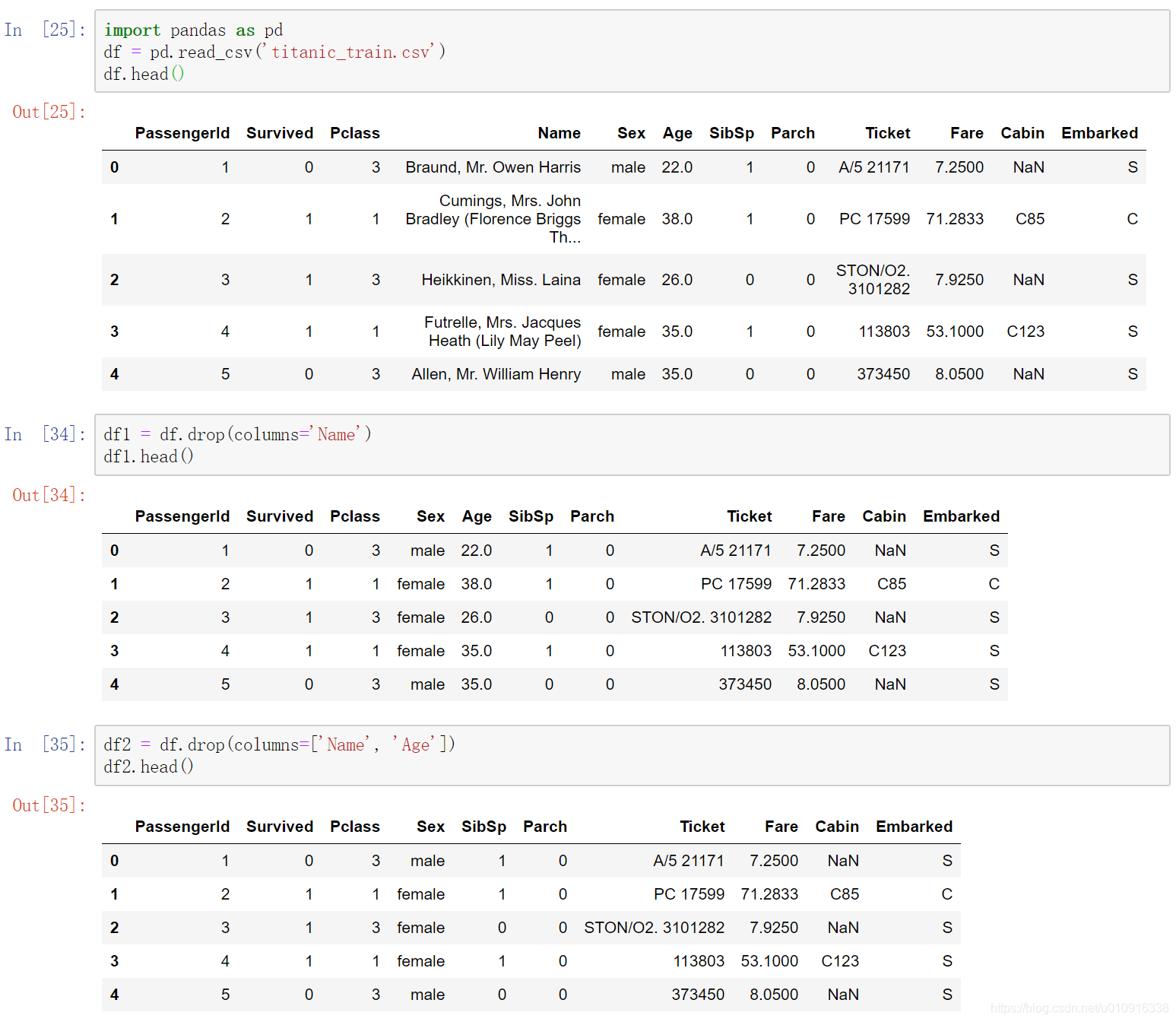
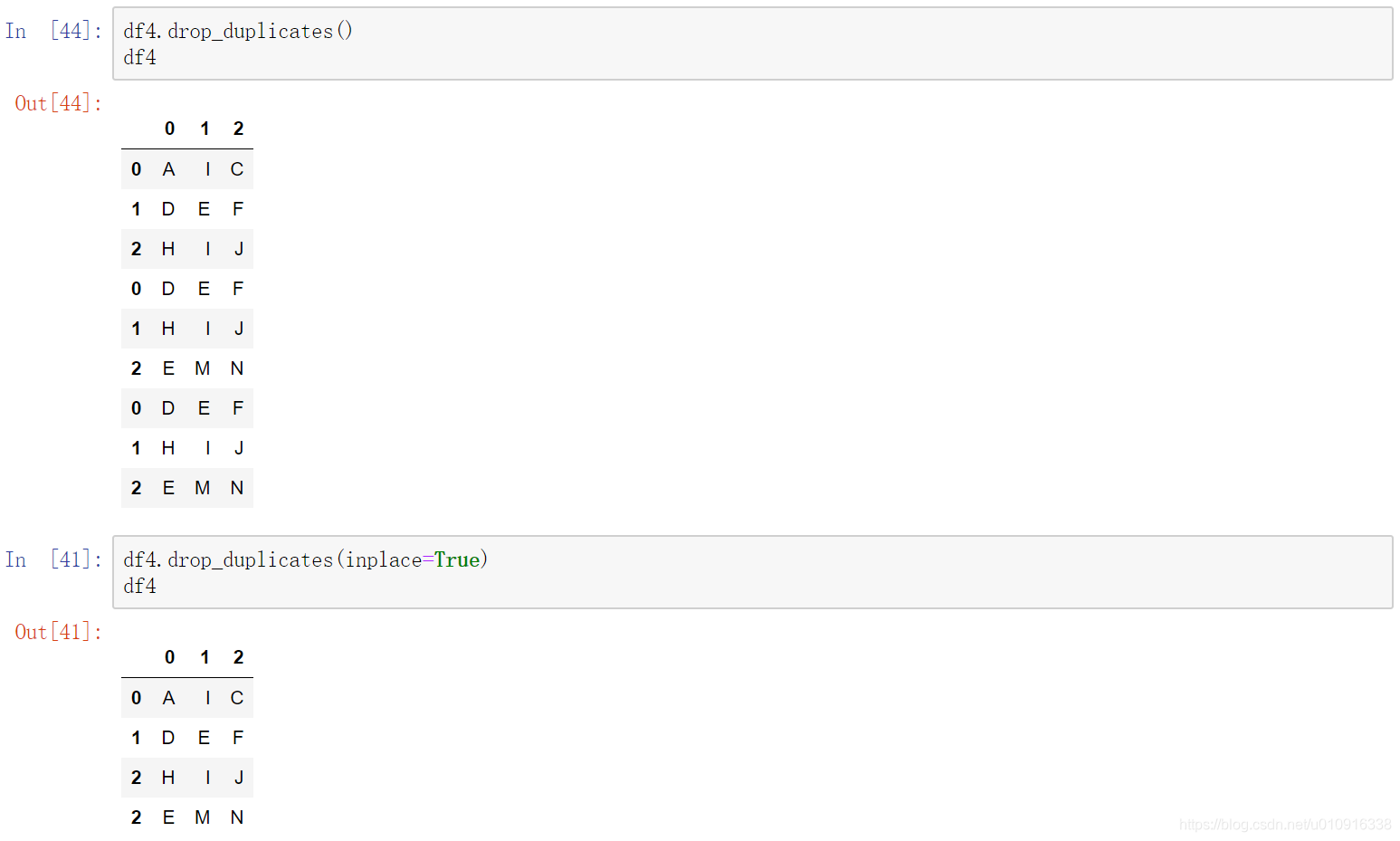
(5)inplace,默认=False该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
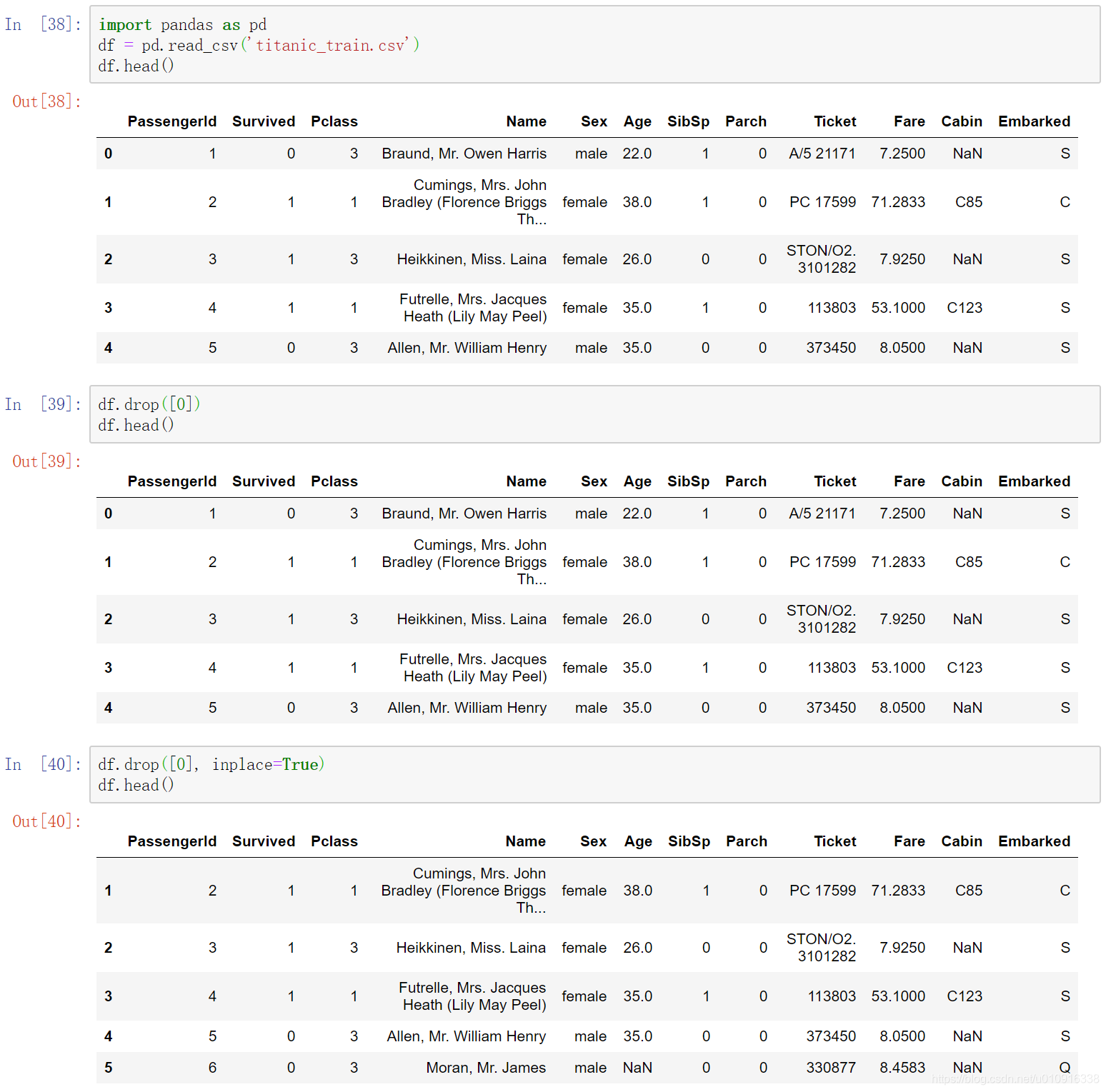
2.2 df.drop_duplicates()删除重复数据
DataFrame.drop_duplicates(subset=None, keep=‘first’, inplace=False)
(1)subset : column label or sequence of labels, 用来指定特定的列,默认所有列
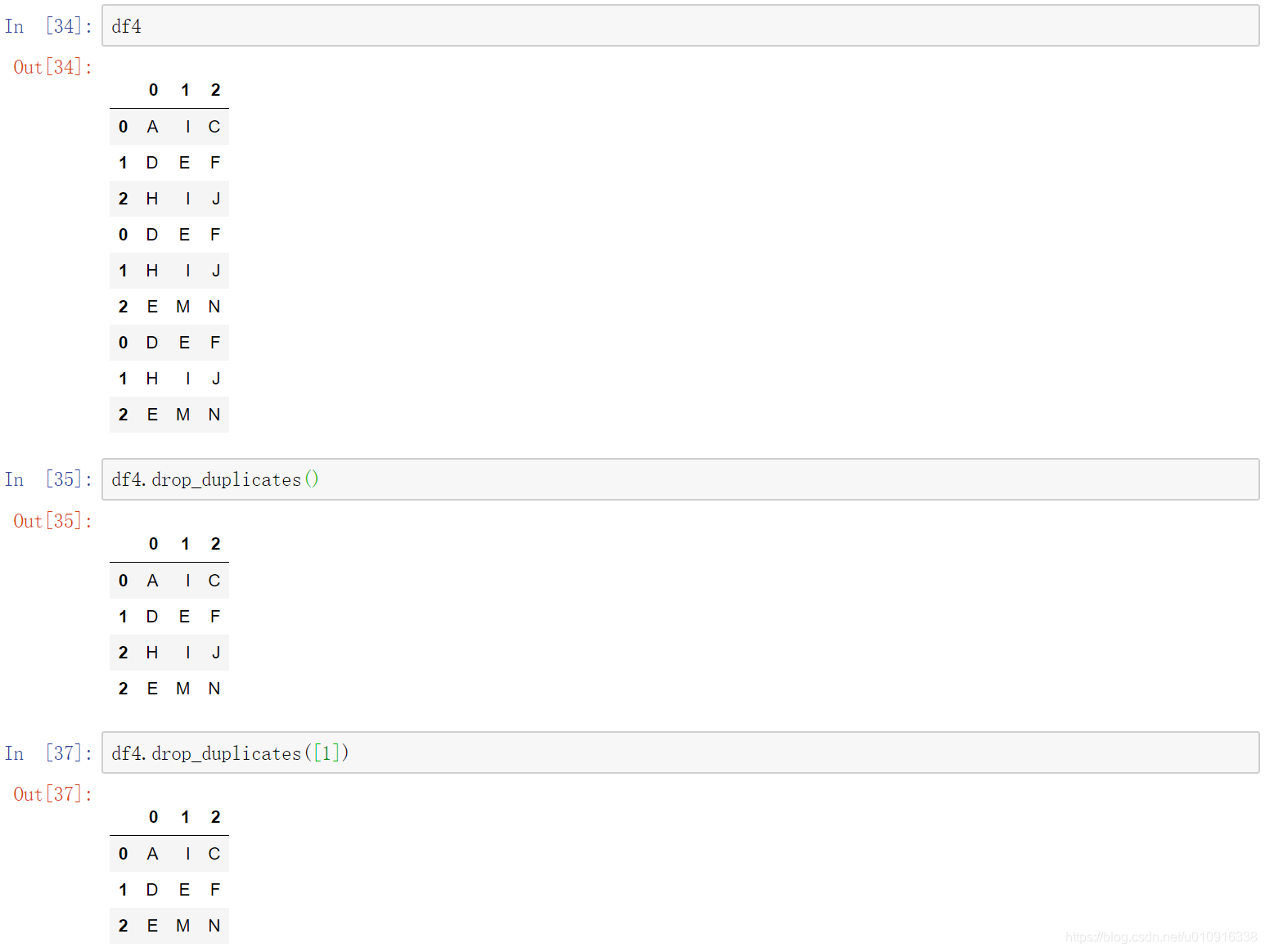
(2)keep=‘first’,默认保留一条重复记录
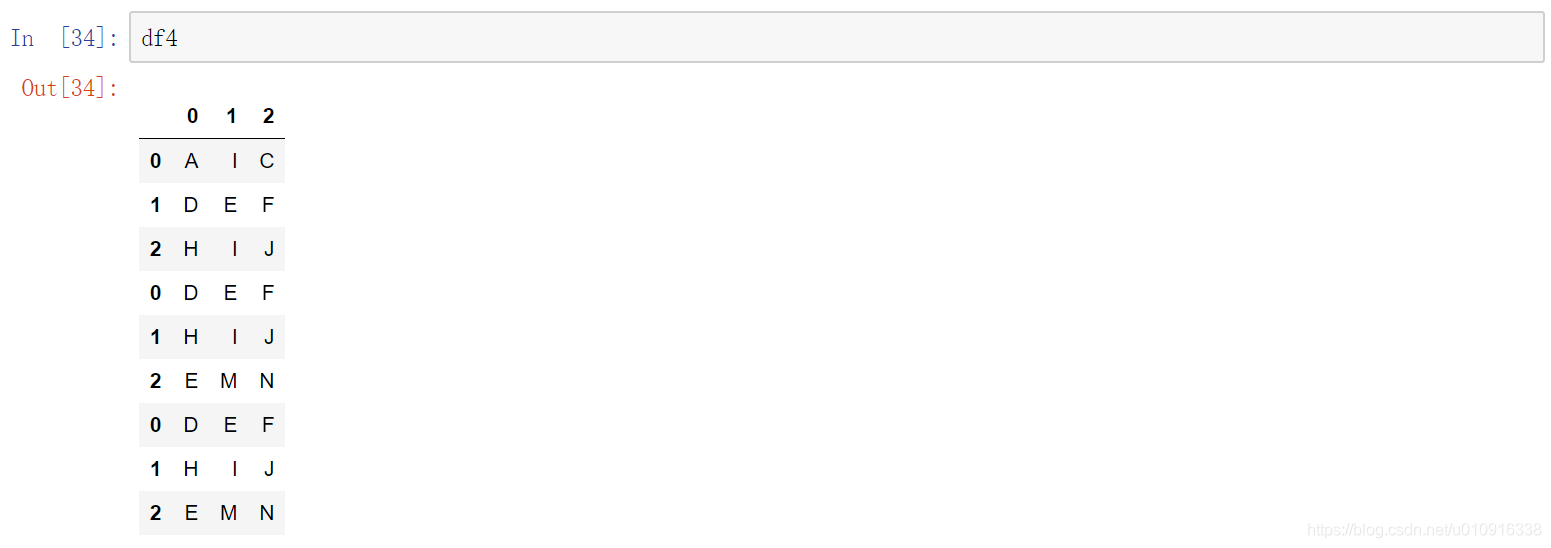
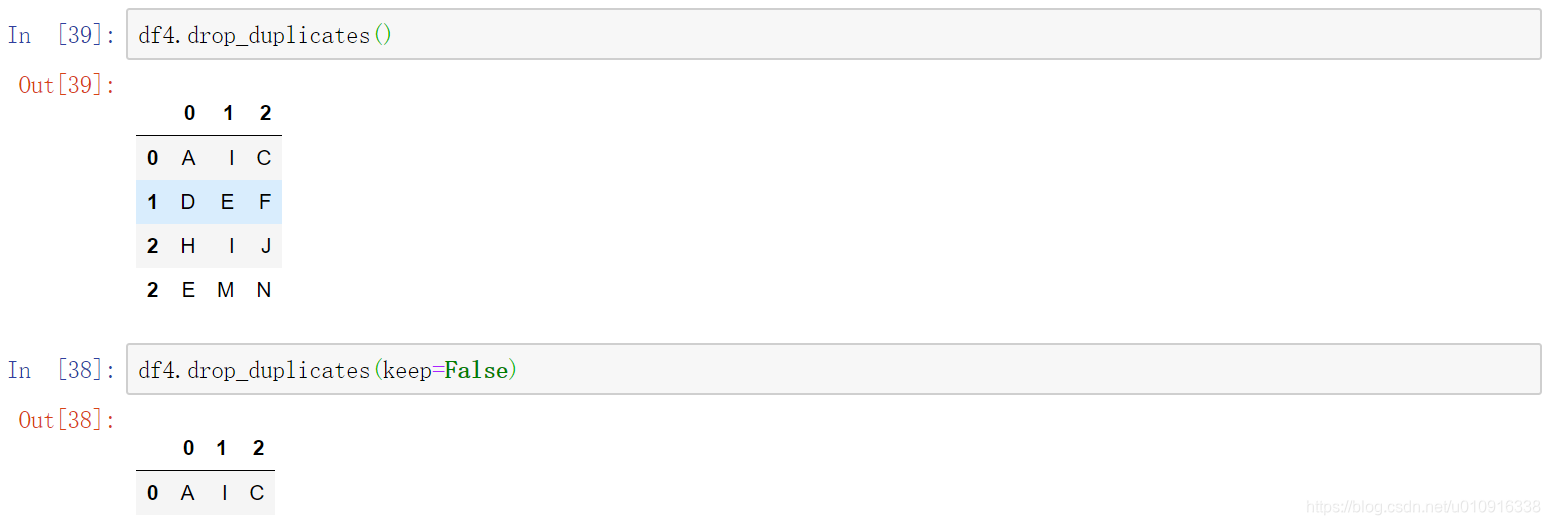
(3)inplace,默认=False该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
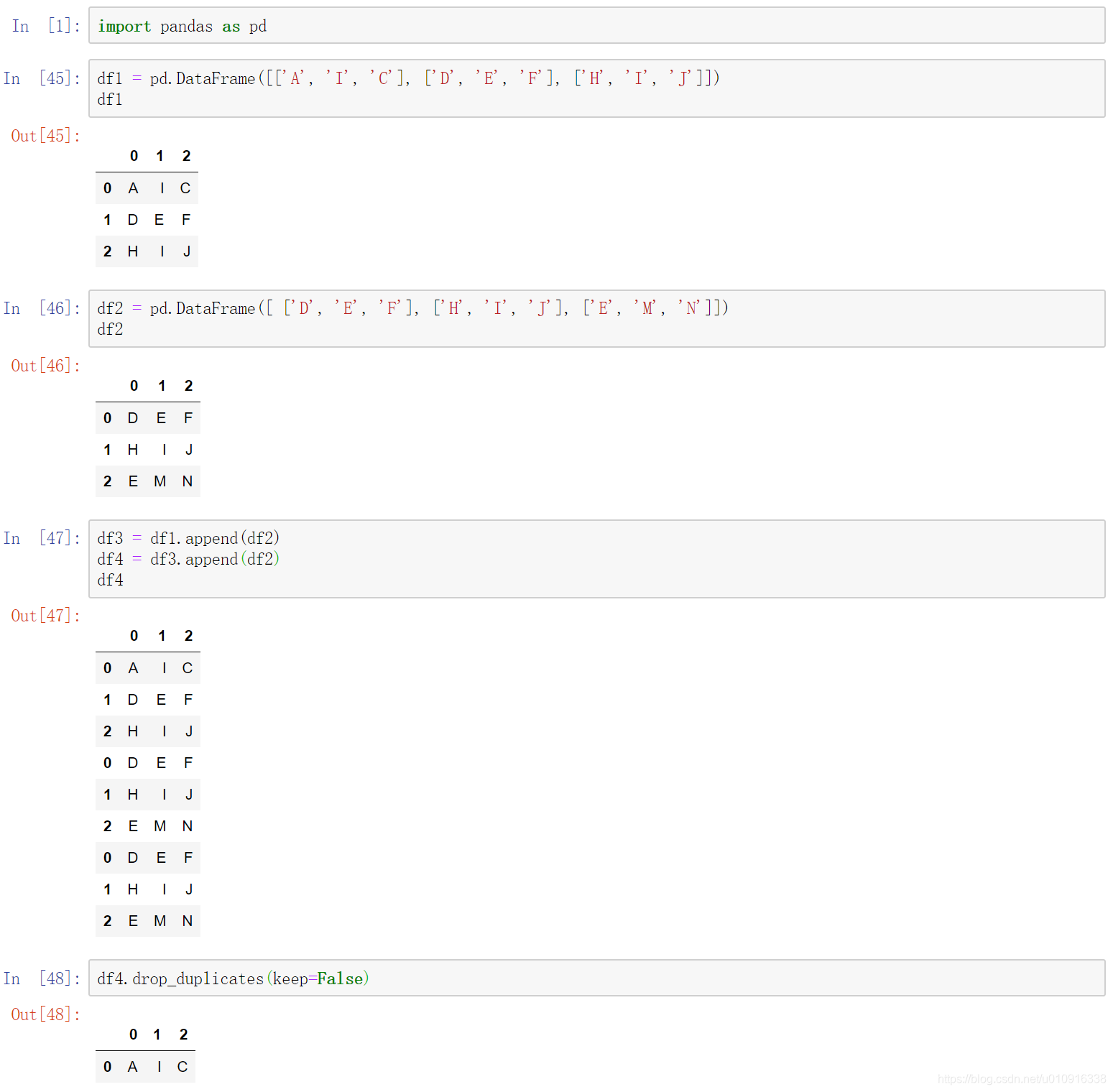
2.3 求dataframe差集
- append两次
- df.drop_duplicates(keep=False)删除全部重复项,一条不留
三、修改数据
3.1 df.fillna()填充空值
**DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, kwargs)
(1)value : 变量, 字典, Series, or DataFrame
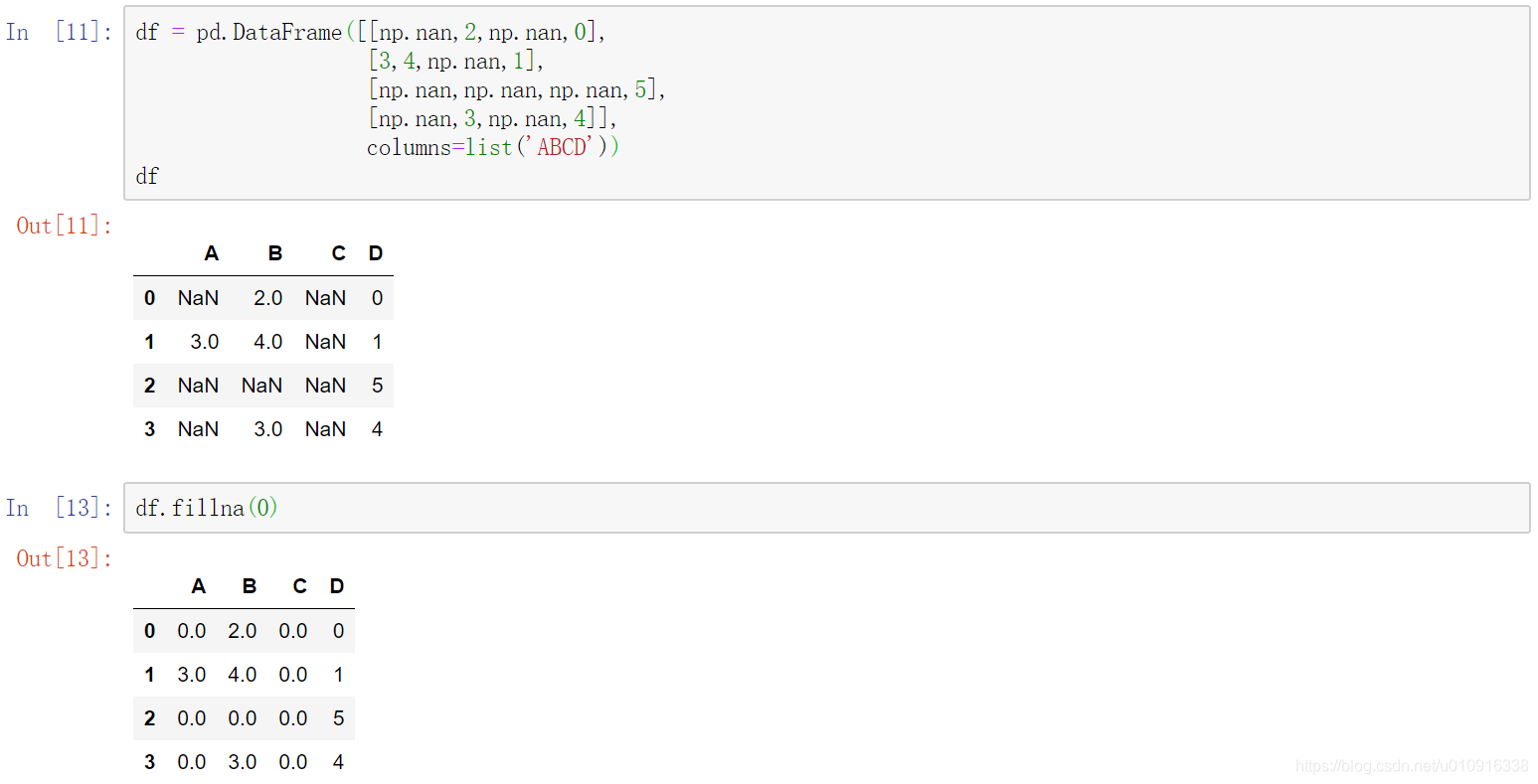
(2)method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
1,默认纵轴填充
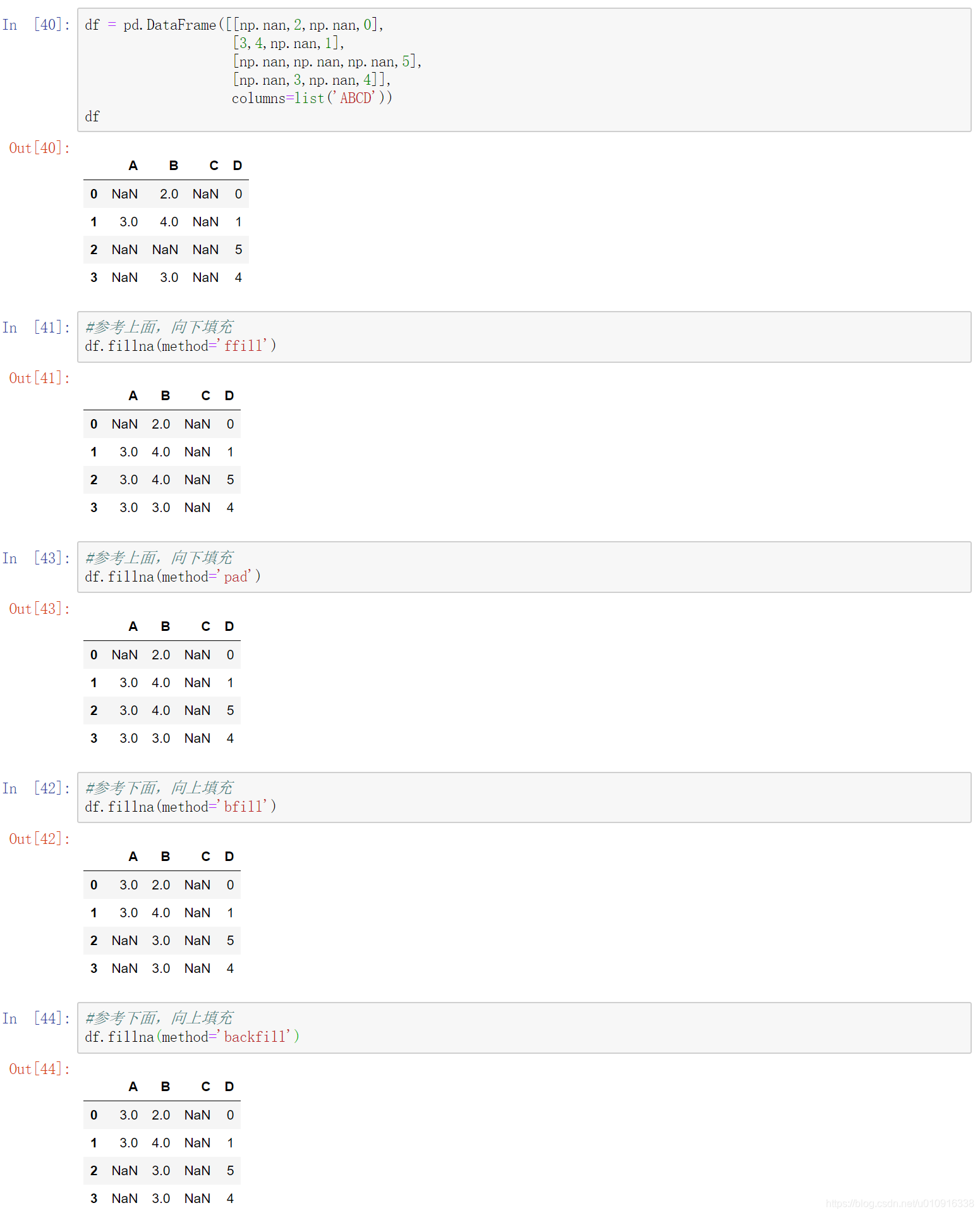
(3)axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
1,横轴填充
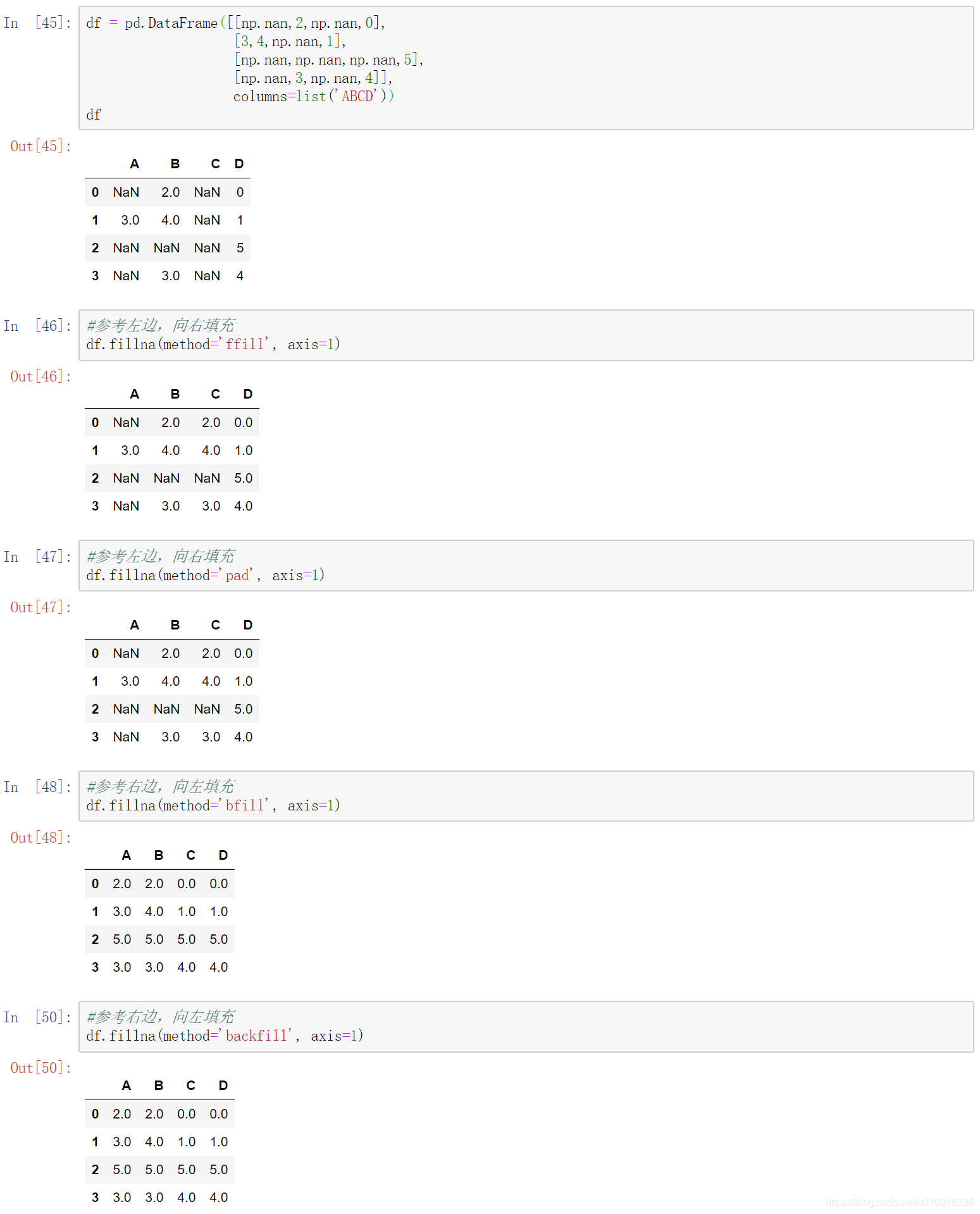
(4)inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
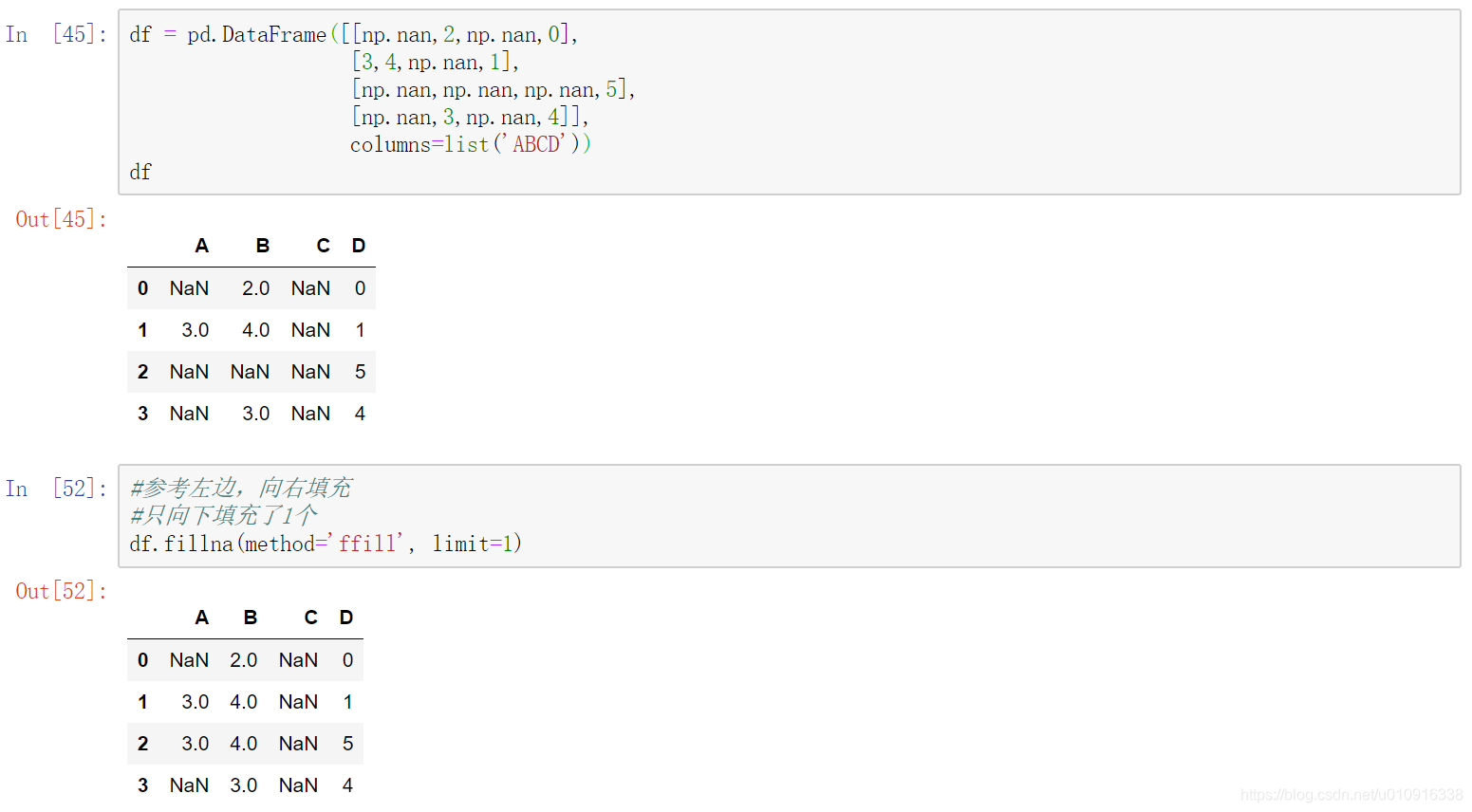
(5)limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
3.2 填充异常值
3.2.1 df.loc()通过布尔索引替换
布尔索引参考博文:https://blog.csdn.net/u010916338/article/details/105422449
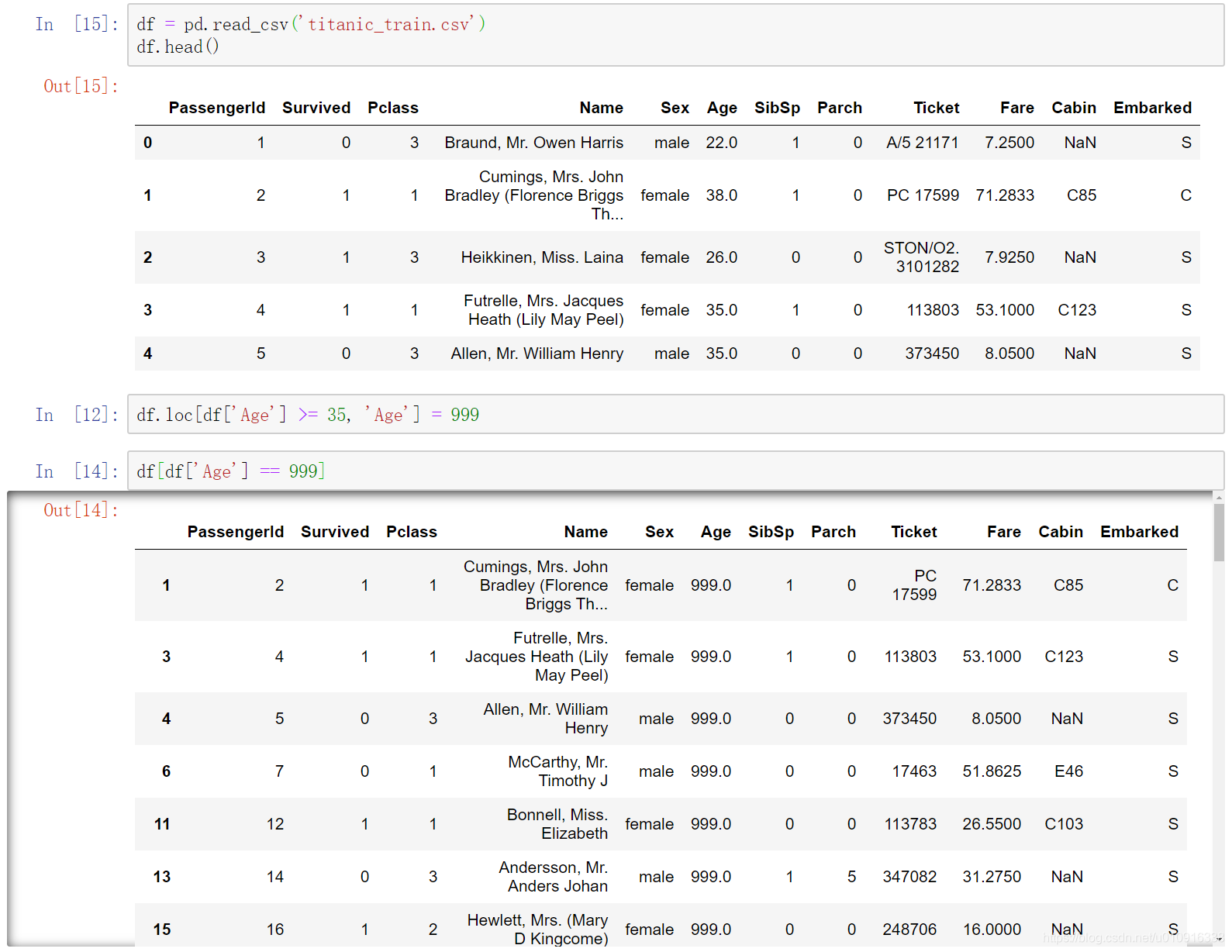
3.2.2 直接替换
注意:定位条件不能写反了,否则替换不成功
3.2.2.1 例1(正确)
df[‘Age’]指定替换数据的列,然后在Age列上通过布尔索引df[‘Age’] >= 35定位到需要替换的数据。
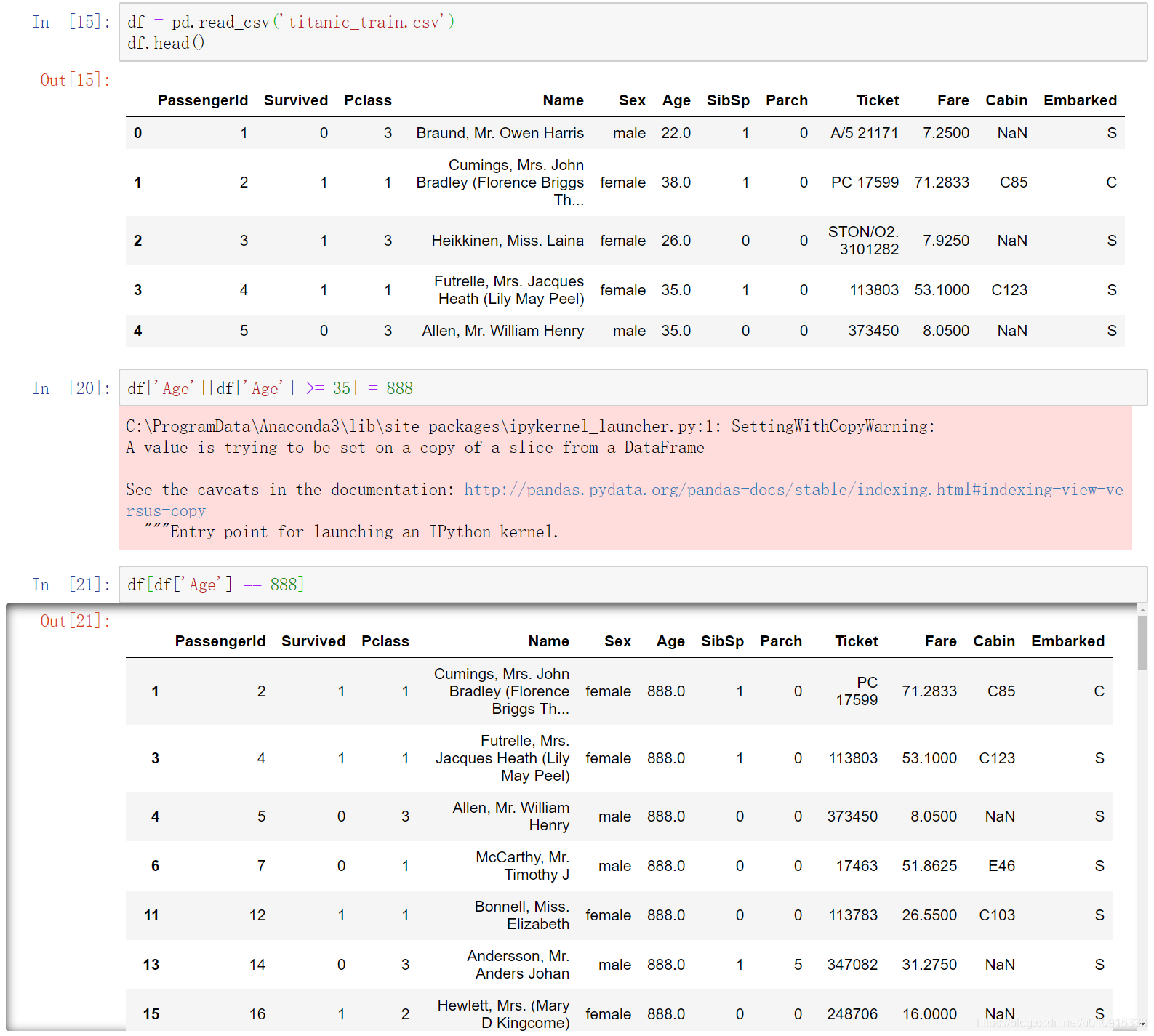
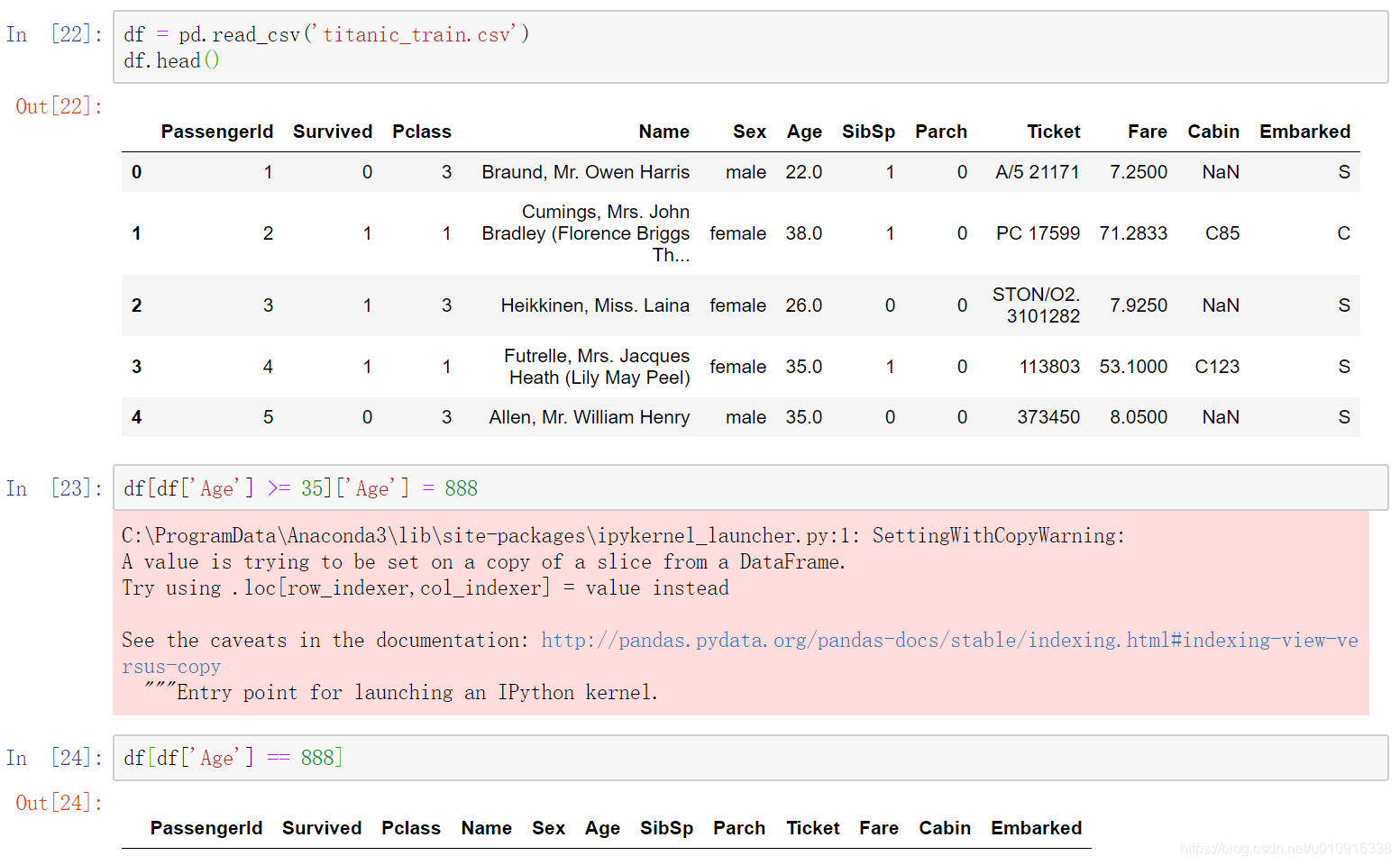
3.2.2.2 例2(错误)
df[df[‘Age’] >= 35]先拿到满足条件的矩阵,然后对该矩阵的Age列做赋值,不会对原始数据造成影响。
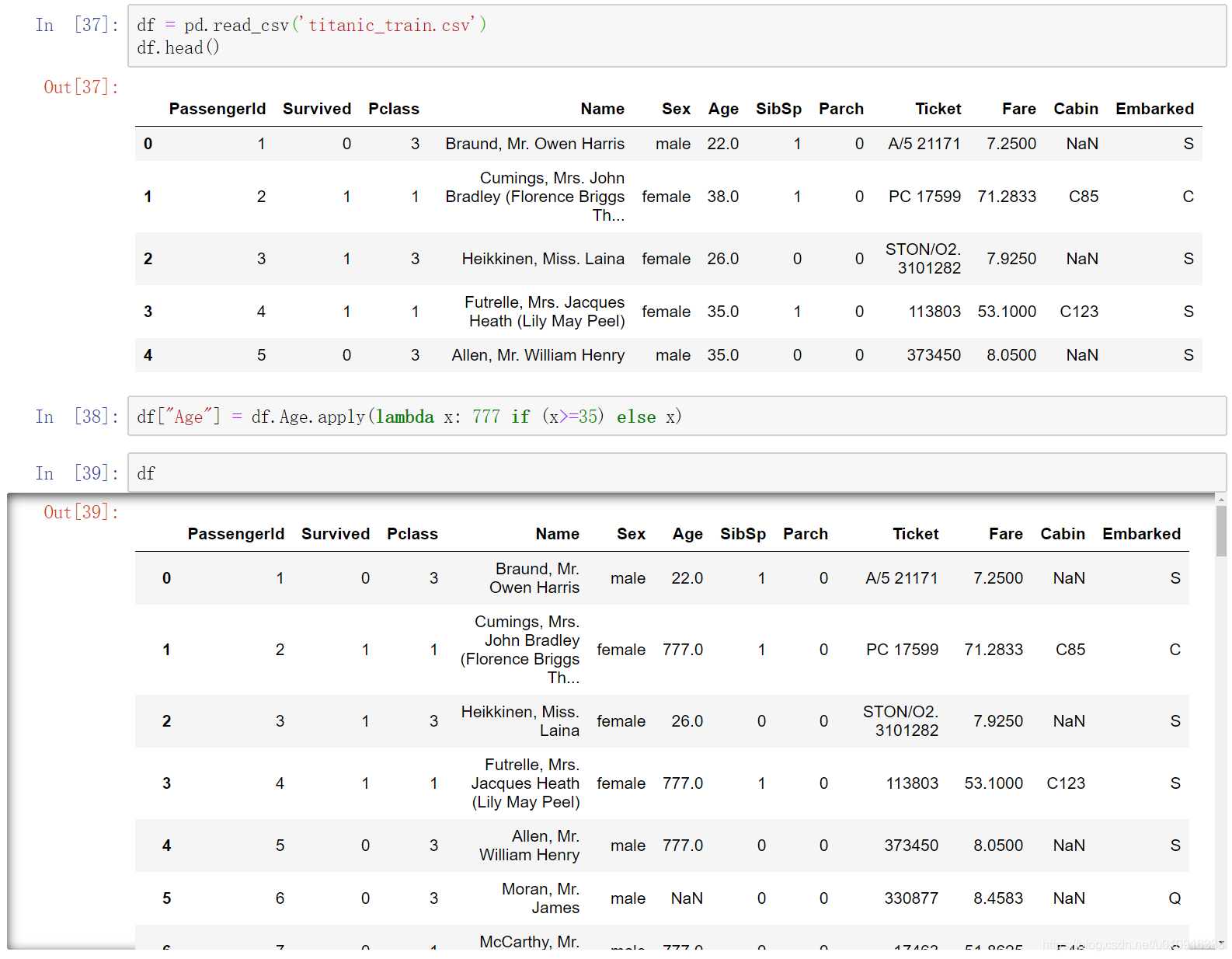
3.2.3 lamada表达式
注:lambda表达式也是先拿到Age列再根据条件判断逐个做替换
3.2.4 replace()
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.replace.html
四、查询数据
参考博文:https://blog.csdn.net/u010916338/article/details/105422449














 3112
3112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









