







最近在做一个算法实验:归并排序和快速排序的比较。
这两种算法在排序方面是非常非常的通俗的了,权威的文献和网上的相关文章也是一大堆,在这里就简单贴下代码,写下个人从这个实验中学到的东西。
先说说个人对这两个算法的理解:
归并排序,简单来说就是先将数组不断细分成最小的单位,然后每个单位分别排序,排序完毕后合并,重复以上过程最后就可以得到排序结果。
快速排序,简单来说就是先选定一个基准元素,然后以该基准元素划分数组,再在被划分的部分重复以上过程,最后可以得到排序结果。
两者都是用分治法的思想,不过最后归并排序的合并操作比快速排序的要繁琐。
下面是实验题目:
实验任务:
(1)用C/C++语言编程实现归并排序算法6.3 和快速排序算法6.6。对于快速排序,SPLIT中的划分元素采用三者A(low),A(high),A((low+high)/2)中其值居中者。
(2)随机产生20组数据(比如n=5000i,1≤i≤20)。数据均属于范围(0,105)内的整数。对于同一组数据,运行快速排序和归并排序算法,并记录各自的运行时间(以毫秒为单位)。
(3)根据实验数据及其结果来比较快速排序和归并排序算法的平均时间,并得出结论。
代码如下:
#include <iostream>
#include <time.h>
#define random(x) (double)rand() / RAND_MAX * 100000
using namespace std;
int *a_merge, *a_quick, *b;
int n;
int merge_count;
int quick_count;
/
// 计时部分 //
/
/* 停止计时,并输出运行时间和比较次数
* flag = 0代表归并排序
* flag = 1代表快速排序
*/
void stop_clock(clock_t start_t, int flag)
{
char *name = (flag == 0) ? "归并排序" : "快速排序";
int compare = (flag == 0) ? merge_count : quick_count;
clock_t stop_t = clock();
double time = stop_t - start_t;
cout<<endl;
cout<<name;
cout<<"排序用时:"<<time<<"ms"<<endl;
cout<<"比较次数:"<<compare<<endl;
}
/
// 基本函数 //
/
/* 输出数组a的内容 */
void output(int *a)
{
cout<<"数组a为:"<<endl;
for(int i = 0; i < n; i++)
{
cout<<a[i]<<" ";
}
cout<<endl;
}
/* 生成n个随机数 */
void randomGeneration(int n)
{
a_merge = new int[n];
a_quick = new int[n];
b = new int[n];
srand((int)time(0));
for(int i = 0; i < n; i++)
{
a_merge[i] = random(100000);
a_quick[i] = a_merge[i];
}
}
/
// 合并排序 //
/
/* 合并数组操作 */
void MERGE(int *a, int *b, int low, int mid, int high)
{
for(int k = low; k <= high; k++)
{
b[k] = a[k];
}
int s1 = low, s2 = mid + 1, t = low;
while(s1 <= mid && s2 <= high)
{
if(b[s1] <= b[s2])
{
a[t++] = b[s1++];
}
else
{
a[t++] = b[s2++];
}
merge_count++;
}
while(s1 <= mid)
{
a[t++] = b[s1++];
}
while(s2 <= high)
{
a[t++] = b[s2++];
}
}
/* 归并排序 */
void mergesort(int *a, int *b, int low, int high)
{
if(low >= high)
{
return;
}
int mid = (low + high) / 2;
mergesort(a, b, low, mid);
mergesort(a, b, mid + 1, high);
MERGE(a, b, low, mid, high);
}
void my_mergesort()
{
/* 运行归并排序算法, 并输出运行时间 */
clock_t start_merge = clock();
merge_count = 0;
mergesort(a_merge, b, 0, n - 1);
stop_clock(start_merge, 0);
}
/
// 快速排序 //
/
/* 交换a[i]和a[j]的值 */
void exchange(int *a, int i, int j)
{
int temp;
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
/* 设置用于划分的标准元素 */
void setReference(int *a, int low, int high)
{
quick_count += 2;
int mid = (low + high) / 2;
if(a[mid] < a[high])
{
if(a[low] < a[mid]) // a[low] < a[mid] < a[high]
{
exchange(a, low, mid);
}
else if(a[low] < a[high]) // a[mid] < a[low] < a[high]
{
}
else // a[mid] < a[high] < a[low]
{
exchange(a, low, high);
}
}
else
{
if(a[mid] < a[low]) // a[high] < a[mid] < a[low]
{
exchange(a, low, mid);
}
else if(a[low] > a[high]) // a[high] < a[low] < a[mid]
{
}
else // a[low] < a[high] < a[mid]
{
exchange(a, low, high);
}
}
}
/* 分割数组 */
int split(int *a, const int low, const int high)
{
int temp = 0;
// setReference(a, low, high);
int refer = a[low];
int i = low;
for(int j = low + 1; j <= high; j++)
{
if(a[j] <= refer)
{
i++;
// exchange(a, i, j);
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
quick_count++;
}
exchange(a, i, low);
return i;
}
/* 快速排序 */
void quicksort(int *a, int low, int high)
{
if(low < high)
{
int pos = split(a, low, high);
quicksort(a, low, pos - 1);
quicksort(a, pos + 1, high);
}
}
void my_quicksort()
{
/* 运行快速排序算法, 并输出运行时间 */
clock_t start_quick = clock();
quick_count = 0;
quicksort(a_quick, 0, n - 1);
stop_clock(start_quick, 1);
}
/
// 主函数 //
/
/* 主函数 */
int main()
{
int i, ch;
char choose = 'y';
while(choose == 'Y' || choose == 'y')
{
cout<<"请选择"<<endl;
cout<<"1.手动输入i, 生成一组i * 5000个随机数"<<endl;
cout<<"2.随机生成20组数据"<<endl;
cin>>ch;
if(ch == 1)
{
/* 输入整数i, 1 <= i <= 20 */
cout<<"请输入整数i, 1 <= i <= 20:";
cin>>i;
if(i <= 0 || i >= 21)
{
cout<<"输入出错"<<endl;
}
else
{
/* 生成n个随机数, n = 5000 * i, 每个随机数的范围在0到10^5之间 */
n = 5000 * i;
randomGeneration(n);
/* 归并排序 */
my_mergesort();
/* 快速排序 */
my_quicksort();
}
}
else if(ch == 2)
{
for(i = 1; i < 21; i++)
{
cout<<"-----------------------------------"<<endl;
n = 5000 * i;
cout<<n<<"个数排序结果:"<<endl;
randomGeneration(n);
my_mergesort();
my_quicksort();
}
}
else
{
cout<<"输入出错"<<endl;
}
/* 是否循环? */
cout<<endl<<"是否继续?y/n:";
cin>>choose;
}
return 0;
}实验结果:
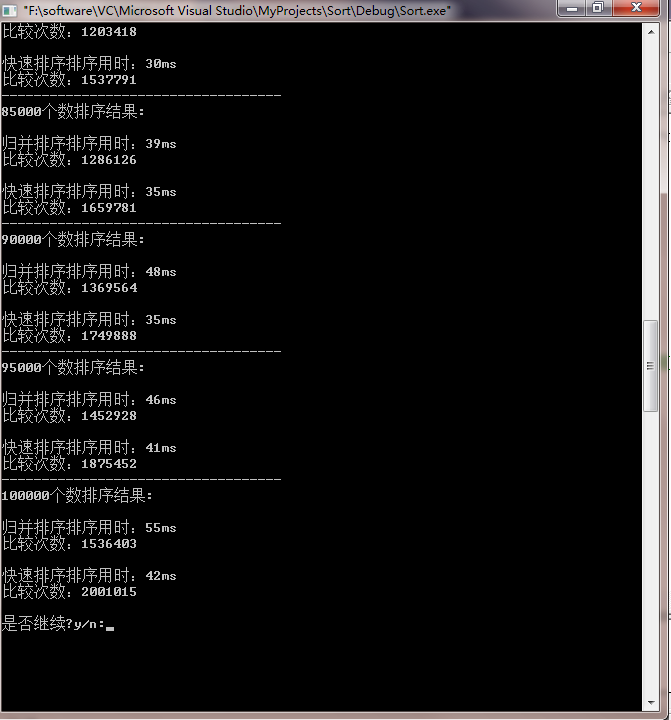
当数据量越来越大时,
归并排序:比较次数少,速度慢。
快速排序:比较次数多,速度快。
快速排序的优势越来越明显。
原因分析:个人认为是当数据量越来越大时,尽管归并排序的比较次数较少,但是归并排序后期的合并操作所花费的时间便越来越大,合并操作对整体的效率影响越来越明显,包括后面大量数据的赋值操作等。所以当数据量变大时,不需要专门合并的快速排序的优势就变得越发明显。
那么我从这个实验学到了什么?
代码中快速排序的split函数代码如下:
/* 分割数组 */
int split(int *a, const int low, const int high)
{
int temp = 0;
// setReference(a, low, high);
int refer = a[low];
int i = low;
for(int j = low + 1; j <= high; j++)
{
if(a[j] <= refer)
{
i++;
// exchange(a, i, j);
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
quick_count++;
}
exchange(a, i, low);
return i;
}修改成:
/* 分割数组 */
int split(int *a, const int low, const int high)
{
int temp = 0;
// setReference(a, low, high);
int refer = a[low];
int i = low;
for(int j = low + 1; j <= high; j++)
{
if(a[j] <= refer)
{
i++;
exchange(a, i, j);
/*
temp = a[i];
a[i] = a[j];
a[j] = temp;
*/
}
quick_count++;
}
exchange(a, i, low);
return i;
}也就是将交换操作变成函数调用方法。再Run一下看看:

在100000个数的情况下快速排序居然比修改前的程序慢了接近20ms。这个问题困扰了我好久,我之前一直都找不出为什么我的程序中快速排序比归并排序要慢,原因就在这里。
这也是我从这个算法中学到的最重要的东西:频繁的函数调用大大降低了算法的效率。
看来函数是不能滥写的,这可能会大大降低程序运行效率,以后必须多加注意。















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









