







 本文介绍了机器阅读理解中doc和query的表示方法。对于doc,常见方法包括视作单词流序列并利用RNN建模,以及通过Attention计算得到整体的Doc Embedding。对于query,除了采用doc的表示方法外,还有结合双向RNN的尾部节点隐层状态来表征问题的整体语义。这些表示方法在不同场景下各有优势。
本文介绍了机器阅读理解中doc和query的表示方法。对于doc,常见方法包括视作单词流序列并利用RNN建模,以及通过Attention计算得到整体的Doc Embedding。对于query,除了采用doc的表示方法外,还有结合双向RNN的尾部节点隐层状态来表征问题的整体语义。这些表示方法在不同场景下各有优势。
一、对于doc的表示方法
- 方法一:
最常见的一种方法是将一篇文章看成一个有序的单词流序列,如下模型所示,图中的每个圆圈代表某个单词的神经网络语义表达,图中的BiRNN代表双向RNN模型。
在这个序列上使用RNN来对文章进行建模表达,每个单词对应RNN序列中的每个时间步的输入,RNN的隐层状态代表融合了本身单词以及其上下文语义的语言编码。
这种表示方法的特点就是,它不对文章的整体语义进行编码,而是对每个单词及其上下文语义进行编码,在实际的使用过程中是使用每个单词的RNN隐层状态来进行相关计算。

方法一往往在机器阅读理解系统的原始输入部分对文章进行表示,因为对于很对阅读理解任务来说,本质上是从文章中推导出某个概率最大的单词作为问题的答案,所以文章以单词的形式来表征非常自然。 - 方法二:
另一种常见的文章内容表达方式则是从每个单词的语义表达推导出文章整体的Doc Embedding表达,这种形式往往是在对问题和文章进行推理的内部过程中使用的表达方式。表达过程如下:

图中模型的具体表示含义是,类似于上一个图,先用双向RNN来对每个单词及其上下文进行语义表征,形成隐层状态表示,然后对于向量的每一维数值,乘以某个系数,这个系数代表了单词对于整个文章最终语义表达的重要程度,将每个单词的系数调整后的隐层状态累加即可得到文章的word embedding 语义表达,而每个单词的权重系数通常是由Attention计算机制来计算获得。
二、对于query的表达方式
- 方法一和方法二:
对于机器阅读理解中的问题来说,有三种常见的语义表达方式
如果将query看做一种特殊的doc的话,很明显doc的语义表达方式同样也可以用来表征query的语义,也就是类似于doc的表示方法的方法一和方法二,在此就不再赘述
- 方法三:
query的第三种表示方法如下图所示
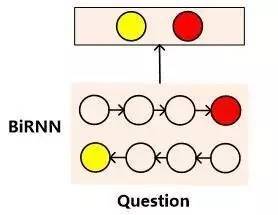
方法三可以看作是在方法一的基础之上的改进模型,也是NLP任务中表达句子语义的最常见的表达方式。首先类似于方法一,使用双向RNN来表征每个单词及其上下文的语义信息。
对于正向RNN来说,其尾部单词(句尾词)RNN隐节点代表了融合了整个句子语义的信息;而反向RNN的尾部单词(句首词)则逆向融合了整个句子的语义信息,将这两个时刻RNN节点的隐层状态拼接起来则可以表征问题的整体语义
理论上对于query的表示方法三也可以用来表示doc的语义信息,但是一般不会这么用,主要原因就是doc往往都比较长,RNN对于太长的内容表达能力不足,所以类似方法三的方法会存在大量的信息丢失,而query一般来说都是比较短的一句话,所以用方法三是比较合适的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









