







零之前言
首先我们要准备的工具:Python、Fiddler(抓包工具)、Python的requests库。
然后我们需要搞清楚一些概念cookie、状态码、爬虫的原理、请求方式等基础知识。
然后,冲冲冲!!!
教程仅供学习,因为太有借鉴性了,请勿用于非法用途
一.模拟登录
抓包我们主要抓什么? 抓其中的cookie操作,session操作,表单提交,页面跳转等
我们打开抓包工具进行一次模拟登录:
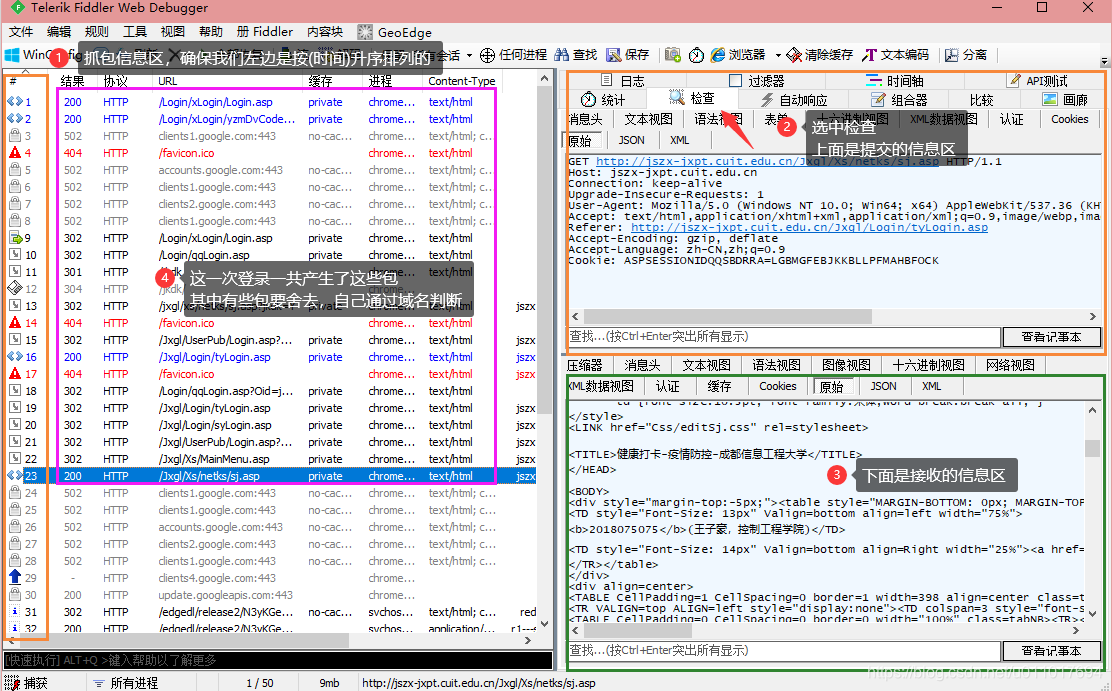 右上方的提交信息区,一般就是我们写代码的右边的提交部分,右下方的接收信息区,一般就是我们提交后的返回。
右上方的提交信息区,一般就是我们写代码的右边的提交部分,右下方的接收信息区,一般就是我们提交后的返回。
以下是流程与分析(按每个包来设置小标题)
1
先进入我们的登录界面:http://login.cuit.edu.cn/Login/xLogin/Login.asp
第一个包是GET包,我们没有提交数据。它会返回我们登录界面,其中返回了一串cookie(记为cookie1)、一个验证码的id,先记一下。
2
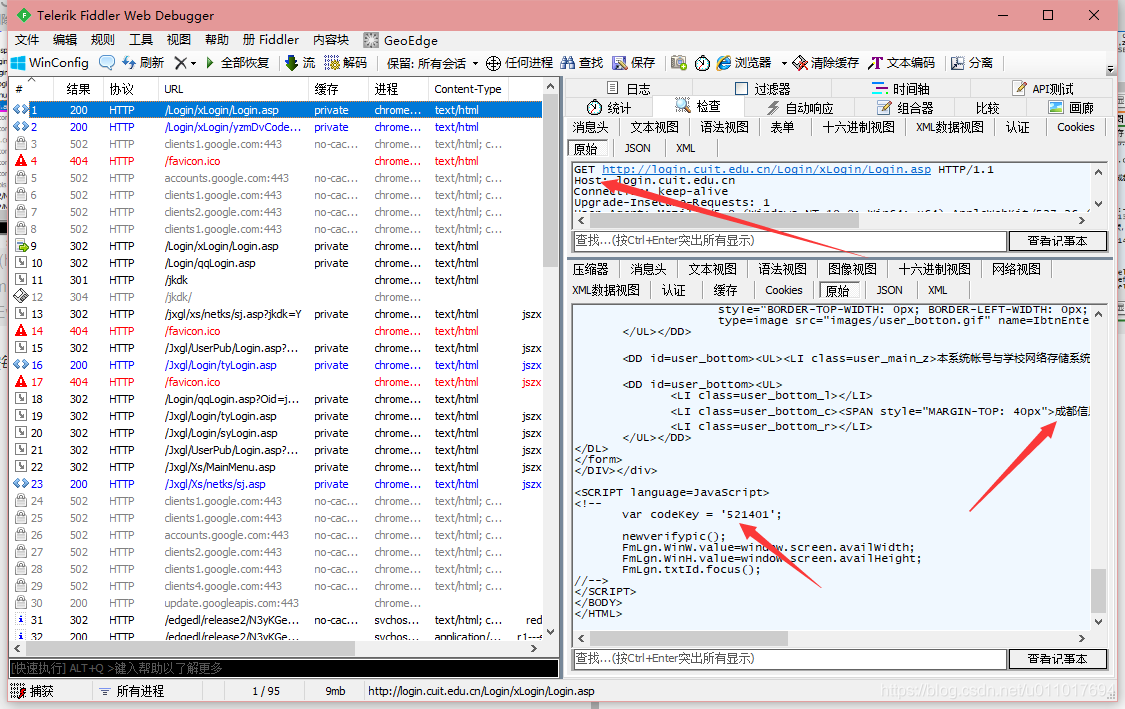
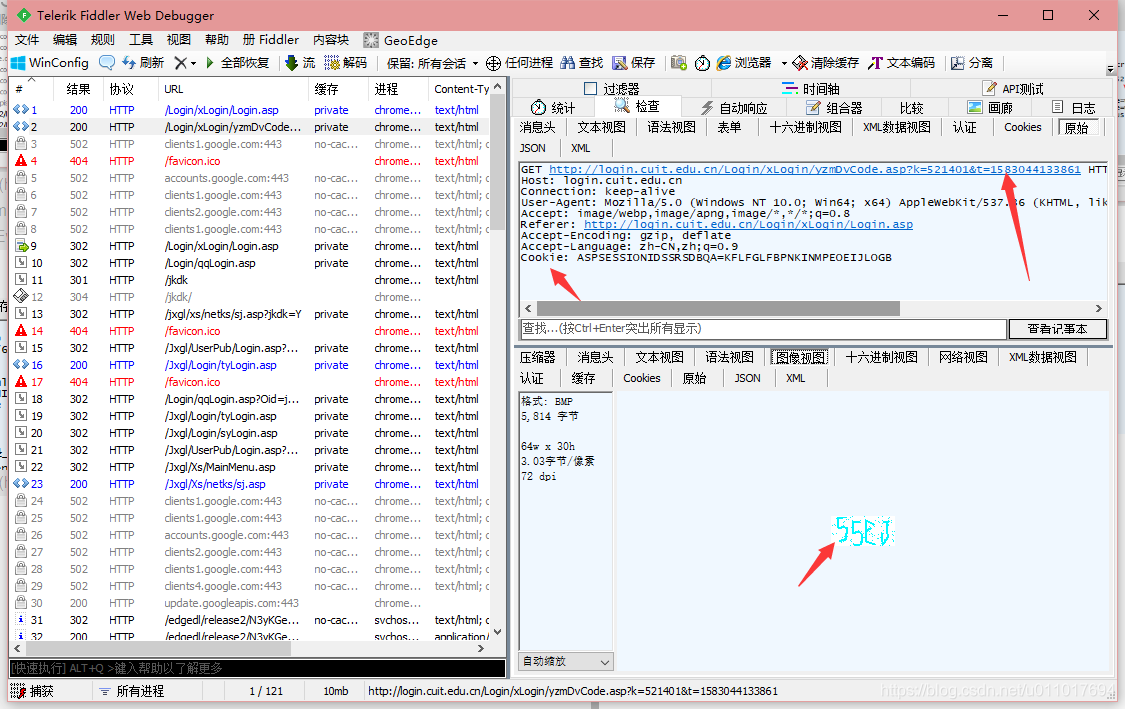
第二个包是我们的获取验证码的包,其组成是一段固定的网址+第一步获取的验证码id+一个js计算的时间戳。但是这几天的登录,不需要验证码正确,所以我们可以忽略获取验证码了。
3
第三步是我们的POST提交我们的登录数据,因为我们刚才输入的学号、密码出现在了cookie的下面。
返回了一个302的跳转,跳转到其他页面
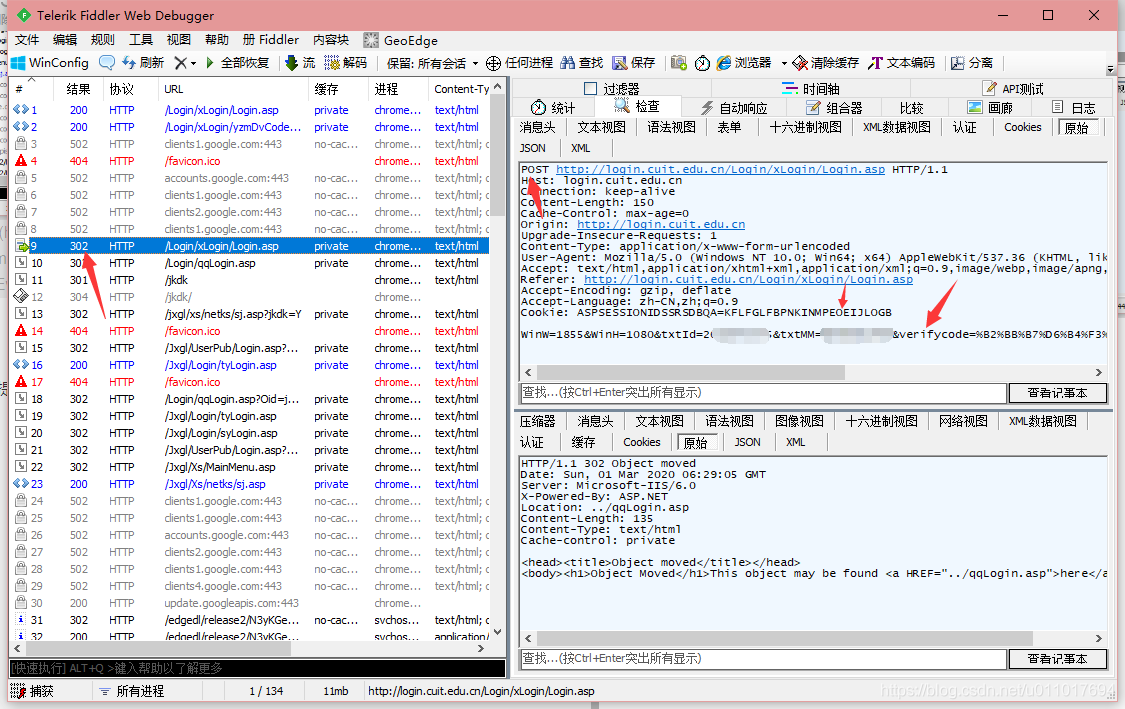
4
第四步,访问了一个网址,提交了cookie,又跳转到下一个界面。
多说一句,这个跳转是用于存放你登录后跳转到哪儿的地址。

5
一个跳转

6
一个跳转
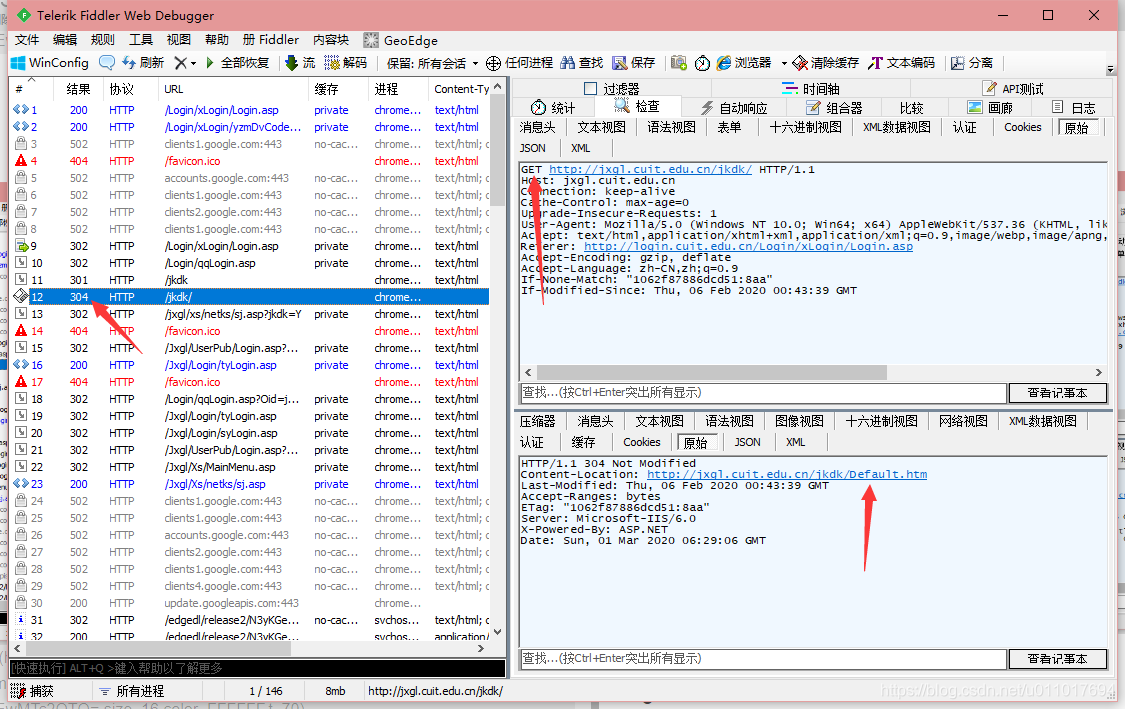
7
一个新跳转,但是在此界面设置了新的cookie!(记为cookie2) 这是常见的设cookie后跳转,代码要多加处理。
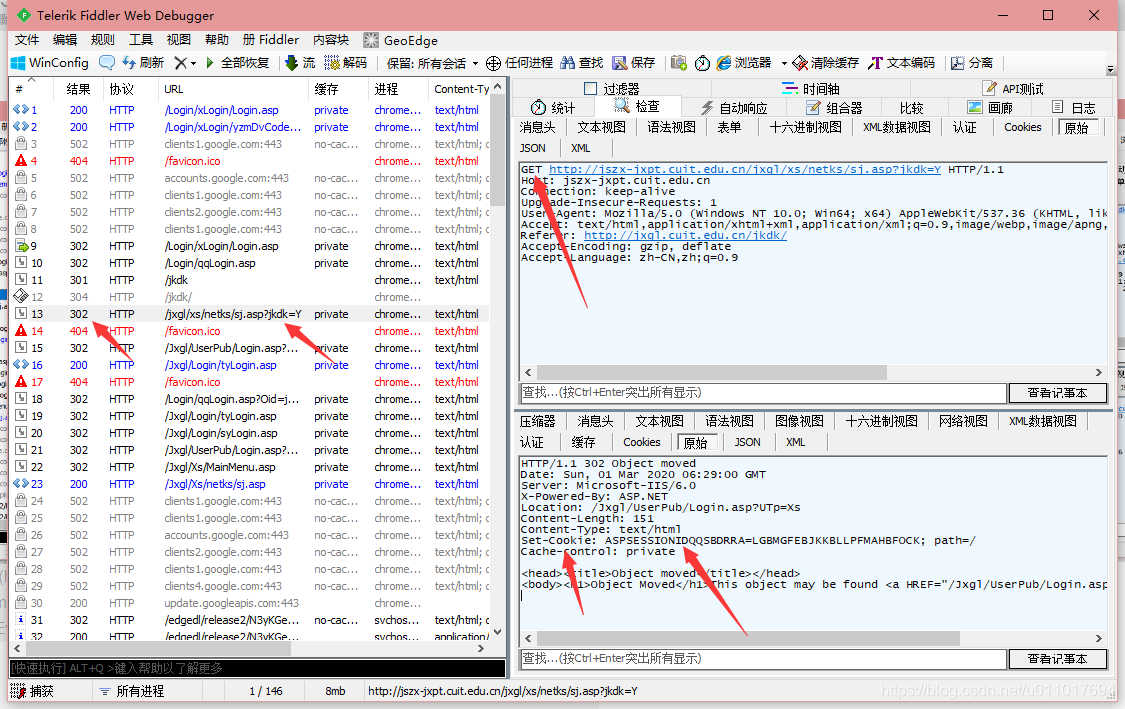
8
又是一个跳转,但是注意,使用的是cookie2。
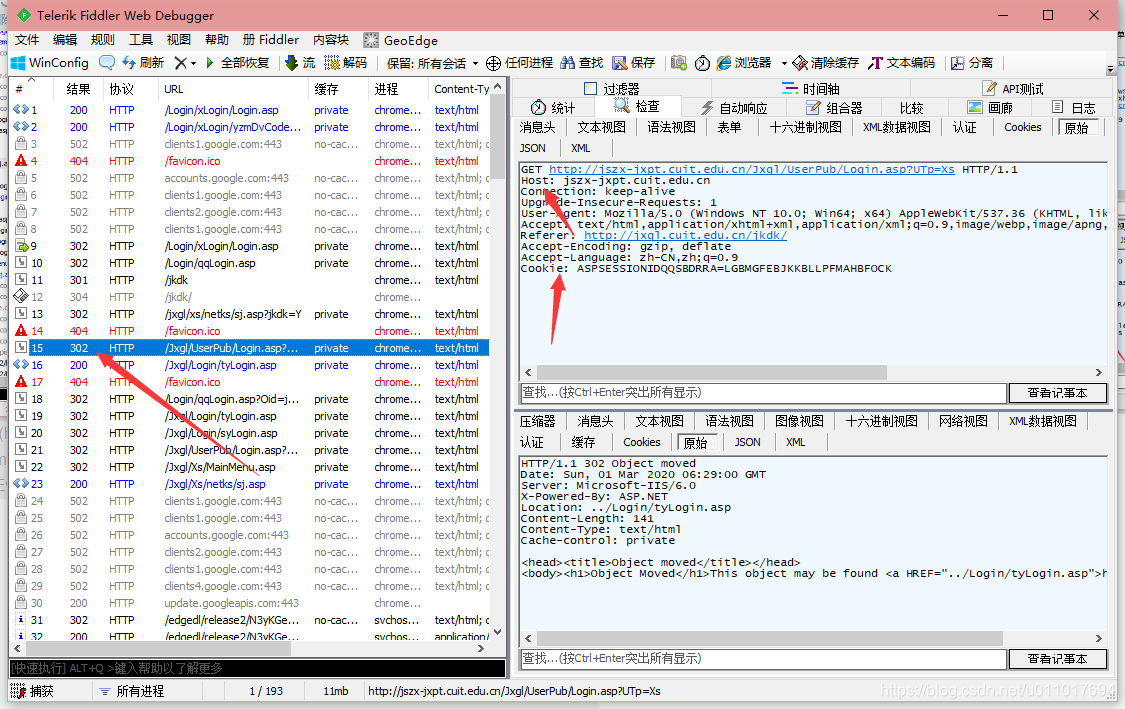
9
未登录?需要重新登录?我估计是因为学校每个版块儿的登录不同,打卡的登录地址是登录到计算中心,所以跨平台的登录,需要跳转刷新一下才行。

10
然后跳转访问我们9中返回的地址,得到新的登录地址,但是注意,此处的cookie又使用了原来的cookie1
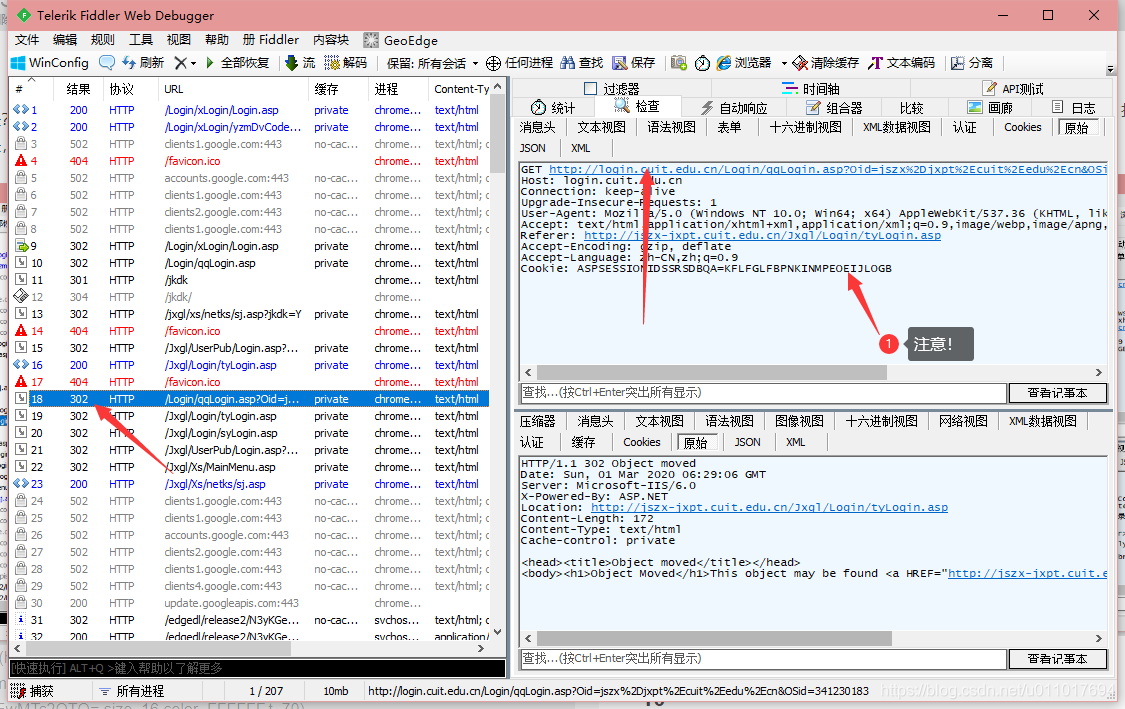
11
上一个页面的跳转后,又使用了cookie2?此处有坑,如果两个连续跳转之间cookie发生了变化,我们需要断开跳转,分开处理
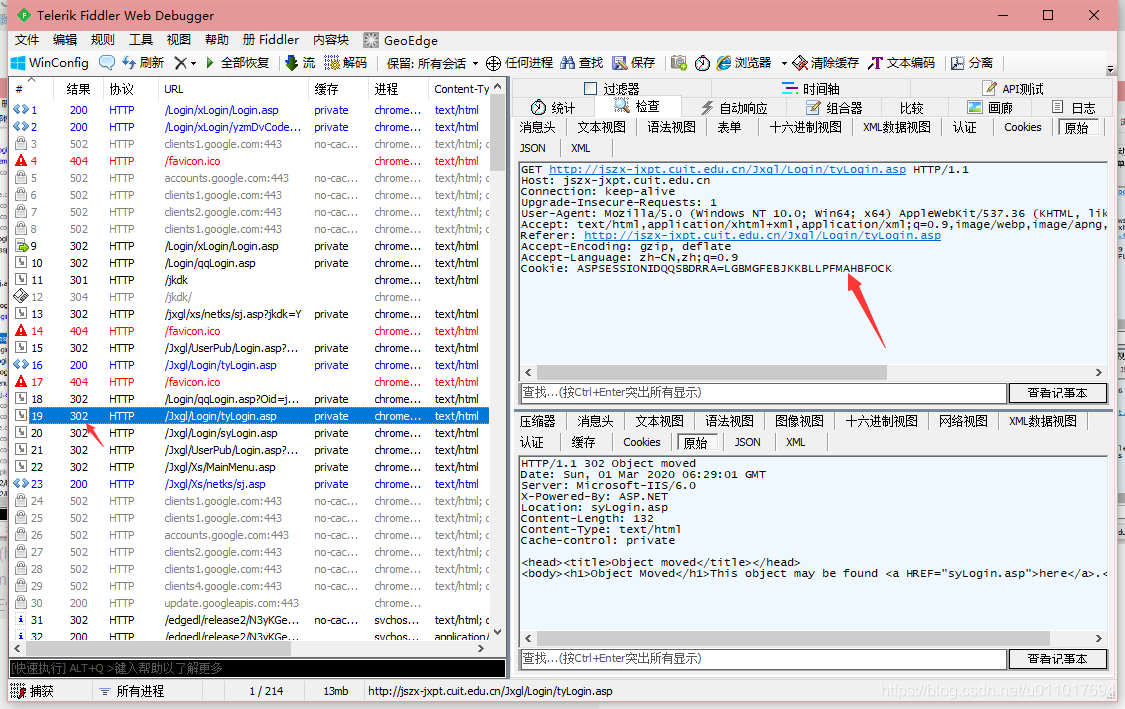
12
跳转
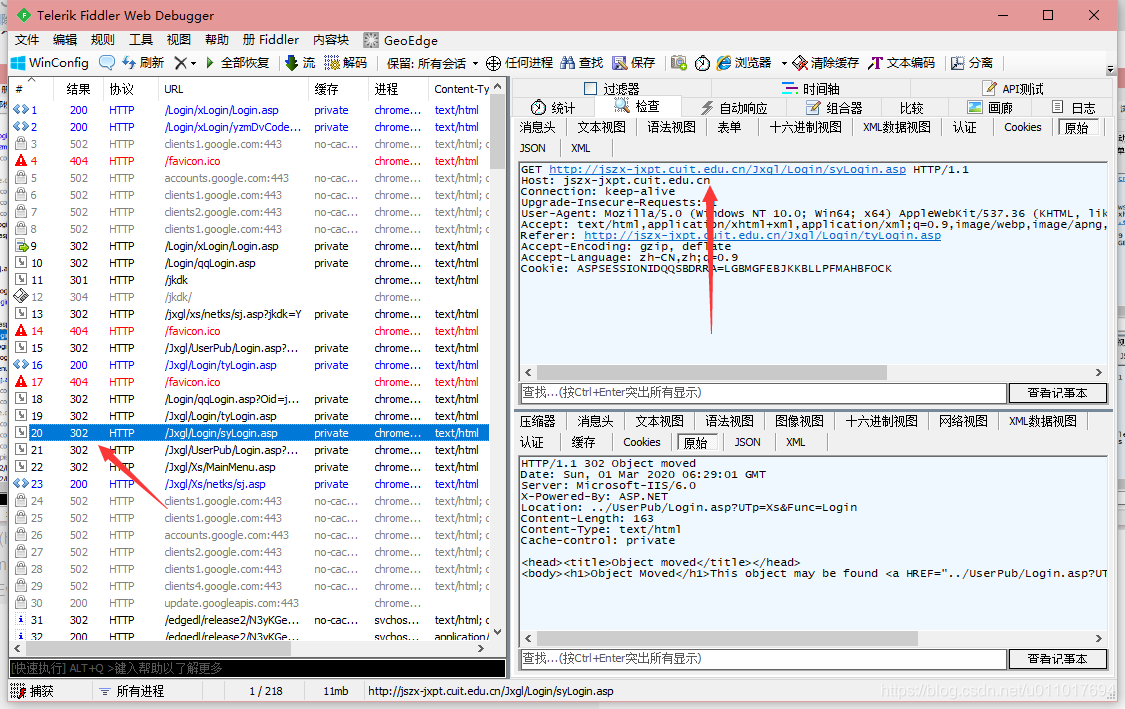
13
跳转
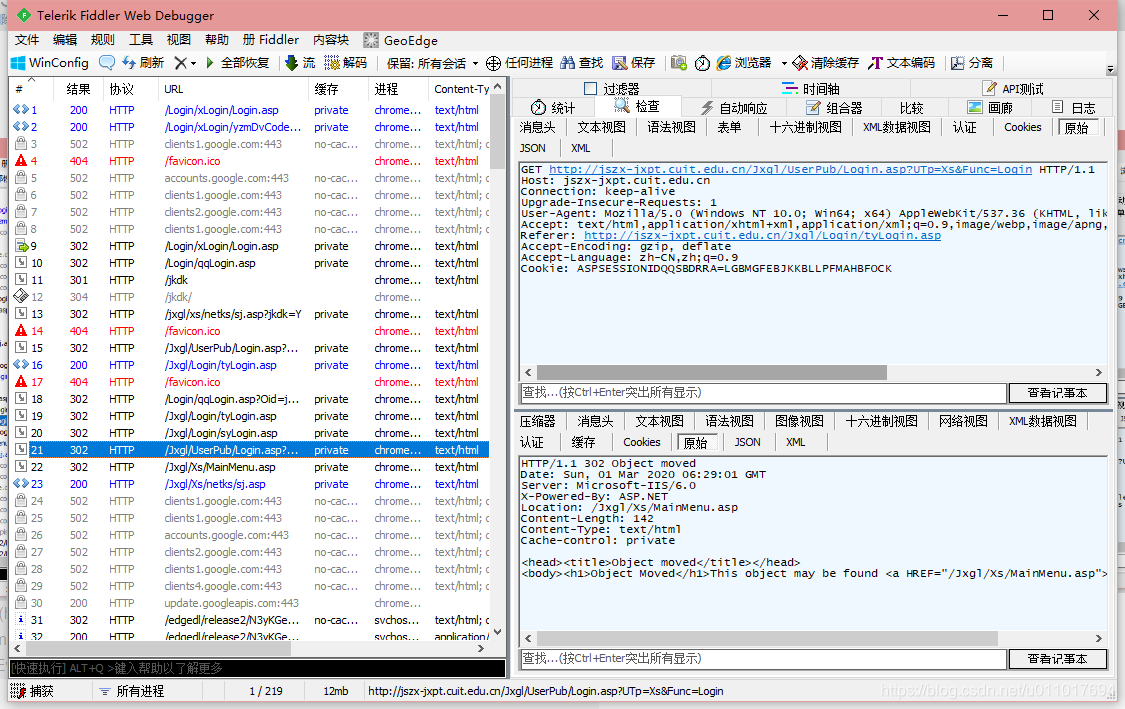
14
跳转
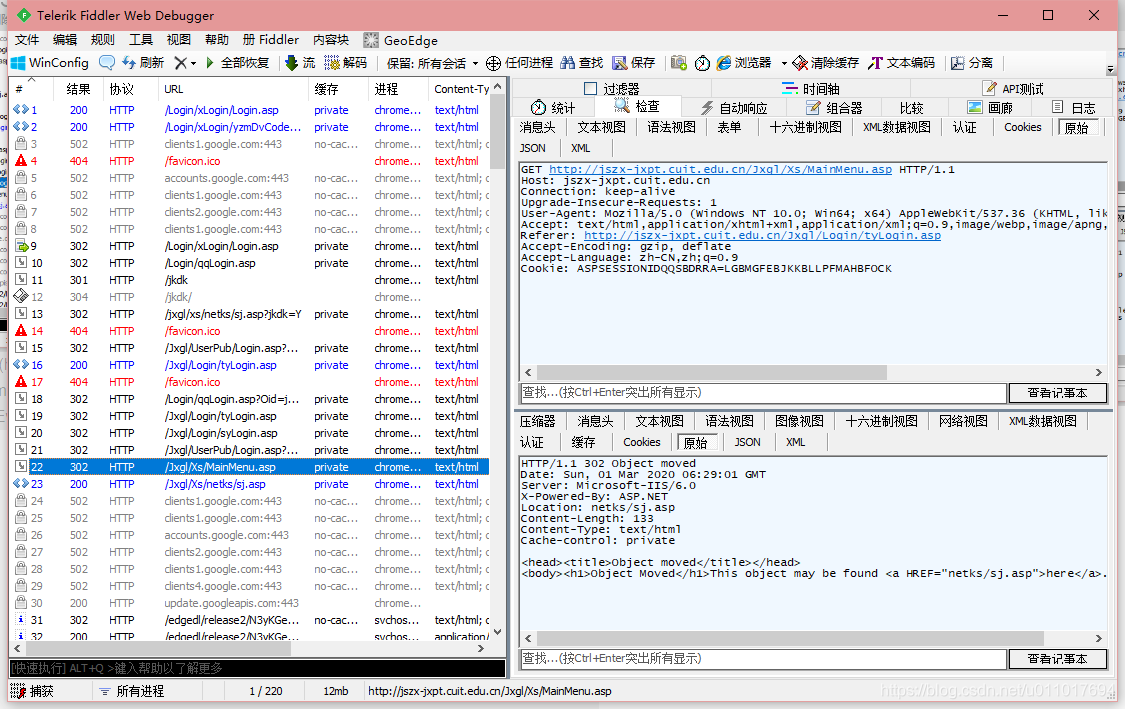
15
获得到了打卡界面
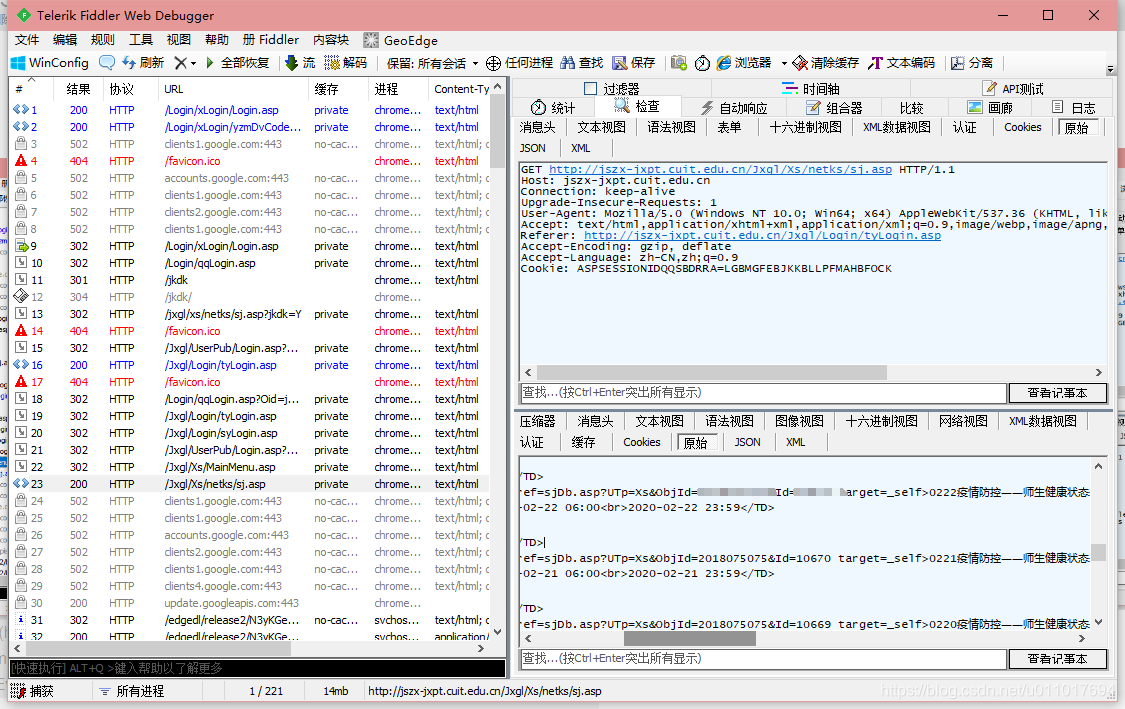
二.代码编写
0.核心思想
因为爬虫是模拟我们的操作去访问网页的,所以你用写出来的登录过程,应该和我们的访问过程**一模一样!**
以下的小标题对应上节的图片登录包顺序,代码分开写,最后也会留完整代码的。
1~2
导入要用的包
import requests
import re
登录的地址和包头:包头的获取方法,复制,去掉GET或POST那行
login_url = 'http://login.cuit.edu.cn/Login/xLogin/Login.asp'
login_header = {
"Accept": "image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, application/x-ms-xbap, */*",
"Referer": "http://login.cuit.edu.cn/Login/xLogin/Login.asp",
"Accept-Language": "zh-CN",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Proxy-Connection": "Keep-Alive",
"Pragma": "no-cache",
"Host": "jxgl.cuit.edu.cn",
}
获取cookie字符串和验证码代码
res = requests.get(login_url, headers=login_header)
cookie1 = res.cookies
str_cookie1 = ''
for key, value in cookie1.items():
str_cookie1 = "%s=%s" % (key, value)
codekey = re.findall(r"(?<=var codeKey = ').*?(?=';)", res.text)
# print(cookie1, str_cookie1, codekey)
打印查看结果:
# <RequestsCookieJar[<Cookie ASPSESSIONIDSSRSDBQA=EJAGGLFBDCMLJOFHJKBLPDHM for jxgl.cuit.edu.cn/>]> ASPSESSIONIDSSRSDBQA=EJAGGLFBDCMLJOFHJKBLPDHM ['548764']
采坑说明:因为request类中的cookie是专门的一个类,其中包含了其可用的网址,最开始我没注意,以为它就是单纯的字符串,导致了后面有一个GET提交传递不了cookiePython建议自定义cookie字符串。
3
登录
WinW=1855&WinH=1080&txtId=***&txtMM=***&verifycode=%B2%BB%B7%D6%B4%F3%D0%A1%D0%B4&codeKey=521401&Login=Check&IbtnEnter.x=0&IbtnEnter.y=0
这是原POST登录数据,我们需要将它做成我们的登录Python字典:
login_data = {
"WinW": "1855",
"WinH": "1080",
"txtId": studentid,
"txtMM": password,
"Login": "Check",
"IbtnEnter.x": "60",
"IbtnEnter.y": "37",
"verifycode": "1",
"codeKey": codekey[0],
}
因为这几天验证码不需要识别正确,所以verifycode这一行,我们可以不传值。
res = requests.post(url=login_url, data=login_data, cookies=cookie1, headers=login_header)
res.encoding = "gbk" # 网站编码是GB2312,写gbk就行
#print(res.text)
查看结果:
<html><head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<meta http-equiv="refresh" content="0;URL=http://jszx-jxpt.cuit.edu.cn/jxgl/xs/netks/sj.asp?jkdk=Y">
<title>成都信息工程大学→疫情防控→健康打卡</title></head>
<body>
</body>
</html>
4~6
几个不用管的跳转,因为没有更改cookie或者提交数据,在最终的跳转结果中,出现了7的网址,所以我们提取7的链接(虽然这个链接是固定的,但是最好还是提取一下吧)
20.3.3更新 这句代码只有在打开Fiddler的时候有效,所以就不获取跳板链接了,直接用下面固定的地址
jkdk_url = re.findall(r"(?<=;URL=).*?(?=">)", res.text)
# print(jkdk_url[0])
结果:
# http://jszx-jxpt.cuit.edu.cn/jxgl/xs/netks/sj.asp?jkdk=Y
7
此处设置了一个cookie后,302跳转。如果我们直接获取返回的response中的cookie,它是获得跳转最终的结果,而不是中间页面的结果,所以我们需要禁止它跳转,且或得一个cookie,并且获得其跳转的地址。
res = requests.get(url="http://jszx-jxpt.cuit.edu.cn/jxgl/xs/netks/sj.asp?jkdk=Y", headers=jkdk_header, allow_redirects=False)
cookie2 = res.cookies
jump_url = re.findall(r"(?<=<a HREF=\").*?(?=\">here)", res.text)
jump_url[0] = "http://%s%s" % (jkdk_header["Host"], jump_url[0])
# print(cookie2, jump_url[0])
# <RequestsCookieJar[<Cookie ASPSESSIONIDQQSBDRRA=DBKMGFEBHPPAFMIKFADNBKEI for jszx-jxpt.cuit.edu.cn/>]>
# http://jszx-jxpt.cuit.edu.cn/Jxgl/UserPub/Login.asp?UTp=Xs
8~9
用获取到的cookie2 进行跳转,并获取链接
res = requests.get(url=jump_url[0], cookies=cookie2, headers=jkdk_header)
login_url_new = re.findall(r"(?<=;URL=).*?(?=\">)", res.text)
# print(login_url_new[0])
# http://login.cuit.edu.cn/Login/qqLogin.asp?Oid=jszx%2Djxpt%2Ecuit%2Eedu%2Ecn&OSid=341232539
10
使用cookie1访问,且需要禁止重定向,因为第11步使用的cookie2,我们得手动更换cookie并访问。
login_header_new = {
"Host": "login.cuit.edu.cn",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://jxgl.cuit.edu.cn/jkdk/",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": str_cookie1 # cookie是包含在提交头里的,因为cookie1 不能在这个地址使用,所以用这种方式提交cookie
}
res = requests.get(url=login_url_new[0], headers=login_header_new, allow_redirects=False)
final_url = re.findall(r"(?<=<a HREF=\").*?(?=\">here)", res.text)
# print(final_url[0])
# http://jszx-jxpt.cuit.edu.cn/Jxgl/Login/tyLogin.asp
11~15
更换cookie,提交,自动获得打卡界面:
final_header = {
"Host": "jszx-jxpt.cuit.edu.cn",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://jszx-jxpt.cuit.edu.cn/Jxgl/Login/tyLogin.asp",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
}
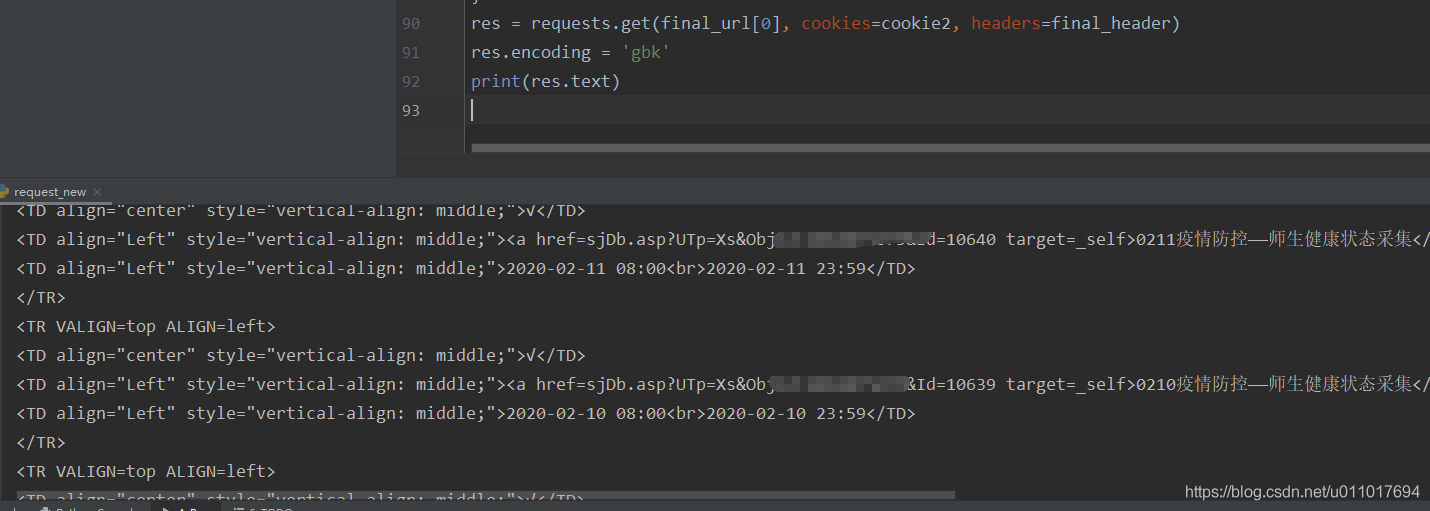
res = requests.get(final_url[0], cookies=cookie2, headers=final_header)
res.encoding = 'gbk'
print(res.text)
三.总结
通过这次模拟登录我们要明白以下几点:
- 如果大部分跳转可以忽略,除非中间有cookie的操作或者有对访问进行改变的操作。
- 可以通过对比自己手动的登录与自己代码提交的登录来判断哪一步有问题。
- 分清cookie类型,及时改变,多调试。
- 验证码同步(这次没涉及,但是有考虑)。
- 写博客是第二次写代码了,思路清晰多了,就忘记我还有哪些采坑了。。。。QAQ
四.完整的代码
使用时,记得修改POST的data数据里的信息。
import requests
import re
login_url = 'http://login.cuit.edu.cn/Login/xLogin/Login.asp'
login_header = {
"Accept": "image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, application/x-ms-xbap, */*",
"Referer": "http://login.cuit.edu.cn/Login/xLogin/Login.asp",
"Accept-Language": "zh-CN",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Proxy-Connection": "Keep-Alive",
"Pragma": "no-cache",
"Host": "jxgl.cuit.edu.cn",
}
res = requests.get(login_url, headers=login_header)
cookie1 = res.cookies
str_cookie1 = ''
for key, value in cookie1.items():
str_cookie1 = "%s=%s" % (key, value)
codekey = re.findall(r"(?<=var codeKey = ').*?(?=';)", res.text)
# print(cookie1, str_cookie1, codekey)
login_data = {
"WinW": "1855",
"WinH": "1080",
"txtId": yourid,
"txtMM": password,
"Login": "Check",
"IbtnEnter.x": "60",
"IbtnEnter.y": "37",
"verifycode": "1",
"codeKey": codekey[0],
}
res = requests.post(url=login_url, data=login_data, cookies=cookie1, headers=login_header)
res.encoding = "gbk" # 网站编码是GB2312,写GBk就行
# print(res.text)
# jkdk_url = re.findall(r"(?<=;URL=).*?(?=\">)", res.text)
# print(jkdk_url[0])
jkdk_header = {
"Accept": "image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, application/x-ms-xbap, */*",
"Accept-Language": "zh-CN",
"Accept-Encoding": "gzip, deflate",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Host": "jszx-jxpt.cuit.edu.cn",
"Connection": "Keep-Alive",
"Pragma": "no-cache",
} # 换头
res = requests.get(url="http://jszx-jxpt.cuit.edu.cn/jxgl/xs/netks/sj.asp?jkdk=Y", headers=jkdk_header, allow_redirects=False)
cookie2 = res.cookies
jump_url = re.findall(r"(?<=<a HREF=\").*?(?=\">here)", res.text)
jump_url[0] = "http://%s%s" % (jkdk_header["Host"], jump_url[0])
# print(cookie2, jump_url[0])
# <RequestsCookieJar[<Cookie ASPSESSIONIDQQSBDRRA=DBKMGFEBHPPAFMIKFADNBKEI for jszx-jxpt.cuit.edu.cn/>]>
# http://jszx-jxpt.cuit.edu.cn/Jxgl/UserPub/Login.asp?UTp=Xs
res = requests.get(url=jump_url[0], cookies=cookie2, headers=jkdk_header)
login_url_new = re.findall(r"(?<=;URL=).*?(?=\">)", res.text)
# print(login_url_new[0])
# http://login.cuit.edu.cn/Login/qqLogin.asp?Oid=jszx%2Djxpt%2Ecuit%2Eedu%2Ecn&OSid=341232539
login_header_new = {
"Host": "login.cuit.edu.cn",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://jxgl.cuit.edu.cn/jkdk/",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": str_cookie1 # cookie是包含在提交头里的,因为cookie1 不能在这个地址使用,所以用这种方式提交cookie
}
res = requests.get(url=login_url_new[0], headers=login_header_new, allow_redirects=False)
final_url = re.findall(r"(?<=<a HREF=\").*?(?=\">here)", res.text)
# print(final_url[0])
# http://jszx-jxpt.cuit.edu.cn/Jxgl/Login/tyLogin.asp
final_header = {
"Host": "jszx-jxpt.cuit.edu.cn",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://jszx-jxpt.cuit.edu.cn/Jxgl/Login/tyLogin.asp",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
}
res = requests.get(final_url[0], cookies=cookie2, headers=final_header)
res.encoding = 'gbk'
print(res.text)















 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











