







golang笔记15--go语言单任务版爬虫
1 介绍
本文继上文 golang笔记14-go 语言爬虫实战项目介绍, 进一步了解 go 语言单任务版爬虫项目,以及相应注意事项。
具体包括: 获得初始页面内容、正则表达式、提取城市和 url、单任务版爬虫的架构、Engine 与 Parser、测试 CityListParser、城市解析器、用户信息解析器(上)、用户信息解析器(下)、单任务版爬虫性能 等内容。
2 单任务版爬虫
2.1 获得初始页面内容
暂时设定单任务爬虫功能为:获取并打印所有城市第一页用户的详细信息;
因此需要先获取所有城市信息,此处可以通过 http://www.zhenai.com/zhenghun 页面获取,以下为该主页的获取方式:
1) 添加字符转换库
go get golang.org/x/text
go get golang.org/x/net/html
2) 爬取主页信息
vim main.go
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"net/http"
"golang.org/x/net/html/charset"
"golang.org/x/text/transform"
"golang.org/x/text/encoding"
)
func determineEncoding(r io.Reader) encoding.Encoding {
bytes, err := bufio.NewReader(r).Peek(1024)
if err != nil {
panic(err)
}
e, _, _ := charset.DetermineEncoding(bytes, "")
return e
}
func main() {
request, err := http.NewRequest(http.MethodGet, "http://www.zhenai.com/zhenghun", nil)
request.Header.Add("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36")
resp, err := http.DefaultClient.Do(request)
if err != nil {
panic(err)
}
defer resp.Body.Close()
e := determineEncoding(resp.Body)
utf8Reader := transform.NewReader(resp.Body, e.NewDecoder())
// all, err := httputil.DumpResponse(resp, true)
all, err := ioutil.ReadAll(utf8Reader)
if err != nil {
panic(err)
}
fmt.Printf("%s\n", all)
}
2.2 正则表达式
获取城市主页之后,就需要进一步获取所有城市的名称和链接,常见获取的方式包括:
-
使用 css 选择器
在网页界面右键-》Inspect-》Elements 下找到对应的table -》class=“city-list clearfix” -》Copy -》copy selector;
进入Console,将上面copy 的 selector 的内容作为一个变量执行,即可获得对应的城市信息,如下图所示:$('#app > article:nth-child(4) > dl') 通过css 选择器可以发现当前共有 22 个首字母栏目,共 470 个城市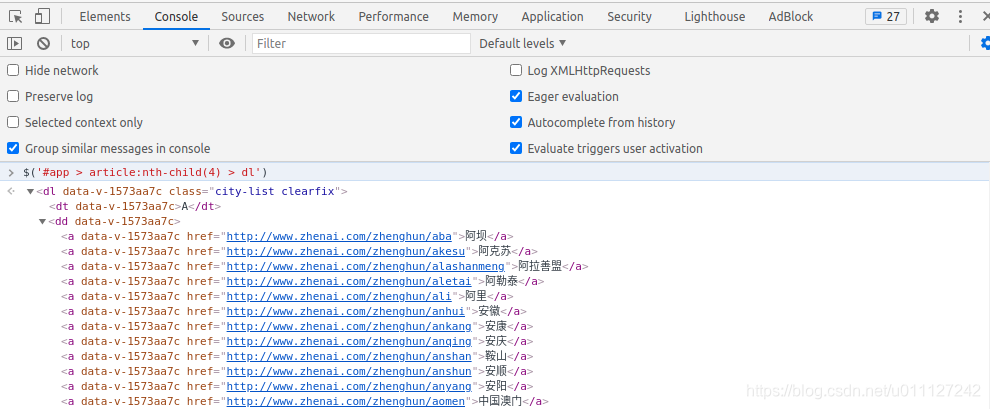
-
使用 xpath 选择器
当前网页的模式暂不支持,可以通过出现xpath相关的库来实现,此处暂时不介绍。 -
使用正则表达式
获取网页内容后,直接通过正则表达式获取所需要的内容,本案例就是通过正则表达式来实现的。
以下为go语言正则匹配案例:
package main
import (
"fmt"
"regexp"
)
// 使用 ` raw 内容` 后,内部的字符串不会收到转义的影响
const text = `
my email is ccmouse@gmail.com@abc.com
email1 is abc@def.org
email2 is kkk@qq.com
email3 is ddd@abc.com.cn
`
func myRegexp1() {
fmt.Println("this myRegexp1")
text := "my email is ccmouse@gmail.com@abc.com"
re := regexp.MustCompile(".*@gmail.com")
match := re.FindString(text)
fmt.Println(match)
}
func myRegexp2() {
fmt.Println("this myRegexp2")
text := "my email is ccmouse@gmail.com@abc.com"
re := regexp.MustCompile("[a-zA-Z0-9]+@gmail.com") //以字母或者数字开通,紧接着为@,因此会过滤掉空格符和前面的内容
match := re.FindString(text)
fmt.Println(match)
}
func myRegexp3() {
fmt.Println("this myRegexp3")
re := regexp.MustCompile(`([a-zA-Z0-9]+)@([a-zA-Z0-9]+)(\.[a-zA-Z0-9.]+)`)
match := re.FindAllStringSubmatch(text, -1)
for _, m := range match {
fmt.Println(m)
}
}
func main() {
myRegexp1()
myRegexp2()
myRegexp3()
}
输出:
this myRegexp1
my email is ccmouse@gmail.com
this myRegexp2
ccmouse@gmail.com
this myRegexp3
[ccmouse@gmail.com ccmouse gmail .com]
[abc@def.org abc def .org]
[kkk@qq.com kkk qq .com]
[ddd@abc.com.cn ddd abc .com.cn]
2.3 提取城市和 url
获取网页后,可以在输出中 copy 一条城市链接信息,根据正则提取城市名称和城市 url,具体案例如下:
vim main.go
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"net/http"
"regexp"
"golang.org/x/net/html/charset"
"golang.org/x/text/transform"
"golang.org/x/text/encoding"
)
func determineEncoding(r io.Reader) encoding.Encoding {
bytes, err := bufio.NewReader(r).Peek(1024)
if err != nil {
panic(err)
}
e, _, _ := charset.DetermineEncoding(bytes, "")
return e
}
func printCityList(contents []byte) {
re := regexp.MustCompile(`<a href="(http://www.zhenai.com/zhenghun/[a-zA-Z0-9]+)"[^>]*>([^<]+)</a>`) // 加了括号后就会提取括号内的内容
matches := re.FindAllSubmatch(contents, -1)
for _, m := range matches {
fmt.Printf("City: %s, URL: %s\n", m[2], m[1])
}
fmt.Println("Matches found:", len(matches))
}
func main() {
request, err := http.NewRequest(http.MethodGet, "http://www.zhenai.com/zhenghun", nil)
request.Header.Add("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36")
resp, err := http.DefaultClient.Do(request)
if err != nil {
panic(err)
}
defer resp.Body.Close()
e := determineEncoding(resp.Body)
utf8Reader := transform.NewReader(resp.Body, e.NewDecoder())
all, err := ioutil.ReadAll(utf8Reader)
if err != nil {
panic(err)
}
printCityList(all)
}
输出:
City: 阿坝, URL: http://www.zhenai.com/zhenghun/aba
City: 阿克苏, URL: http://www.zhenai.com/zhenghun/akesu
......
City: 资阳, URL: http://www.zhenai.com/zhenghun/ziyang1
City: 遵义, URL: http://www.zhenai.com/zhenghun/zunyi
Matches found: 470
2.4 单任务版爬虫的架构
对不同模块设置不同的解析器,此处根据需要设置城市列表解析器、城市解析器和用户解析器;
城市列表解析器:解析城市信息,提取出城市名称、城市url;
城市解析器:解析出城市中所有用户的名称和用户的 url 信息;
用户解析器:解析用户的各类信息,包括姓名、年龄、少、体重、收入、性别、星座、职业等具体信息;
由于需要设置多个解析器,此处单独抽象出解析器 parser:
输入: uft-8 编码的文本;
输出: Request{URL,对应的Parser} 列表, Item 列表;
抽象出 Parser 后,我们再添加Seed、Engine、 Fetcher 和任务队列,就可以构建出如下的单任务爬虫架构。其工作流程如下图所示:
engine 用于驱动所有的动作;
种子页面用于触发一系列爬虫任务;
种子页面触发爬虫任务后,engine就会将任务丢到对应的队列中;
engine 会不停的从队列中去除任务,并将其丢给 Fetcher,Fetcher 就返回指定的utf8文本给engine;
engine 收到 Fetcher 的数据后,让 Parser 解析数据,Parser 提取出有用的item数据并存放到指定db,并把相关的目标(例如潜在的用户 url )返回给Engine,从而继续提供新任务;
当任务队列为空后,就可以结束次爬取任务了;

2.5 Engine 与 Parser
本节继续对模块进行优化和完善,继续抽象出 engine, fetcher,parser等模块,并大幅优化 main.go 函数;具体优化如下:
/learngo/crawler$ tree -L 3
.
├── engine
│ ├── engine.go
│ └── types.go
├── fetcher
│ └── fetcher.go
├── mian.go
└── zhenai
└── parser
└── citylist.go
4 directories, 5 files
更新代码比较多,此处暂不逐一贴出:
vim engine/engin.go
func Run(seeds ...Request)
vim engine/types.go
type Request struct
type ParseResult struct
func NilParser([]byte) ParseResult
vim fetcher/fetcher.go
func determineEncoding(r io.Reader) encoding.Encoding
func Fetch(url string) ([]byte, error)
vim zhenai/parser/citylist.go
func ParseCityList(contents []byte) engine.ParseResult
vim main.go
package main
import (
"learngo/crawler/engine"
"learngo/crawler/zhenai/parser"
)
func main() {
url := "http://www.zhenai.com/zhenghun"
engine.Run(engine.Request{Url: url, ParserFunc: parser.ParseCityList})
}
输出:
2021/02/19 10:10:48 Fetching http://www.zhenai.com/zhenghun
2021/02/19 10:10:49 Get item: 阿坝
2021/02/19 10:10:49 Get item: 阿克苏
......
2021/02/19 10:10:49 Get item: 资阳
2021/02/19 10:10:49 Get item: 遵义
2021/02/19 10:10:49 Fetching http://www.zhenai.com/zhenghun/aba
2021/02/19 10:10:49 Fetching http://www.zhenai.com/zhenghun/akesu
......
2021/02/19 10:12:32 Fetching http://www.zhenai.com/zhenghun/ziyang1
2021/02/19 10:12:32 Fetching http://www.zhenai.com/zhenghun/zunyi
2.6 测试 CityListParser
上一小节已经完成了基础的 citylist 解析,因此可以使用之前 golang笔记09–go语言测试与性能调优 中的方法对其进行测试。
测试时,正常情况下下直接获取网页数据,然后和测试结果进行对比,并得出测试结论;
但是考虑到网络情况(存在断网或者暂时无法连外网的情况),可以先将目标网页保存到本地,然后再通过解析本地文件来测试;
本案例中就是使用第二种方式测试的,测试中暂且选取了 3 个测试用例。
vim zhenai/parser/citylist_test.go
package parser
import (
"io/ioutil"
"testing"
)
func TestParseCityList(t *testing.T) {
/* 预先获取数据,复制到 citylist_test_data.html 中,以便于后续测试对比
contents, err := fetcher.Fetch("http://www.zhenai.com/zhenghun")
if err != nil {
panic(err)
}
fmt.Printf("%s\n", contents)
*/
contents, err := ioutil.ReadFile(
"citylist_test_data.html")
if err != nil {
panic(err)
}
result := ParseCityList(contents)
const resultSize = 470
expectedUrls := []string{
"http://www.zhenai.com/zhenghun/aba",
"http://www.zhenai.com/zhenghun/akesu",
"http://www.zhenai.com/zhenghun/alashanmeng",
}
expectedCities := []string{
"阿坝",
"阿克苏",
"阿拉善盟",
}
if len(result.Requests) != resultSize {
t.Errorf("result should have %d requests; but had %d", resultSize, len(result.Requests))
}
for i, url := range expectedUrls {
if result.Requests[i].Url != url {
t.Errorf("expected url #%d: %s; but was %s", i, url, result.Requests[i].Url)
}
}
if len(result.Items) != resultSize {
t.Errorf("result should have %d requests; but had %d", resultSize, len(result.Items))
}
for i, city := range expectedCities {
if result.Items[i].(string) != city {
t.Errorf("expected city #%d: %s; but was %s", i, city, result.Items[i].(string))
}
}
}
输出:
=== RUN TestParseCityList
--- PASS: TestParseCityList (0.00s)
PASS
2.7 城市解析器
vim zhenai/parser/city.go
package parser
import (
"regexp"
"learngo/crawler/engine"
)
const cityRe = `<a href="(http://album\.zhenai\.com/u/[0-9]+)"[^>]*>([^<]+)</a>`
func ParseCity(contents []byte) engine.ParseResult {
// example <a href="http://album.zhenai.com/u/1412872831" target="_blank">执着</a>
re := regexp.MustCompile(cityRe) // 加了括号后就会提取括号内的内容
matches := re.FindAllSubmatch(contents, -1)
result := engine.ParseResult{}
for _, m := range matches {
result.Items = append(result.Items, "User "+string(m[2]))
result.Requests = append(result.Requests, engine.Request{
Url: string(m[1]),
ParserFunc: engine.NilParser,
})
}
return result
}
执行 main.go 输出:
2021/02/19 12:58:30 Fetching http://www.zhenai.com/zhenghun
2021/02/19 12:58:30 Got item: City 阿坝
2021/02/19 12:58:30 Got item: City 阿克苏
......
2021/02/19 12:58:30 Got item: City 资阳
2021/02/19 12:58:30 Got item: City 遵义
2021/02/19 12:58:30 Fetching http://www.zhenai.com/zhenghun/aba
2021/02/19 12:58:30 Got item: User 硒路西路
2021/02/19 12:58:30 Got item: User 心悦
2021/02/19 12:58:30 Got item: User 飞花落砚
......
2021/02/19 12:58:30 Got item: User 余生有你
2021/02/19 12:58:30 Got item: User 执着
2021/02/19 12:58:30 Fetching http://www.zhenai.com/zhenghun/akesu
2021/02/19 12:58:30 Got item: User 许我个未来
2021/02/19 12:58:30 Got item: User 不必在乎我是谁
......
2.8 用户信息解析器(上)
由于当前珍爱网用户信息在不登录的情况下无法直接获取,因此此处暂时不通过具体用户页面来获取;后续将更改为从城市页面获取每个页面的的内容,并提取少量用户信息,具体包括下图中的 用户昵称、用户uid|url、年龄、性别、婚姻状况、学历、身高、收入、自我介绍等内容。
初步解析如下:
vim learngo/crawler/zhenai/parser/city.go
package parser
import (
"learngo/crawler/engine"
"regexp"
"time"
)
const (
cityRe = `<a href="(http://album\.zhenai\.com/u/[0-9]+)"[^>]*>([^<]+)</a>`
ageRe = `<td width="[0-9]+"><span class="grayL">年龄:</span>([^<]+)</td>`
genderRe = `<td width="[0-9]+"><span class="grayL">性别:</span>([^<]+)</td>`
marriageRe = `<td width="[0-9]+"><span class="grayL">婚况:</span>([^<]+)</td>`
locationRe = `<td><span class="grayL">居住地:</span>([^<]+)</td>`
educationRe = `<td><span class="grayL">学 历:</span>([^<]+)</td>`
heightRe = `<td width="[0-9]+"><span class="grayL">身 高:</span>([^<]+)</td>`
incomeRe = `<td><span class="grayL">月 薪:</span>([^<]+)</td>`
introduceRe = `<div class="introduce">([^<]+)</div>`
idUrlRe = `.*album\.zhenai\.com/u/([\d]+)`
)
func getMatches(reRule string, contents []byte) []string {
reAge := regexp.MustCompile(reRule)
matchesAge := reAge.FindAllSubmatch(contents, -1)
retList := make([]string, len(matchesAge))
for i, m := range matchesAge {
retList[i] = string(m[1])
}
return retList
}
func extractString(contents []byte, re *regexp.Regexp) string {
match := re.FindSubmatch(contents)
if len(match) >= 2 {
return string(match[1])
} else {
return "null"
}
}
func ParseCity(contents []byte) engine.ParseResult {
// example <a href="http://album.zhenai.com/u/1412872831" target="_blank">执着</a>
re := regexp.MustCompile(cityRe) // 加了括号后就会提取括号内的内容
matches := re.FindAllSubmatch(contents, -1)
ageList := getMatches(ageRe, contents)
genderList := getMatches(genderRe, contents)
marriageList := getMatches(marriageRe, contents)
heightList := getMatches(heightRe, contents)
locationList := getMatches(locationRe, contents)
// educationList := getMatches(educationRe, contents) //部分用户没有education信息,需要更新调整为null
// incomeList := getMatches(incomeRe, contents) //部分用户没有income信息,需要更新调整为null
// fmt.Println("education", len(incomeList))
result := engine.ParseResult{}
for i, m := range matches {
idUrl := extractString(m[1], regexp.MustCompile(idUrlRe))
result.Items = append(result.Items, "User info: "+idUrl+", "+string(m[2])+", "+ageList[i]+", "+genderList[i]+
", "+marriageList[i]+", "+heightList[i]+", "+locationList[i]+", "+string(m[1])) //+", "+incomeList[i]+", "+educationList[i])
result.Requests = append(result.Requests, engine.Request{
Url: string(m[1]),
ParserFunc: engine.NilParser,
})
}
time.Sleep(time.Duration(time.Second * 2)) // 测试的时候爬慢点,否则会被系统检测到并禁止一或多天不能访问
return result
}
输出:
2021/02/20 12:37:30 Fetching http://www.zhenai.com/zhenghun
2021/02/20 12:37:30 Got item: City 阿坝
2021/02/20 12:37:30 Got item: City 阿克苏
......
2021/02/20 12:37:30 Got item: City 资阳
2021/02/20 12:37:30 Got item: City 遵义
2021/02/20 12:37:30 Fetching http://www.zhenai.com/zhenghun/aba
2021/02/20 12:37:32 Got item: User info: 1876503328, 硒路西路, 30, 女士, 未婚, 163, 四川阿坝, http://album.zhenai.com/u/1876503328
......
2021/02/20 12:37:32 Got item: User info: 1412872831, 执着, 36, 女士, 离异, 162, 四川阿坝, http://album.zhenai.com/u/1412872831
2021/02/20 12:37:32 Fetching http://www.zhenai.com/zhenghun/akesu
......

2.9 用户信息解析器(下)
在2.8 中已经初步获取了用户的基本数据,但是有些用户的字段缺失,因此最好先提取出单个用户的全部数据,然后再从中解析出用户的所有字段。
以下案例即对该方案进行实现:
vim learngo/crawler/zhenai/parser/city.go
package parser
import (
"fmt"
"learngo/crawler/engine"
"regexp"
"strings"
"time"
)
const (
cityRe = `<a href="(http://album\.zhenai\.com/u/[0-9]+)"[^>]*>([^<]+)</a>`
ageRe = `<td width="[0-9]+"><span class="grayL">年龄:</span>([^<]+)</td>`
genderRe = `<td width="[0-9]+"><span class="grayL">性别:</span>([^<]+)</td>`
marriageRe = `<td width="[0-9]+"><span class="grayL">婚况:</span>([^<]+)</td>`
locationRe = `<td><span class="grayL">居住地:</span>([^<]+)</td>`
educationRe = `<td><span class="grayL">学 历:</span>([^<]+)</td>`
heightRe = `<td width="[0-9]+"><span class="grayL">身 高:</span>([^<]+)</td>`
incomeRe = `<td><span class="grayL">月 薪:</span>([^<]+)</td>`
introduceRe = `<div class="introduce">([^<]+)</div>`
idUrlRe = `.*album\.zhenai\.com/u/([\d]+)`
imageRe = `<img src="(.+)?.+" alt=".*">`
)
func getMatches(reRule string, contents []byte) []string {
reAge := regexp.MustCompile(reRule)
matchesAge := reAge.FindAllSubmatch(contents, -1)
retList := make([]string, len(matchesAge))
for i, m := range matchesAge {
retList[i] = string(m[1])
}
return retList
}
func extractString(contents string, position int, re *regexp.Regexp) string {
match := re.FindStringSubmatch(contents)
if len(match) >= 1 {
return string(match[position])
} else {
return "null"
}
return ""
}
func getUserInfo(contents string) string {
userInfo := ""
name := extractString(contents, 2, regexp.MustCompile(cityRe))
userUrl := extractString(contents, 1, regexp.MustCompile(cityRe))
userId := extractString(userUrl, 1, regexp.MustCompile(idUrlRe))
age := extractString(contents, 1, regexp.MustCompile(ageRe))
gender := extractString(contents, 1, regexp.MustCompile(genderRe))
marriage := extractString(contents, 1, regexp.MustCompile(marriageRe))
location := extractString(contents, 1, regexp.MustCompile(locationRe))
height := extractString(contents, 1, regexp.MustCompile(heightRe))
education := extractString(contents, 1, regexp.MustCompile(educationRe))
income := extractString(contents, 1, regexp.MustCompile(incomeRe))
imageUrl := extractString(contents, 1, regexp.MustCompile(imageRe))
imageList := strings.Split(imageUrl, "?")
//introduce := extractString(contents, 1, regexp.MustCompile(introduceRe)) ,内容太长,输出的时候暂时不加如,存储的时候可以考虑加入
userInfo = fmt.Sprintf("%s,%s,%s,%s,%s,%s,%s,%s,%s,%s, %s", userId, name, age, gender, marriage, location, height, education, income, userUrl, imageList[0])
return userInfo
}
func ParseCity(contents []byte) engine.ParseResult {
// example <a href="http://album.zhenai.com/u/1412872831" target="_blank">执着</a>
re0 := regexp.MustCompile(cityRe) // 加了括号后就会提取括号内的内容
matches0 := re0.FindAllSubmatch(contents, -1)
url := ""
for _, m := range matches0 {
url = string(m[1])
}
// 先冲网页中取出所有用户相关的html信息,然后通过特有字段list-item切割,最后再解析每一个用户的信息
re := regexp.MustCompile(`<div class="(list-item"><div class="photo"><a .* <div class="item-btn">打招呼</div></div>)`)
matches := re.FindAllSubmatch(contents, -1)
var listStr string
for _, m := range matches {
listStr = string(m[0])
}
users := strings.Split(listStr, "list-item")
result := engine.ParseResult{}
for i, user := range users {
if i == 0 {
} else {
result.Items = append(result.Items, getUserInfo(user))
result.Requests = append(result.Requests, engine.Request{
Url: url,
ParserFunc: engine.NilParser,
})
}
}
time.Sleep(time.Duration(time.Second * 3))
return result
}
输出:
2021/02/26 22:41:59 Fetching http://www.zhenai.com/zhenghun
2021/02/26 22:42:00 item 1: City 阿坝
2021/02/26 22:42:00 item 2: City 阿克苏
......
2021/02/26 22:42:00 item 469: City 资阳
2021/02/26 22:42:00 item 470: City 遵义
2021/02/26 22:42:00 Fetching http://www.zhenai.com/zhenghun/aba
2021/02/26 22:42:03 item 471: 1817878559,真爱追求者,32,男士,未婚,四川阿坝,175,null,3001-5000元,http://album.zhenai.com/u/1817878559, https://photo.zastatic.com/images/photo/454470/1817878559/47941849828301171.jpg
2021/02/26 22:42:03 item 472: 1876503328,硒路西路,30,女士,未婚,四川阿坝,163,硕士,null,http://album.zhenai.com/u/1876503328, https://photo.zastatic.com/images/photo/469126/1876503328/46857240405567449.png
......
2021/02/26 22:42:03 item 490: 1764244724,山复尔尔,26,女士,未婚,四川阿坝,155,大学本科,null,http://album.zhenai.com/u/1764244724, https://photo.zastatic.com/images/photo/441062/1764244724/20083767307667940.jpg
2021/02/26 22:42:03 Fetching http://www.zhenai.com/zhenghun/akesu
......
2.10 单任务版爬虫性能
上述爬虫完成后,可以通过iftop来查看当前网络带宽情况,如下图所示:
持续观察其带宽,发现基本在15-20KB的速率,远未达到笔者100Mb/s的带宽速度,因此可以说单任务版本的效率很低,有必要进一步优化为并发版本的爬虫。

3 注意事项
本案例中的代码已经打包上传到 csdn go语言单任务版爬虫–crawler-v1 , 预计2021-02-26审核通过;
后续会继续更新一版并发爬虫。
- 本案例中用正则获取每个用户的完整数据比较困难,因此正则先获取了所有用户的数据,然后切割出单个用户的数据,再用正则获取单个用户数据的每一个字段。
- 笔者在测试单任务爬虫性能的时候,将time.Sleep 设置为100ms,发现获取9000多个用户信息后,返回200异常;因此无特殊情况测试时建议尽量设置sleep为3-5s(否则可能触发珍爱网的反爬虫机制)。
4 说明
- 软件环境
go版本:go1.15.8
操作系统:Ubuntu 20.04 Desktop
Idea:2020.01.04 - 参考文档
由浅入深掌握Go语言 --慕课网
正则表达式在线测试 --菜鸟网
















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











