







Python是目前较流行的一种科学计算语言。语法简洁,上手快,易于维护的优点。但其运算速度是真心的慢。那我们能否利用Python的简洁+OpenCL的运算能力呢?答案是可以的,那就是PyOpenCL。
目录
预备知识
kernel:是指一个用opencl c语言编写的、代表一个单一执行实例的代码单元。opencl c语言看起来跟C语言函数非常相像,都有一个参数列表“局部”变量定义和标准控制流结构。opencl术语中把这种kernel实例称为work-item(工作项)。但opencl kernel与c语方函数的区别在于其并行语义。
work_item:是定义在一个很大的并行执行空间中的一小部分。是并行操作中每一部分的实例化。通俗来说,可以理解为kernel里定义的执行函数。当kernel启动后会创建大量work_item来同时执行,以完成并行任务。work_item根所其数据结构大小可分为一维、二维和三维数据。work_item之是的运行是相互独立的,不同步的。
work_group:opencl将全局执行空间划分为大量大小相等的,一维、二维、三维的work_item集合,这个集合就是work_group。在work_group内部,各个work_item之间允许一定程度的通信。而有work_group保证并发执行来允许其内部的work_item之间的本地同步。
barrier函数:等待工作组中所有工作项都到达barrier位置,才继续往下执行。是OpenCL一种同步管理的函数。
OpenCL内核函数
uint get_work_dim() #返回线程调度的维度数。
uint get_global_size(uint dimension) #返回在所请求维度上work_item的总数。
uint get_global_id(uint dimension) #返回在所请求的维度上当前work_item在全局空间中的索引。
uint get_local_size(uint dimension) #返回在所请求的维度上work-group的大小。
uint get_local_id(uint dimension) #返回在所请求的维度上,当前work_item在work_group中的索引。
uint get_number_groups(uint dimension) #返回在所请求维度上work-group的数目,这个值等于get_global_size 除以 get_local_size。
uint get_group_id(uint dimension) #返回在所请求的维度上当前wrok_group在全局空间中的索引。数值归并
数值归并是对数组中的每个元素进行求和的运算。比如有个一维数组,里面有8个元素,每个元素的值依次是1,2,3,4…8,求这8个元素的和是多少。一般情况我们只需写个循环,把8个元素类加即可。而我们还可以用归并的方法来解答。用归并的方法来求和有一个好处,就是可以用并行的方法来求解。看下图。
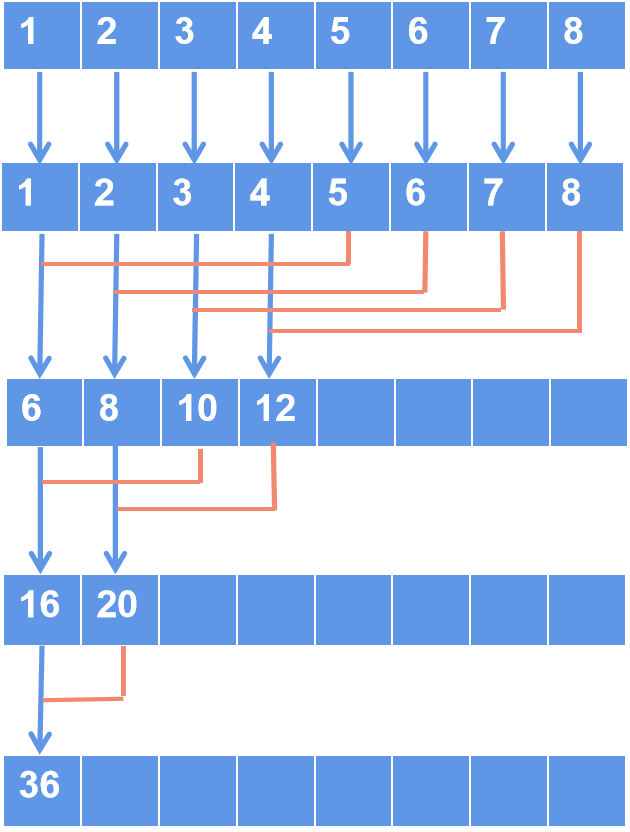
数值归并例子1
一维数组,里面有8192个元素,每个元素值是1,我们求所有元素的和,即最后答案是8192。
主程序(main.py)
import pyopencl as cl
import numpy as np
if __name__ == '__main__':
#要计算的元素个数
Array_size = 8192
#step 0:获取GPU计算设备
platform = cl.get_platforms()[0]
devices = platform.get_devices()
#step 1:选择设备并创建上下文
context = cl.create_some_context()
#step 2:创建命令队列
queue = cl.CommandQueue(context,devices[0],cl.command_queue_properties.PROFILING_ENABLE)
#获取系统信息,我的K600中max_work_group_size=1024
max_work_group_size = devices[0].get_info(cl.device_info.MAX_WORK_GROUP_SIZE)
#分组
num_groups = Array_size // max_work_group_size
#创建一个包含8192个1的浮点数组
buf_num = np.ones(Array_size,dtype=np.float32)
buf_out = np.zeros(num_groups,dtype=np.float32)
num_buf = cl.Buffer(context, cl.mem_flags.READ_ONLY | cl.mem_flags.COPY_HOST_PTR, hostbuf=buf_num)
out_buf = cl.Buffer(context, cl.mem_flags.READ_WRITE | cl.mem_flags.COPY_HOST_PTR, hostbuf=buf_out)
#为每个组准备一个存放中间计算值的空间
tmp_buf = cl.LocalMemory(Array_size)
#加载并创建CL程序
f_cl = open("reduction_scalar.cl","r")
f_buf = f_cl.read()
prg = cl.Program(context,f_buf).build()
#运行
prg.reduction_scalar(queue,(Array_size,),(max_work_group_size,),num_buf,tmp_buf,out_buf)
cl.enqueue_copy(queue,buf_out,out_buf)
sum=0
for i in range(0,num_groups):
sum += buf_out[i]
print(sum)
num_buf.release()
out_buf.release()
queue.finish() 内核程序(reduction_scalar.cl)
__kernel void reduction_scalar(__global float* data, __local float* partial_sums, __global float* output){
int cid = get_local_id(0);
int group_size = get_local_size(0);
partial_sums[cid] = data[get_global_id(0)];
barrier(CLK_LOCAL_MEM_FENCE);
for(int i=group_size/2;i>0;i/=2){
if(cid<i){
partial_sums[cid] += partial_sums[cid+i];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
if(cid==0){
output[get_group_id(0)] = partial_sums[0];
}
}数值归并例子2
在OpenCL里,有一个float4向量数据类型,它一次存4个浮点数。我们可以把8192个元素分成2048个float4来进行归并计算。最后再把向量中4个值相加。这种方法大大提高运算效率。速度是之前的4倍多。
主程序(main.py)
import pyopencl as cl
import numpy as np
if __name__ == '__main__':
#要计算的元素个数
Array_size = 8192
#step 0:获取GPU计算设备
platform = cl.get_platforms()[0]
devices = platform.get_devices()
#step 1:选择设备并创建上下文
context = cl.create_some_context()
#step 2:创建命令队列,选择计算设备
queue = cl.CommandQueue(context,devices[0],cl.command_queue_properties.PROFILING_ENABLE)
#获取系统信息,我的K600中max_work_group_size=1024
max_work_group_size = devices[0].get_info(cl.device_info.MAX_WORK_GROUP_SIZE)
#分组
num_groups = Array_size // max_work_group_size
#创建一个包含8192个1的浮点数组
buf_num = np.ones(Array_size,dtype=np.float32)
#存储每个向量的结果
buf_out = np.zeros(num_groups//4,dtype=np.float32)
num_buf = cl.Buffer(context, cl.mem_flags.READ_ONLY | cl.mem_flags.COPY_HOST_PTR, hostbuf=buf_num)
out_buf = cl.Buffer(context, cl.mem_flags.READ_WRITE | cl.mem_flags.COPY_HOST_PTR, hostbuf=buf_out)
#为每个组准备一个存放中间计算值的空间,由于是4个浮点数的向量,所以空间4倍
tmp_buf = cl.LocalMemory(Array_size*4)
#加载并创建CL程序
f_cl = open("reduction_vector.cl","r")
f_buf = f_cl.read()
prg = cl.Program(context,f_buf).build()
#运行
prg.reduction_vector(queue,(Array_size//4,),(max_work_group_size,),num_buf,tmp_buf,out_buf)
#读取计算值
cl.enqueue_copy(queue,buf_out,out_buf)
sum=0
for i in range(0,num_groups//4):
sum += buf_out[i]
print(sum)
num_buf.release()
out_buf.release()
queue.finish() 内核程序(reduction_vector.cl)
__kernel void reduction_vector(__global float4* data, __local float4* partial_sums, __global float* output){
int cid = get_local_id(0);
int group_size = get_local_size(0);
partial_sums[cid] = data[get_global_id(0)];
barrier(CLK_LOCAL_MEM_FENCE);
for(int i=group_size/2;i>0;i/=2){
if(cid<i){
partial_sums[cid] += partial_sums[cid+i];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
if(cid==0){
output[get_group_id(0)] = dot(partial_sums[0], (float4)(1.0f));
}
}














 410
410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









