一、安装库
爬虫性能的相关知识
pip install wheel
pip install scrapy
pip install pywin32
'''
windows 可能需要安装 Microsoft Visual C++ Build Tools 和 Visual C++ 14.0,如果C++版本不够,需要安装后才能安装scrapy库
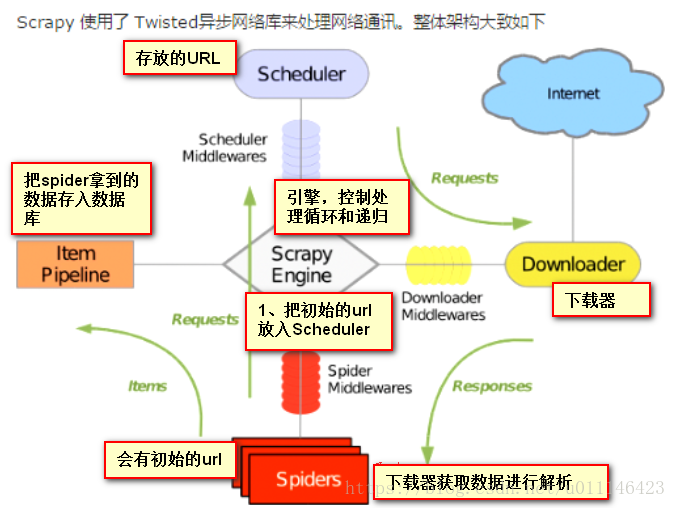
'''二、工作流程
1、指定初始URL
2、解析响应内容
- 给到调度器(Scheduler)继续执行
- 给pipeline;item 用于存储数据;格式化
- twisted 基于事件循环的异步非阻塞模块。一个线程同时可以向多个目标发去Http请求三、创建项目
# 创建项目
scrapy startproject 项目名称
# 进入到项目名称文件夹
cd 项目名称
# 创建 蜘蛛spidet
scrapy genspider 蜘蛛名称 url地址
# 执行
scrapy crawl 蜘蛛名称
# 执行取消日志
scrapy crawl 蜘蛛名称 --nolog
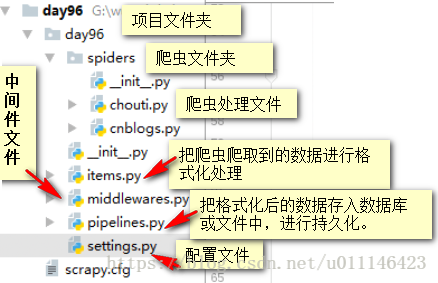
3.1、目录结构
四、scrapy操作
# windows 设置输出编码 Linux,mac不用
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
# 解析返回的数据
from scrapy.selector import Selector,HtmlXPathSelector
'''
Selector(response=response).xpath('查找的内容')找到所有标签,返回标签队形列表,通过for循环取出;
.extract() 将标签对象转换为字符串,通过for循环取出;
.extract_first() 只获取列表的第一个;
“//”表示整个标签文档查找,“.//”表示在当前标签下查找,“/”表示在当前标签的子集中查找;
“/div[@id="i1"]” 表示查找子集中div id=i1 的标签;
“/text()” 获取标签中的文本信息;
“div/@id” 获取id的值;
“//a[starts-with(@href,'/all/hot/recent/')]/@href” starts-with()获取属性值
“//a[re:test(@href,'/all/hot/recent\d+')]” 正则获取属性值
“//a[contents(@href,'link')]” 获取a标签中href包含link的标签对象
'''
# 语法
hxs = Selector(response=response).xpath('//标签名[@id="标签属性值"]/div[@class="标签属性值"]/text()').extract()
# 获取所有分页页码
- 利用set() 集合类型,来去除页面的重复信息;
- 获取所有的分页
yield Request(url=url,callback=self.parse) # 将获取到的新分页添加到调度器中
- 设置获取url的深度
settings.py 文件 DEPTH_LIMIT=1
# url进行加密存储,可以提高数据库查询效率
import hashlib
obj = hashlib.md5()
obj.update(bytes(url,encoding="utf-8")) # 进行加密
obj.hexdigest() # 得到加密的值
# 蜘蛛文件下 response
response.url # 获取请求url
response.text # 获取返回的结果
response.body # 获取返回内容
response.request # 发送请求
response.meta = {"depth":"抓取深度"}
content = str(response.body,encoding="utf-8") # windows转换编码 Linux,mac不用
4.1、抽屉小例子(分页的获取)
# -*- coding: utf-8 -*-
import scrapy
import sys
import io
from ..items import ChoutiItem
# from scrapy import Request,Selector
from scrapy.http import Request
# 解析返回的数据
from scrapy.selector import Selector,HtmlXPathSelector
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
class ChoutisSpider(scrapy.Spider):
name = 'choutis'
allowed_domains = ['chouti.com']
start_urls = ['http://dig.chouti.com/']
visited_url = set() # 去除重复的分页页码
'''
从写start_requests() 方法后,就可以改变scrapy库默认的pacse()方法的名称,
同时改变callback 指向。
def start_requests(self):
for url in self.start_urls:
yield Request(url,callback=self.parse)
'''
# scrapy 库默认的方法pacse
def parse(self, response):
print(response.meta)
# 获取标题和url
hxs1 = Selector(response=response).xpath(&








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









