






一、scrapy库安装
pip install scrapy -i https://pypi.douban.com/simple
二、scrapy项目的创建
1、创建爬虫项目 打开cmd 输入scrapy startproject 项目的名字
注意:项目的名字不允许使用数字开头 也不能包含中文
2、创建爬虫文件 要在spiders文件夹中去创建爬虫文件
cd 项目的名字\项目的名字\spiders
cd scrapy_baidu_091\scrapy_baidu_091\spiders创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取网页
e.g.scrapy genspider baidu www.baidu.com
不需要添加http协议 因为start_urls的值是根据allowed_domains修改的
所以添加了http的话,那么start_urls就需要我们手动去修改
3、运行爬虫代码
scrapy crawl 爬虫名字
e.g.
scrapy crawl baidu
三、scrapy项目的基本使用
scrapy项目的结构
项目名字
项目名字
spiders文件夹(存储的是爬虫文件)
__init__
自定义的爬虫文件 核心功能文件
__init__
items 定义数据结构的地方
middlewares 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 robots协议 user-agent定义等
四、scrapy文件里的response方法
1、response对象
response.text 获取响应的字符串
response.body 获取二进制数据
response.url 获取请求路径
response.status 获取状态码
2、response解析
response.xpath 解析response中的内容,返回一个selector列表对象
response.css 使用css_selector查询元素,返回一个selector对象
3、处理selector
response.extract() 提取seletor对象的data属性
response.extract_first() 提取seletor列表的第一个数据
五、scrapy的架构组成及工作原理
1、引擎
会自动组织所有的请求对象,分发给下载器
2、下载器
从引擎处获取到请求对象后,请求数据
3、spiders
定义爬取动作和解析网页
4、调度器
无需关注
5、pipeline
处理数据的管道,会预留接口用来处理数据

六、scrapy shell的使用
1、什么是scrapy shell?
Scrapy shell是Scrapy框架提供的一个交互式shell工具,用于快速开发和调试爬虫。它允许用户在不启动完整爬虫程序的情况下,以交互的方式加载和请求网页,并使用选择器和Scrapy的API来提取和处理数据。
2、scrapy shell作用
- 快速检查和测试网页的数据结构和内容;
- 调试和验证爬虫的选择器和提取规则;
- 测试和调试Scrapy的请求和响应处理逻辑;
- 使用Scrapy的内置命令行工具来实验性地进行数据提取和处理。
3、可以安装ipython,显示更智能
在命令行窗口,输入pip install ipython
4、scrapy shell的使用
在命令行窗口输入,scrapy shell www.baidu.com
然后就可以直接在命令行窗口用response方法
七、scrapy.spider的应用
e.g.爬取网站书籍的名称和图片
(1)、spider文件
import scrapy
from scrapy_dangdang_096.items import ScrapyDangdang096Item
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["category.dangdang.com"]
start_urls = ["https://category.dangdang.com/cp01.54.92.01.00.00.html"]
base_url = 'https://category.dangdang.com/pg'
page = 1
def parse(self, response):
# src = response.xpath('//ul[@id="component_59"]/li//img/@src')
#
# name = response.xpath('//ul[@id="component_59"]/li//img/@alt')
#
# price = response.xpath('//ul[@id="component_59"]/li//p[@class="price"]/span[1]')
li_list = response.xpath('//ul[@id="component_59"]/li')
#所有的selector对象都可以再次调用xpath
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
#第一张图片和其他图片的标签的属性是不一样的
#第一张图片可以用src,其他图片的地址标签是data—original
if src!=None:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdang096Item(src = src,name=name,price=price)
#获取一个book就将book交给pipelines
yield book
#https://category.dangdang.com/cp01.54.92.01.00.00.html
#https://category.dangdang.com/pg2-cp01.54.92.01.00.00.html
#https://category.dangdang.com/pg3-cp01.54.92.01.00.00.html
if self.page<100:
self.page=self.page+1
url = self.base_url + str(self.page) + '-cp01.54.92.01.00.00.html'
#怎么去调用parse方法
#scrapy.Request就是scrapy的get请求
#url就是请求地址
#callback是你要执行的那个函数 注意不需要加()
yield scrapy.Request(url = url,callback = self.parse)
注:scrapy的get请求为scrapy.Request()
(2)、items.py文件
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyDangdang096Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#图片
src = scrapy.Field()
#名字
name = scrapy.Field()
#价格
price = scrapy.Field()
(3)、pipelines.py文件
import urllib.request
#如果想使用pipelines,就要先在settings中打开pipelines
class ScrapyDangdang096Pipeline:
#在爬虫文件开始之前执行
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item就是yield后面的对象
def process_item(self, item, spider):
self.fp.write(str(item))
#(1)write 方法必须写字符串
#(2)a模式是追加写
# with open('book.json','a',encoding='utf-8') as fp:
# fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
#多条管道开启
#(1)定义管道类
#(2)在settings中开启管道
#将'scrapy_dangdang_096.pipelines.DangDangDownloadPipeline':301写入pipelines.py文件
class DangDangDownloadPipeline:
def process_item(self,item,spider):
url = 'http:'+item.get('src')
filename = './books'+item.get('name')+'.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item
(4)、settings.py文件
这个文件里取消 ITEM_PIPELINES 的注释,即开启pipeline。
然后在字典中加入
#DangDangDownloadPipeline
'scrapy_dangdang_096.pipelines.DangDangDownloadPipeline':301,即开启多条pipeline。
总而言之:
ITEM_PIPELINES = {
#pipelines可以有多个,管道是有优先级的,优先级的范围是1到1000,且值越小优先级越高
"scrapy_dangdang_096.pipelines.ScrapyDangdang096Pipeline": 300,
#DangDangDownloadPipeline
'scrapy_dangdang_096.pipelines.DangDangDownloadPipeline':301
}八、crawl spider的简介
1、创建项目步骤
(1)、创建项目 scrapy startproject readproject
(2)、跳转到spiders路径 cd \readproject\readproject\spiders
(3)、创建爬虫类 scrapy genspider -t crawl read www.dushu.com
(4)、items
(5)、spiders
(6)、settings
(7)、pipelines
数据保存到本地.json文件中
也可以数据保存到MySQL数据库(本文未阐述)
2、提取链接
链接提取器:scrapy.linkextractors.LinkExtractor()里面的
allow = (), #正则表达式,提取符合正则的链接
deny=(), #正则表达式,不提取符合正则的链接
allow_domains = (), #允许的域名
deny_domains = (), #不允许的域名
restrict_xpaths = (), #xpath , 提取符合xpath规则的链接
restrict_css = (), #提取符合选择器规则的链接
其中正则表达式用法示例:links1 = LinkExtractor(allow = r'list_10_\d+\.html')
3、运行原理
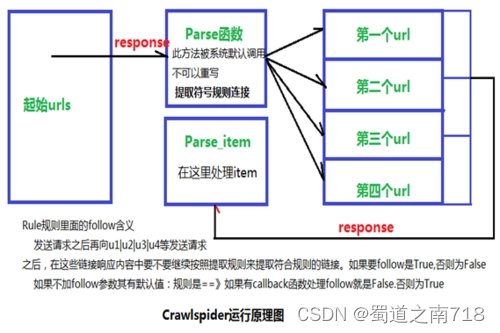
4、crawl spider的应用
e.g.爬取读书网的书籍信息
(1)、爬虫文件
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_097.items import ScrapyReadbook097Item
class ReadSpider(CrawlSpider):
name = "read"
allowed_domains = ["www.dushu.com"]
start_urls = ["https://www.dushu.com/book/1175_1.html"]
#True 是继续跟进,往后爬取
rules = (Rule(LinkExtractor(allow=r"/book/1175_\d+\.html"), callback="parse_item", follow=True),)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//a/img')
for img in img_list:
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
book = ScrapyReadbook097Item(name = name,src = src)
yield book
(2)、items.py文件
import scrapy
class ScrapyReadbook097Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
(3)、pipelines.py文件
from itemadapter import ItemAdapter
class ScrapyReadbook097Pipeline:
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()(4)、settings.py文件里打开
ITEM_PIPELINES就行
九、日志信息和日志等级
1、日志级别(由高到低)
CRITICAL:严重错误
ERROR:一般错误
WARNING:警告
INFO:一般信息
DEBUG:调试信息
默认的日志等级是DEBUG
注:只要出现了DEBUG或DEBUG以上等级的日志,那么这些日志将会打印。
2、settings.py文件的设置
(1)、LOG_FILE:将日志全部记录到文件中,该文件的后缀是.log
LOG_FILE = 'practice.log'
(2)、LOG_LEVEL:设置日志显示等级(不常用)
LOG_LEVEL = 'WARNING'
十、scrapy的post请求
由于start_urls和parse不能给post请求提供参数,故start_urls和parse都注释掉。
(1)、重新定义一个方法叫start_requests
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw':'spider'
}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)以及一个parse_second方法
def parse_second(self,response):
#python 3.10 版本,json。loads里不能用enconding='utf-8'
content = response.text
obj = json.loads(content.encode('utf-8'))
print(obj)(2)、start_requests的返回值
scrapy.FormRequest(url = url, headers = headers,callback = self.parse_second,formdata = data)
url :要发送的post地址
headers :头文件
callback:回调函数
formdata:post所携带的数据,是字典类型
十一、代理
1、到settings.py中,取消
DOWNLOADER_MIDDLEWARES = {
'postproject.middleware.Proxy':543
}
的注释。
2、到middlewares.py中写代码
def process_request(self,request,spider):
request.meta['proxy'] = 'https://111.11.111.11:1111'
return None
















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









