










 本文详细介绍了如何通过Docker和Kubernetes的命令行工具对容器、master和node节点、service以及pod进行日常巡检,包括健康检查、资源使用情况、日志管理和监控。同时涵盖了使用prometheus、cadvisor和Grafana进行监控以及日志收集的多种方式。
本文详细介绍了如何通过Docker和Kubernetes的命令行工具对容器、master和node节点、service以及pod进行日常巡检,包括健康检查、资源使用情况、日志管理和监控。同时涵盖了使用prometheus、cadvisor和Grafana进行监控以及日志收集的多种方式。
1 docker容器日常巡检
通过以下方式进行检查:
1.1 docker/podman ps查看容器状态
Docker/podman ps -a 查看容器状态STATUS:
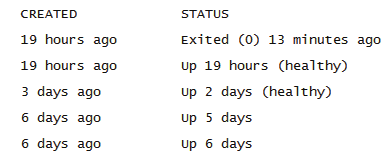
Exited(0):表示容器正常退出
Exited(其他数字):容器异常退出,需要通过log 查看原因
Up:容器在运行状态
Up(Paused):容器暂停
Up(healthy):容器监听健康
Up(unhealthy):容器监听异常
1.2 健康检查—HealthCheck
一些参数需要docker 17.05以上支持
1.2.1 通过docker run或者dockerfile添加健康检查
例如:
docker run --name=nginx --health-cmd="curl --silent --fail localhost/ || exit 1" --health-inter-val=30s --health-retries=3 --health-timeout=10s --start-period=60s nginx:latest
--interval:两次健康检查的间隔,默认为 30 秒
--timeout: 健康检查超时时间,,默认 30 秒
--retries: 连续失败次数,默认 3 次。
--start-period: 启动的初始化时间,默认 0 秒
--health-cmd: shell和exec 格式,取命令的返回值结果
0表示成功,1表示失败
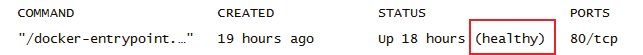
STATUS, healthy表示健康
unhealthy表示不健康
reserved保留值,不适用
1.2.2 输出健康检查状态
docker/podman inspect --format '{{json .State.Health}}' 容器名| python -m json.tool

输出healthy表示健康,用户可以编写脚本监控容器状态做报警
1.3 docker stats查看容器状态
![]()
可以通过docker stats查看容器的cpu, 内存,网络,IO的使用情况
1.4 通过第三方工具监听容器
这里主要介绍prometheus+grafana+cadvisor
1.4.1 prometheus介绍
prometheus通过node-exporter收集node主机的信息
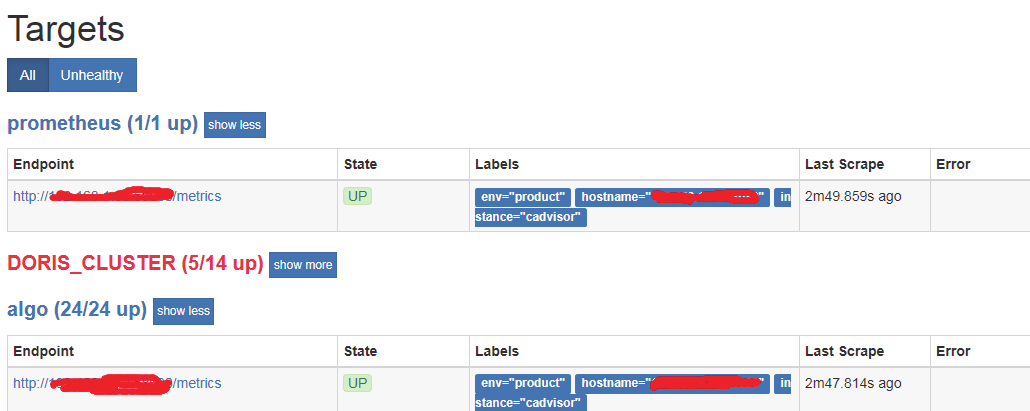
可以看到up状态和unhealthy状态的node节点主机
Unhealthy表示node节点node-exporter异常
Prometheus是一款强大的第三方工具,除了docker容器监控,还支持mysq,数据仓库,Hadoop,k8s 等开源系统
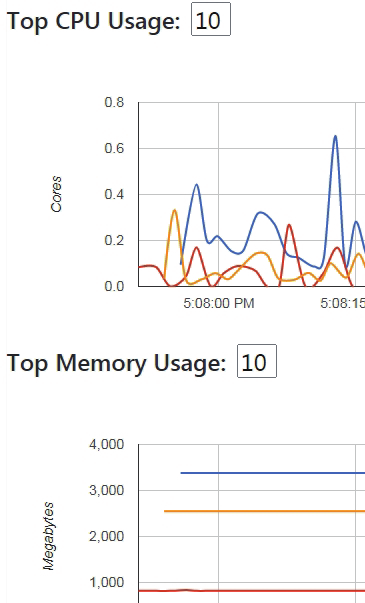
1.4.2 cadvisor介绍
Google的开源cadvisor,帮助收集,监听容器的status和数据,主要是CPU, 内存,FS,网络等usage
1.4.3 grafana介绍
Grafana作为展示prometheus和cadvisor的数据,也可以实现自定义规则报警。(可以去grafana官网搜寻需要监控的模板)
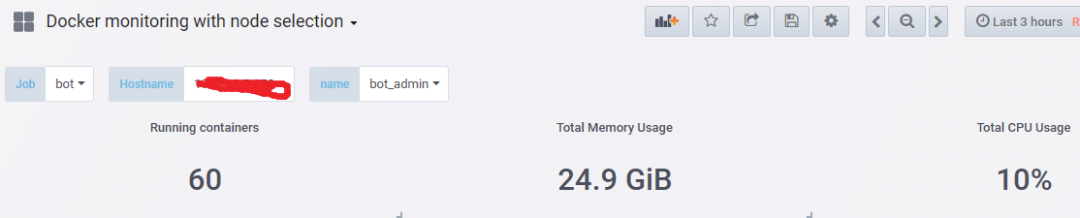
可以通过dashboard展示node主机上的所有容器
通过panel,metrics自定义需要收集的容器数据
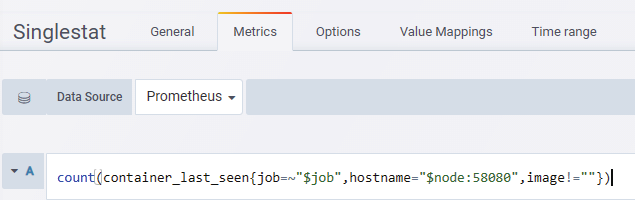
通过自定义规则统计需要收集的容器数据,也可以统计宕机状态的容器
Grafana支持自定义报警功能
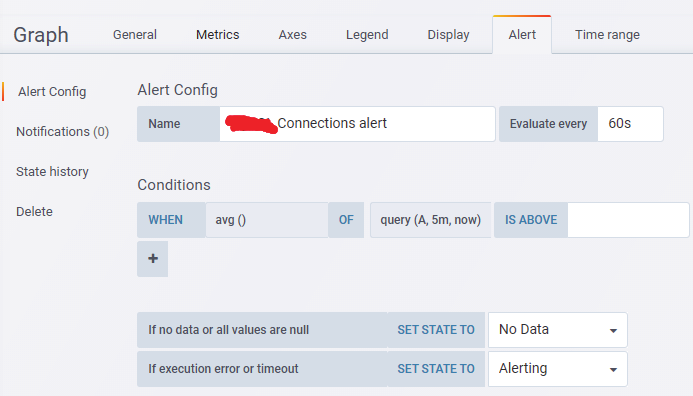
如果是大量的容器监控报警,建议使用alertmanager做报警
1.5 docker容器日志检查
Docker的日志分为两类,一类是 Docker引擎日志;另一类是容器日志。引擎日志一般都交给了系统日志。容器日志可以理解是运行在容器内部的应用输出的日志。
默认情况下,docker logs显示当前运行的容器的日志信息,内容包含 STOUT(标准输出) 和 STDERR(标准错误输出)。日志都会以 json-file的格式存储于 /var/lib/docker/containers/<容器id>/<容器id>-json.log
CRIO的日志,存放在/var/log/containers/
通过docker/podman logs命令查看容器的日志

查看最近1小时日志
docker/podman logs --since 60m容器名
查看某时间段日志
docker/podman logs -t --since="" --until "" 容器名
建议:docker/podman run时候,日志文件-v到宿主机上,
docker/podman run -d --name xxx -v /opt/log:/log xxx:latest
通过elk去抓取宿主机上的日志,尽量不要通过docker logs去检查容器日志。
除了docker容器,本文也向大家介绍kubernetes的日常巡检。
2 Kubernetes/OpenShift日常巡检
Kubernetes集群主要通过kubectl命令行进行运维,OpenShift中使用oc命令行进行运维。两个命令行的参是相同的(OpenShift集群也提供kubectl命令行,但建议使用oc命令行)。
2.1 检查master
主要通过以下命令检查。
2.1.1 kubectl/oc 检查master状态
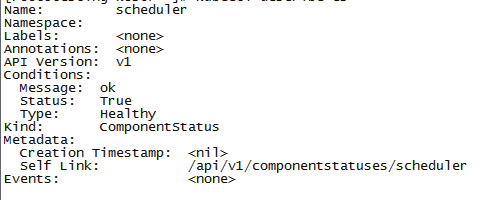
kubectl/oc get cs

通过以上方法,查看kube-scheduler, kube-controller-manager, etcd是否正常。在上图status列,Healthy表示健康,unhealthy表示有问题需要更详细的信息,可以使用kubectl/oc describe cs,输出更详细的信息。
systemctl status calico.service
检查calico网络是否正常
systemctl status kube-apiserver.service
检查kube-apiserver 是否都是active状态
Active: active (running)
如果状态不正常,需要systemctl restart kube-apiserver
如果起不来,需要journalctl -xe查日志看下具体问题
2.1.2 kubectl/oc logs 检查master日志
kubectl/oc logs --tail 100 -f kube-apiserver -n kube-system
kubectl/oc logs --tail 100 -f kube-controllers -n kube-system
kubectl/oc logs --tail 100 -f kube-scheduler -n kube-system
kubectl/oc logs --tail 100 -f coredns -n kube-system
检查master服务日志是否正常
kubectl/oc logs --tail 100 -f calico-kube-controllers -n kube-system
检查calico是否正常
以下是node巡检
2.2 检查node
2.2.1 kubectl/oc检查node状态
kubectl/oc get node -n namespace
查看Node节点状态, STATUS Ready表示正常,NotReady不正常

注意version必须保持一致
如有NotReady问题,需要重启节点kubectl/oc,或者重启docker
如不能解决,需要reset节点后,k8s重新join该node(注意先执行kubectl/oc drain node --delete-lo-cal-data 驱离node)
systemctl status kubelet.service
systemctl status kube-proxy.service
检查状态是否是Active: active (running)
如果不正常,需要systemctl restart
如果起不来,需要journalctl -xe查日志看下具体问题
2.2.2 kubectl/oc logs检查node日志
kubectl/oc logs --tail 100 -f kube-proxy -n kube-system
kubectl/oc logs --tail 100 -f kebelet -n kube-system
检查node服务日志是否正常
kubectl/oc logs --tail 100 -f calico-node -n kube-system
检查calico节点是否正常
2.3 检查service
kubectl/oc get svc -o wide
![]()
查看k8s集群service信息
kubectl/oc get svc --all-namespaces -o wide
查看k8s所有service信息
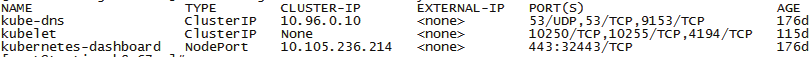
TYPE是NodePort的service, k8s集群外部可以通过port访问
Service的TYPE包括 NodePort, ClusterIP, Loadbalance和ExternalName
以下是pod巡检
2.4 检查pod
2.4.1 kubectl/oc检查pod状态
kubectl/oc get pods -n namespace -o wide
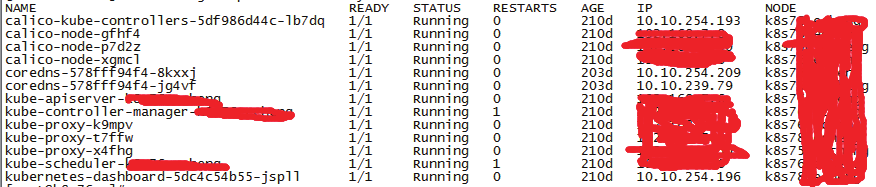
查看STATUS状态是否正常
以下是status list:
Running,Succeeded,Waiting,ContainerCreating,Failed,Pending,Terminating,unknown,CrashLoopBackOff,ErrImagePull,ImagePullBackOff
status定义说明:
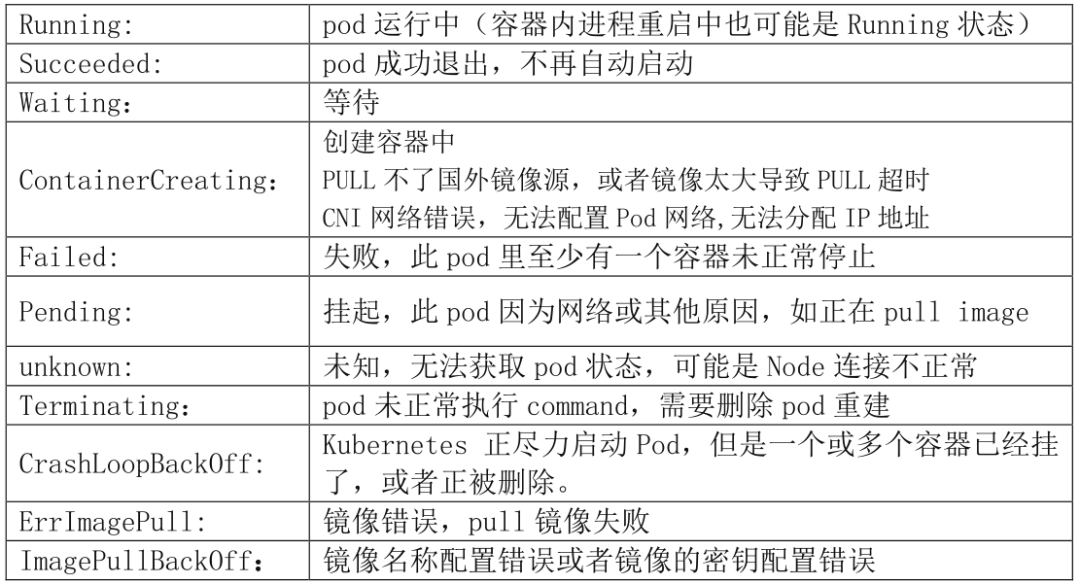
如出现异常状态,可查看pod日志内容
kubectl/oc describe pod 容器名 -n namespace
查看Conditions状态
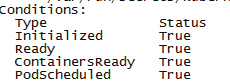
True 表示成功,False表示失败
Initialized pod 容器初始化完毕
Ready pod 可正常提供服务
ContainersReady 容器可正常提供服务
PodScheduled pod 正在调度中,有合适的节点就会绑定,并更新到etcd
Unschedulable pod 不能调度,没有找到合适的节点
如有False状态显示
查看Events信息
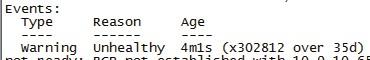
Reason显示Unhealthy异常,仔细查看后面的报错信息,有针对性修复
kubectl/oc get pods -n namespace -o wide
查看RESTARTS的次数是否为0
如果不是0,说明pod重启过,需要去日志检查原因
2.4.2 kubectl/oc logs 检查pod日志
kubectl/oc logs --tail 100 -f pod -n namespace
检查日志中有无异常
或者进入日志目录 /var/log/pods,找到容器id-json.log日志文件
也可以检查日志有无异常
2.5 pod health健康检测
针对pod容器增加health check健康检测,pod.yaml中增加以下参数

livenessProbe是检测容器是否存活,running状态,如果不健康kubelet会kill pod,根据重启策略RestartPolicy执行重启pod。
ReadinessProbe判断容器是否处于Ready状态,ready状态表示pod可以接受请求,如果不健康,从service的后端endpoint列表中把pod驱离出去。
initialDelaySeconds 120表示pod初始化启动之后延迟120秒再开始检测等待pod内应用启动时间
timeoutSeconds表示超时时间
periodSeconds表示轮询时间
scheme连接使用的schema,默认HTTP,也支持TCP
successThreshold探测失败后,最少连续探测成功多少次被认定为成功。默认是1。对于liveness必须是1,最小值是1。
failureThreshold:探测成功后,最少连续探测失败多少次被认定为失败。默认是3,最小值是1。
超过failureThreshold的次数,pod重启多次后,pod STATUS状态会变更为不健康
2.6 通过dashborad检查
K8s支持dashboard管理方式
通过kubernetes-dashboard.yaml配置dashboard

通过firefox浏览器访问,https://k8sip:30443/#!/login
通过令牌方式访问,令牌查找方式,在master执行以下
kubectl/oc describe secret admin-token-xxxx -n kube-system
进入dashboard后,可以查看k8s所有资源状况

选择节点,可以查看node状态
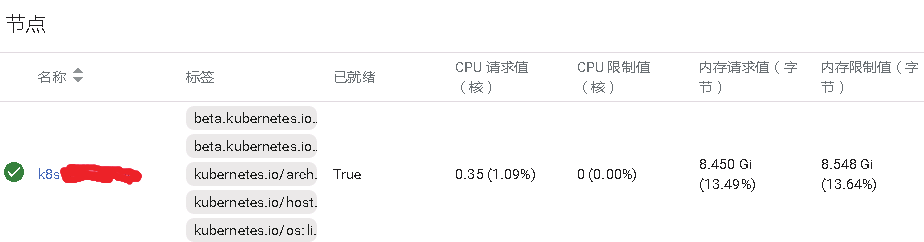
可以查看node节点是否就绪状态,节点的CPU,内存资源使用状况

选择容器组,可以查看pod的状态信息
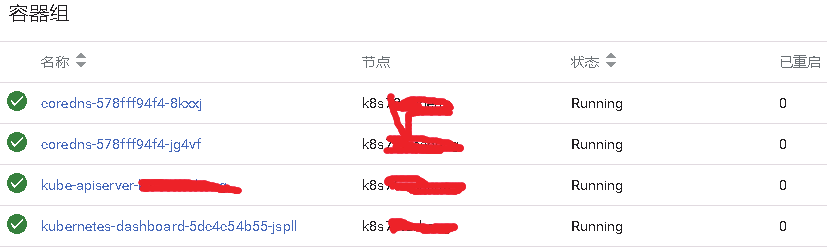
可以看到pod容器的状态
Dashboard也可以查看deployment,stateful, service,VP的状态信息
Dashboard的权限很高,可以创建容器,容器组,可以删除容器和容器组;
可以伸缩部署和副本集;可以创建,删除secret
2.7 通过kube-promtheus监控k8s
K8s监控需要考虑以下几方面
Kubernetes节点的监控:node节点的cpu、负载、内存、硬盘等指标
内部系统组件的状态:kube-scheduler、kube-controller-manager、kubedns/coredns等组件的运行状态
metrics:Deployment的状态、资源请求、调度和API延迟等数据指标
Kube-prom的组成如下

2.7.1 node-export监控
我们使用prometheus来监控k8s node状态和性能,采集节点的监控指标,可以通过node_exporter获取,node_exporter就是抓取用于采集服务器节点的各种运行指标,目,比如cpu、distats、loadavg、meminfo、netstat等。
使用DeamonSet控制器来部署该pod,这样每一个节点都会运行一个Pod,如果我们从集群中删除或添加节点后,也会进行自动扩展,
node-exporter.yaml样例如下:





执行kubectl get pod -n monitoring -o wide 或oc get pods -n openshift-monitoring -o wide(关于OpenShift命令行,本小节不再赘述)
![]()
可以查到node-exporter的pod状态在k8s节点上, curl 127.0.0.1:9100/metrics,可以获取到数据,说明成功收集
配置node-exporter-service.yaml

输入kubectl get svc -n monitoring -o wide |grep node
输出以下
![]()
表示service配置完成
2.7.2 kube-state-metrics
kube-state-metrics本质上是不断轮询api-server,kube-state-metrics关注于获取k8s各种资源的最新状态,如deployment或者daemonset,而kube-state-metrics是将k8s的运行状况在内存中做了个快照,并且获取新的指标。
配置kube-state-metrics-deployment.yaml样式



配置 kube-state-metrics-service.yaml

查看pod和svc
kubectl get pod -n monitoring -o wide |grep state
kubectl get svc -n monitoring -o wide |grep state
![]()
检查状态是否正常
2.7.3 grafana监控
我们使用grafana展示kube-prom的信息状态监控
grafana-deployment.yaml样式如下:









grafana-service.yaml样式如下:

查看grafana service pod
kubectl get pod,svc -n monitoring -o wide |grep grafana
![]()
访问grafana后台,浏览器访问http://ip:23000/login
(可以去grafana官网搜寻需要监控的模板)
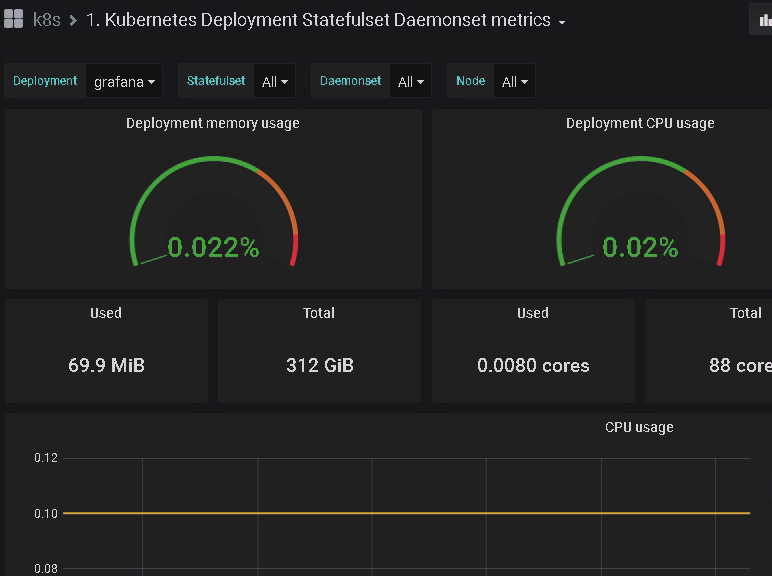
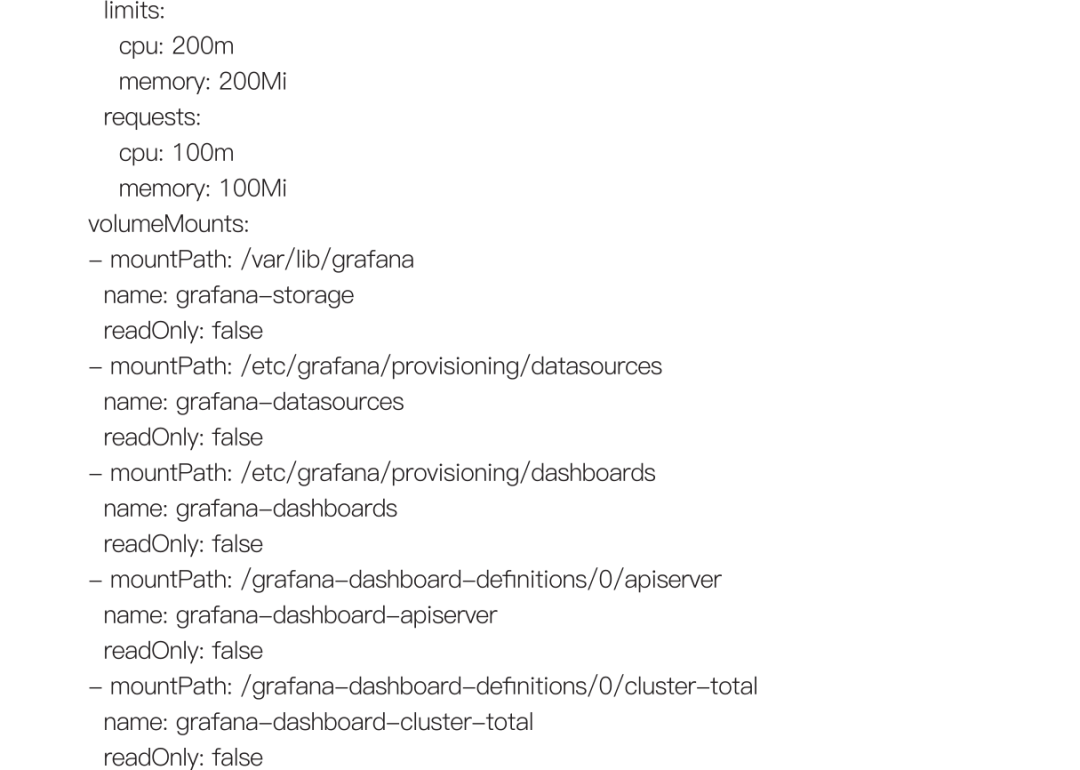
可以查看k8s容器的内存,CPU等资源的使用率
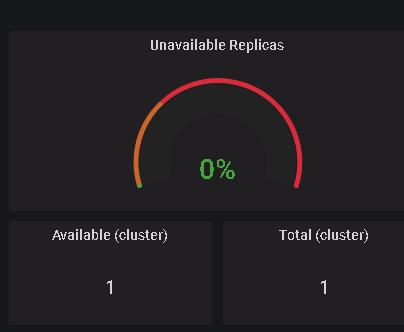
可以查看有问题的容器副本
在alert里面可以配置报警规则
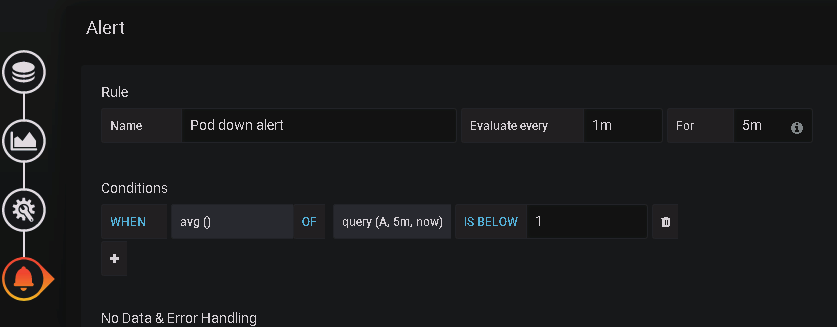
可以配置pod宕机发送报警
2.8 kubernetes日志收集
1. 原生方式:使用kubectl/oc logs直接查看本地保留的日志,或者通过docker engine的 log driver把日志重定向到文件、syslog、fluentd等系统中。
2. DaemonSet方式:在K8S的每个node上部署日志agent,由agent采集所有容器的日志到服务端。
3. Sidecar方式:一个POD中运行一个sidecar的日志agent容器,用于采集该POD主容器产生的日志。
Sidecar和DaemonSet是被动采集方式,主动采集方式有原生方式DockerEngine 推主动送方式(也可以通过SDK进行业务日志直写,本文不介绍)
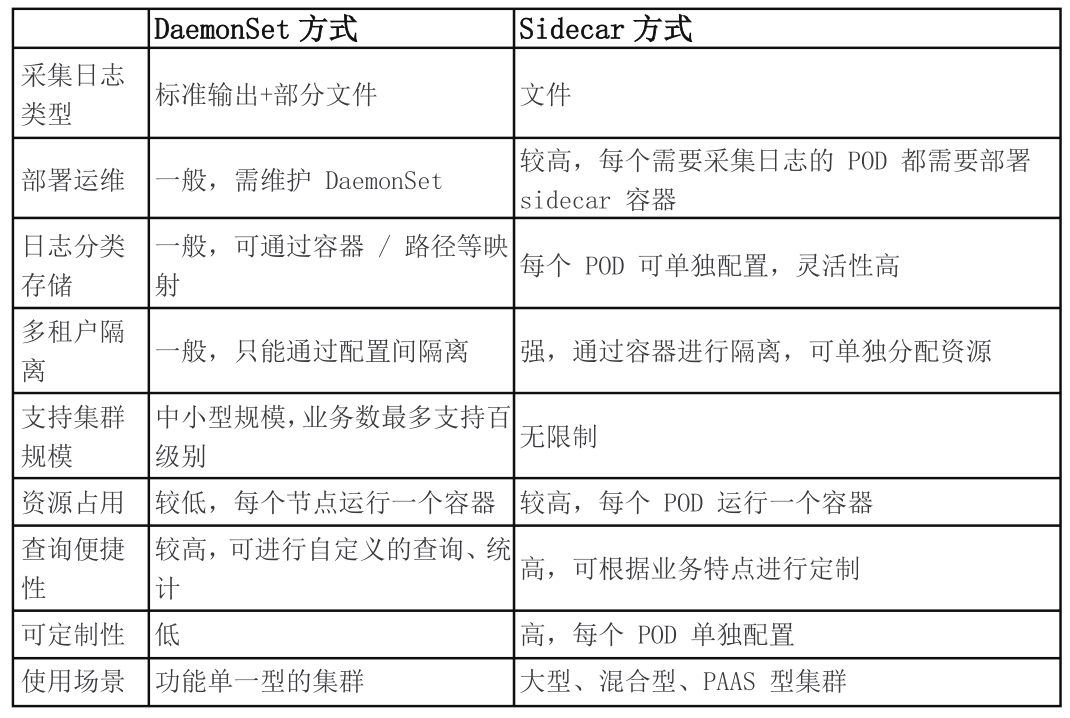
2.8.1 原生方式log
DockerEngine本身具有LogDriver功能,可通过配置不同的LogDriver将容器的stdout通过DockerEngine写入到远端存储,以此达到日志采集的目的。这种方式的可定制化、灵活性、资源隔离性都很低,一般不建议在生产环境中使用。
K8s的容器提供标准输出和文件两种方式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,将日志接收后按照DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式和虚拟机/物理机基本类似,只是日志可以使用不同的存储方式,例如默认存储、EmptyDir、HostVolume、NFS等。
2.8.2 daemonset方式--Node上部署log agent
DaemonSet方式在每个node节点上只运行一个日志agent,采集这个节点上所有的日志。DaemonSet相对资源占用要小很多,但扩展性、租户隔离性受限,比较适用于功能单一或业务不是很多的集群。
通过部署Elasticsearch集群 ,Fluentd过滤、Elasticsearch存储、Kibana展示,来收集node agent的日志。(本文介绍较为简单的Filebeat方式)
yaml配置样式如下







日志输出到文件,hostPath方式挂载,agent通过deamonset方式部署
2.8.3 sidecar方式:通过sidecar容器收集日志
在k8s里,可以为pod添加一个sidecar进行pod日志收集,可以使用filebeat。每个pod都需要一个独立的sidecar,以下是为nginx添加sidecar
yaml配置样式如下:





















 905
905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











