










l 采集网站
【场景描述】采集B站动漫分类中所有UP主数据。
【源网站介绍】
B站,全名哔哩哔哩,英文名称:bilibili,https://www.bilibili.com/v/channel/type/1,现为中国年轻世代高度聚集的文化社区和视频平台,该网站于2009年6月26日创建,被粉丝们亲切地称为“B站” 。
【使用工具】前嗅ForeSpider数据采集系统,点击下方链接可免费下载
http://www.forenose.com/view/forespider/view/download.html
【入口网址】https://www.bilibili.com/v/channel/type/1
【采集内容】
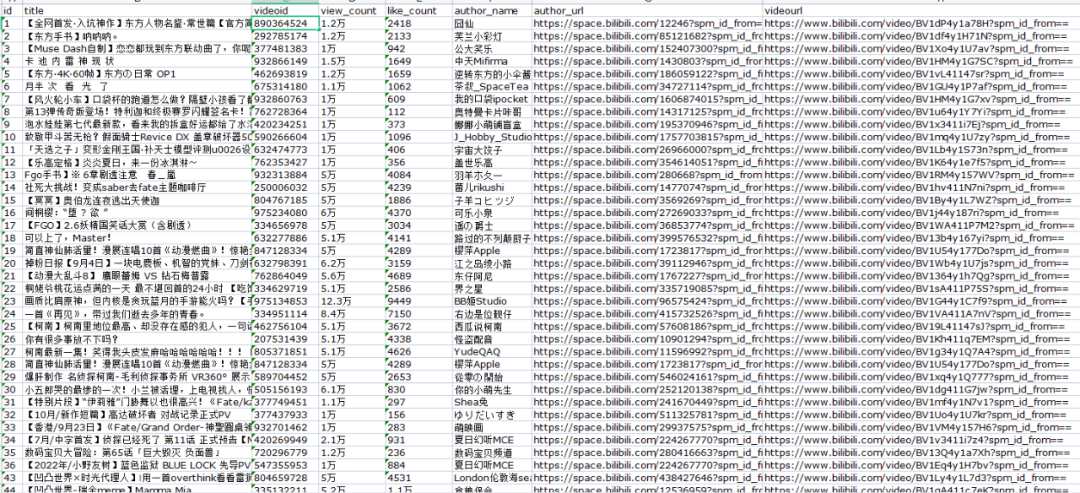
采集B站动漫分类中所有up主信息,字段包括:up主名称、id、视频名称、视频链接、观看量、点赞量等。
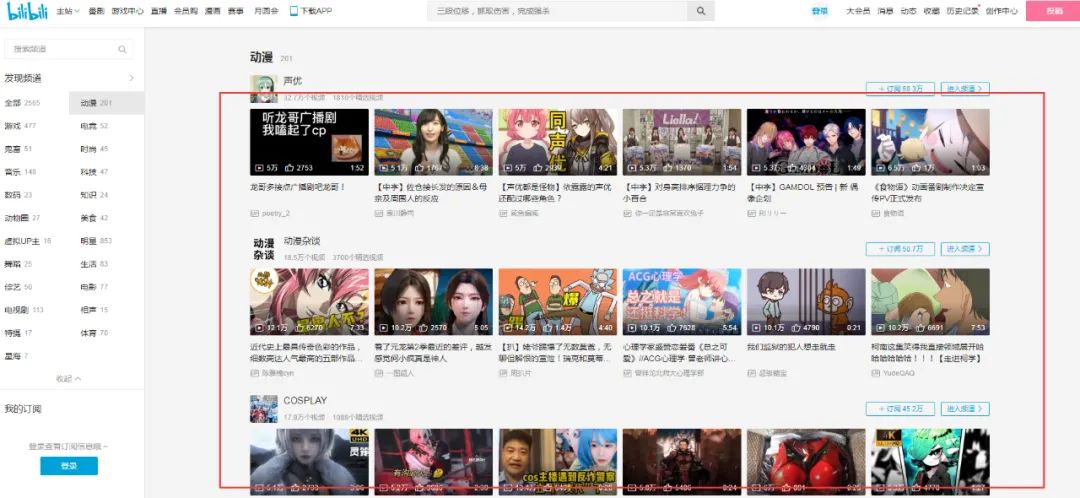
【采集效果】如下图所示:
l 思路分析
配置思路概览:

l 配置步骤
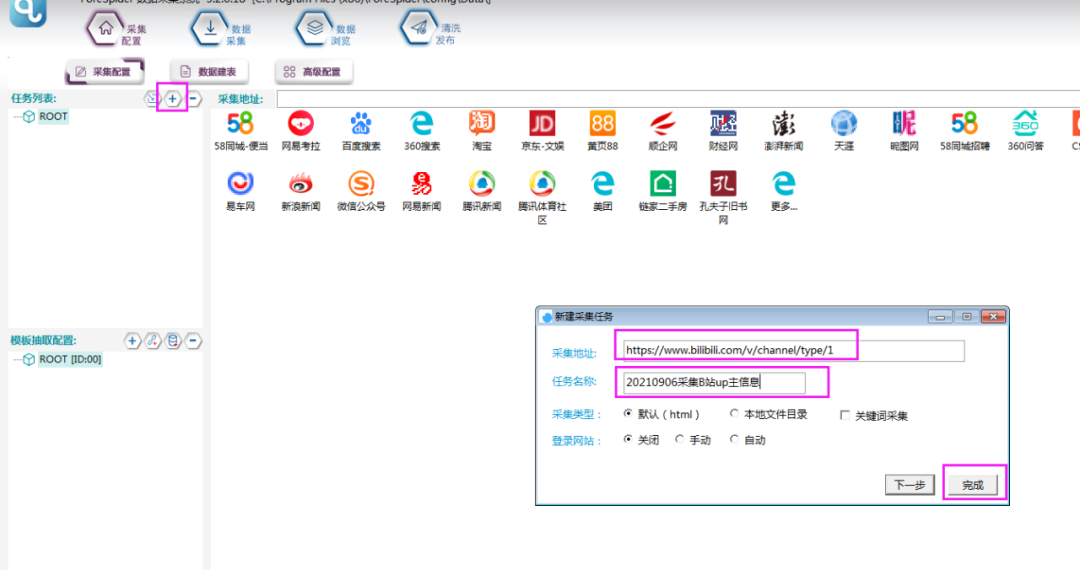
1. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
2.获取类表请求链接
①在浏览器上观察该页面翻页,翻页类型为瀑布流翻页,推测翻页链接在请求中。
②点击F12,继续往后翻页,观察可找到翻页请求在如下图所示的请求中。
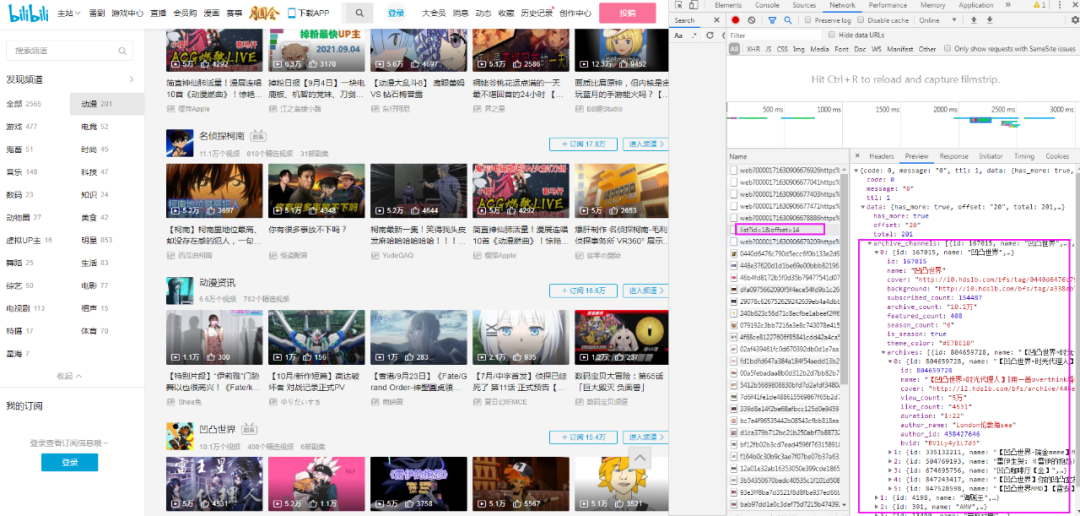
③复制翻页请求链接:

④同样方法,找到第三页和第四页请求链接,并复制出来。
⑤观察链接,发现规律如下图所示:

⑥写翻页链接脚本,具体操作如下所示:

脚本文本:
url u;//定义一个url
for(int i = 1;i <= 20;i++)//写一个for循环,采集前20页内容
{
var y=i*7;//定义y为i*7
u.title = i;//输出url名称为页数
u.urlname = "https://api.bilibili.com/x/web-interface/web/channel/category/channel_arc/list?id=1&offset="+y;//根据翻页请求规律拼翻页请求链接
u.entryid = CHANN.id;//
u.tmplid = 2;关联模板2
RESULT.AddLink(u);
}⑦采集预览,如下图所示,表示翻页链接已生成。
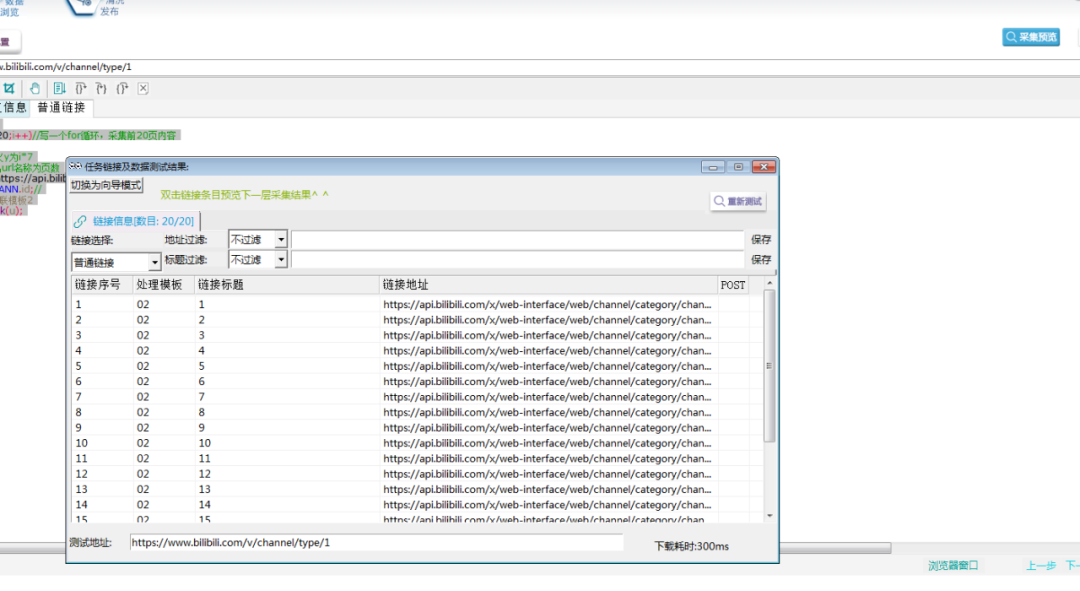
3.采集up主信息
①在浏览器中打开任意一个翻页请求的链接,可发现up主的信息就在返回的数据值中。而且每个【archive_channels】的数组中有6个值,每个值中的【archives】数组中有6个值即为每个up主的信息。
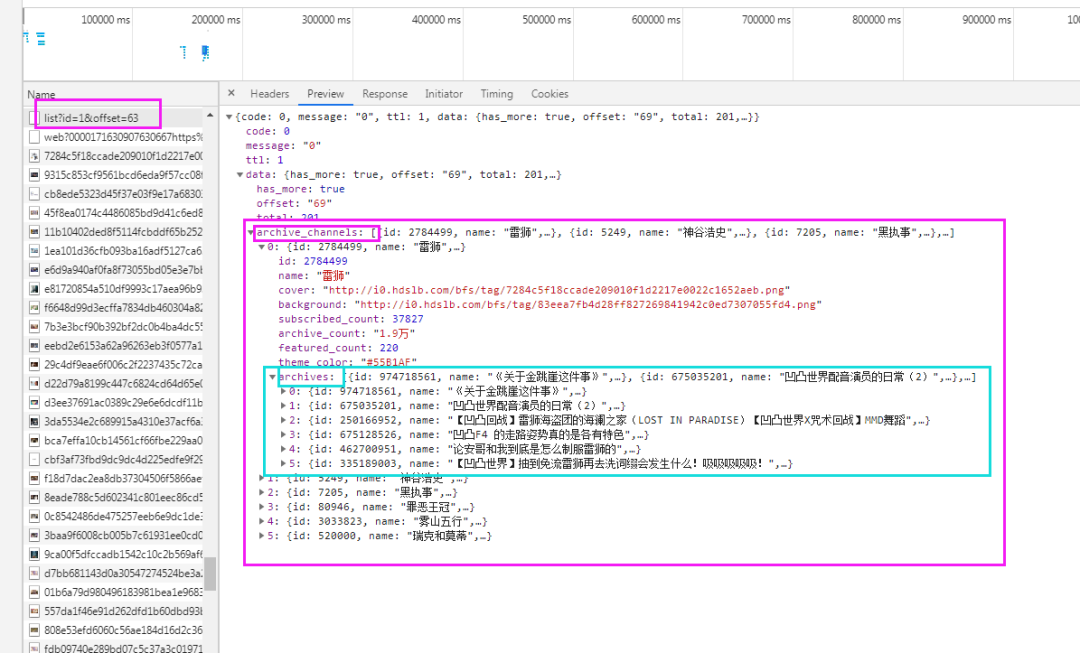
②通过观察可发现,视频链接规律为:
https://www.bilibili.com/video/+视频id+?spm_id_from=
Up主主页链接为:
https://space.bilibili.com/+up主id+?spm_id_from=
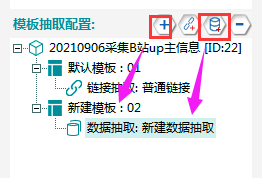
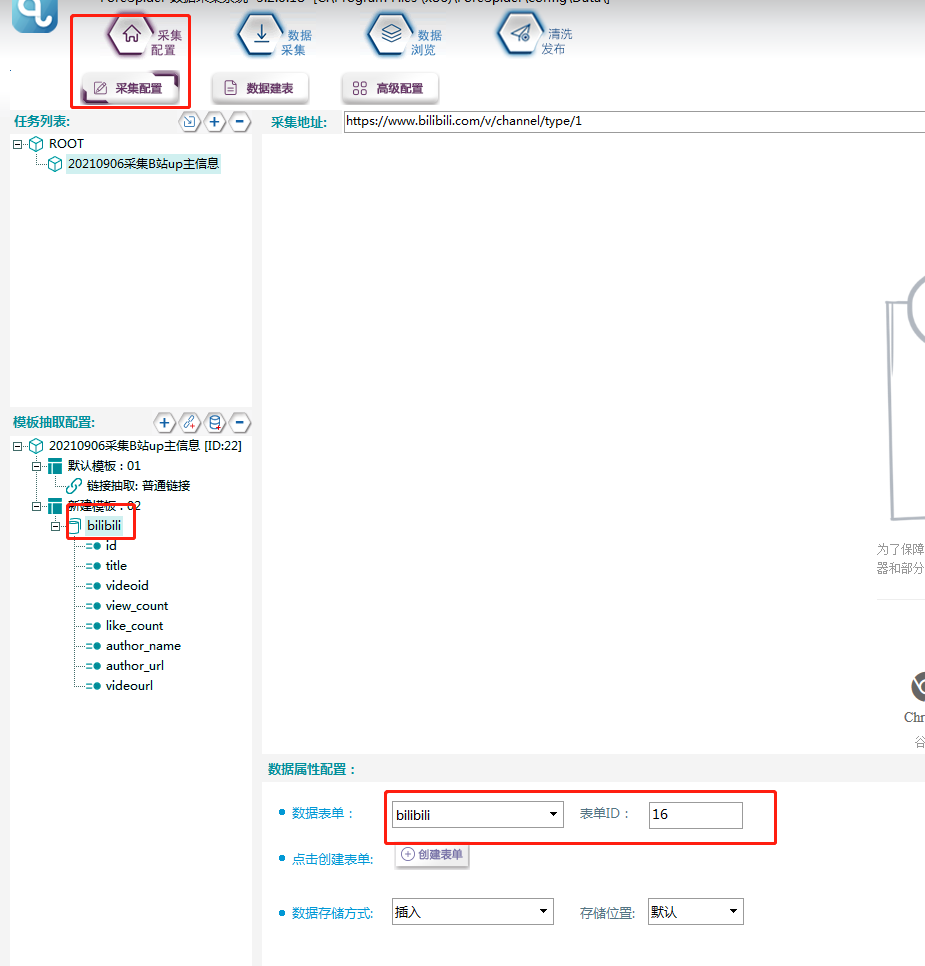
③新建模板02,在其下新建一个数据抽取。
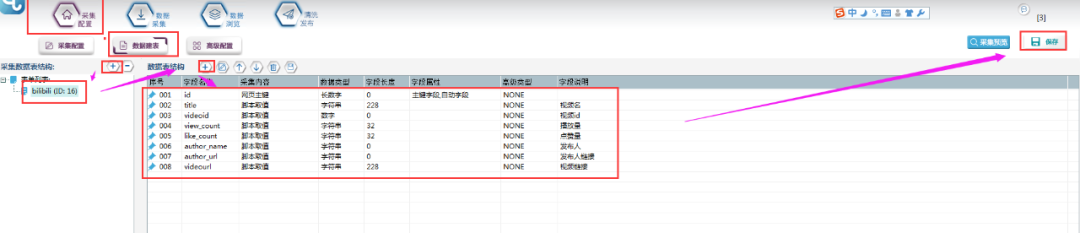
④新建一个数据表单,具体步骤和字段属性如下所示:
⑤关联数据表单,如下图所示:
⑥脚本取值,新建脚本,具体如下图所示:

脚本文本如下所示:
var ur=URL.urlname;//定义ur变量为当前请求链接,即翻页请求链接
var doc = EXTRACT.OpenDoc(CHANN, ur, "");//打开请求
var tstr = doc.GetDom().GetSource().ToStr().Right("archive_channels\":");//打开请求中的dom树,获取源码,并取archive_channels":右侧的所有源码
jScript js;//定义一个js
var obj = js.RunJson(tstr);//执行tstr代码并返回一个对象
var k=1;//定义k为1,为后续自增主键准备
for(var i=0;i<=6;i++){//for循环取【archive_channels】中的6个对象
var obj_a=obj[i].archives;//定义obj_a为第i个对象中的【archives】数组
for(var j=0;j<=5;j++){//for循环取【archives】中的6个对象
var obj_b=obj_a[j];//obj_b为数组中的第j个对象
var title=obj_b.name;//title为j对象中的name值
var id=obj_b.id;//id为j对象中的id值
var view_count=obj_b.view_count;//view_count为j对象中的view_count值
var like_count=obj_b.like_count;//like_count为j对象中的like_count值
var author_name=obj_b.author_name;//author_namet为j对象中的author_name值
var author_id=obj_b.author_id;//author_id为j对象中的author_id值
var bvid=obj_b.bvid;//bvid为j对象中的bvid值
record re;
re.id= k;//主键
re.title = title;//视频名
re.videoid = id;//视频id
re.view_count = view_count; //播放量
re.like_count = like_count;//点赞量
re.author_name = author_name;//up主名
re.author_url = "https://space.bilibili.com/"+author_id+"?spm_id_from=";//uo主主页链接
re.videourl ="https://www.bilibili.com/video/"+bvid+"?spm_id_from==";//视频页链接
RESULT.AddRec(re,this.schemaid);
k=k+1;//k自增
}
}
EXTRACT.CloseDoc(doc);//关闭请求⑥采集预览
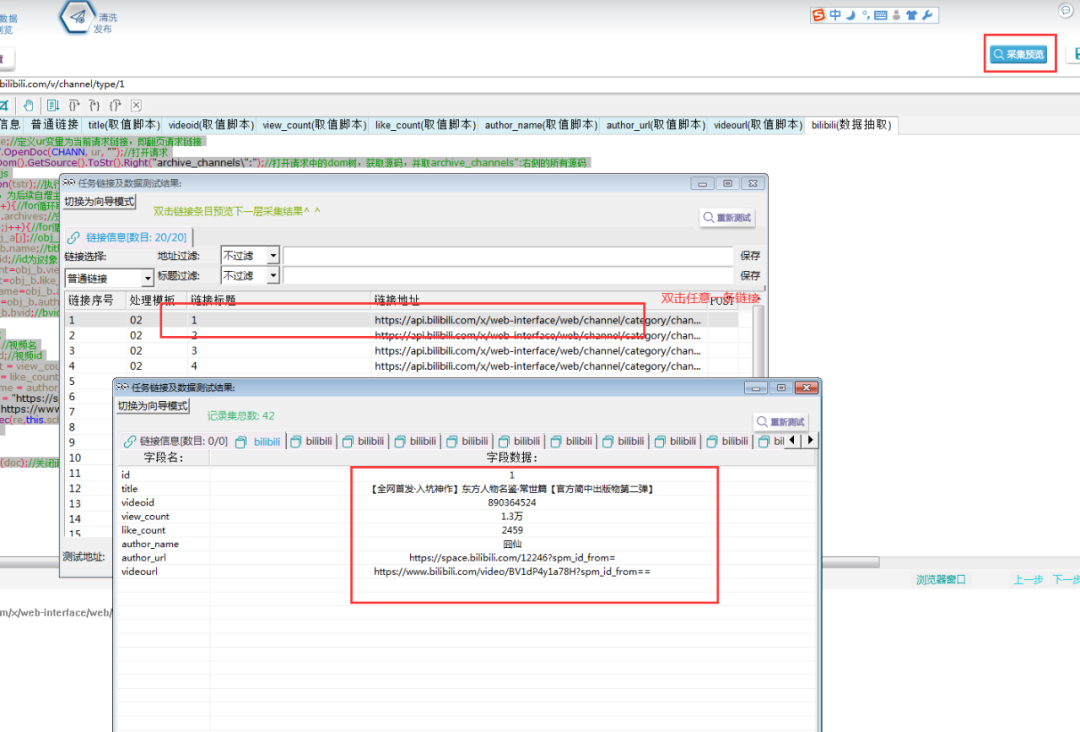
l 采集步骤
模板配置完成,采集预览没有问题后,可以进行数据采集。
①首先要建立采集数据表:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为【bilibili】(注意命名不能用数字和特殊符号),点击【确定】。创建完成,勾选数据表,并点击右上角保存按钮。

②选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。

③采集中:

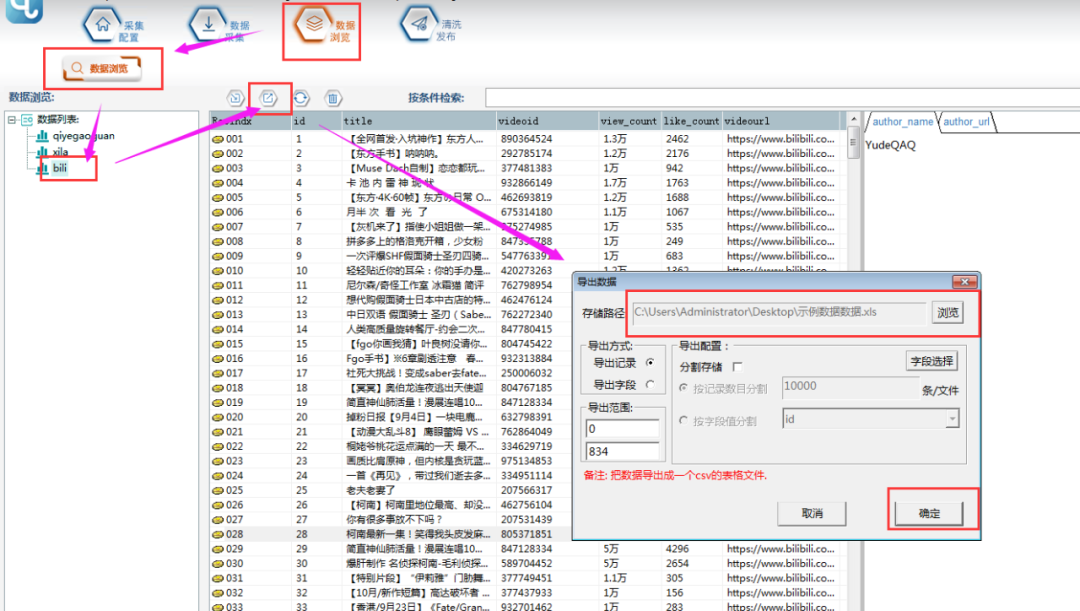
④采集结束后,可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。
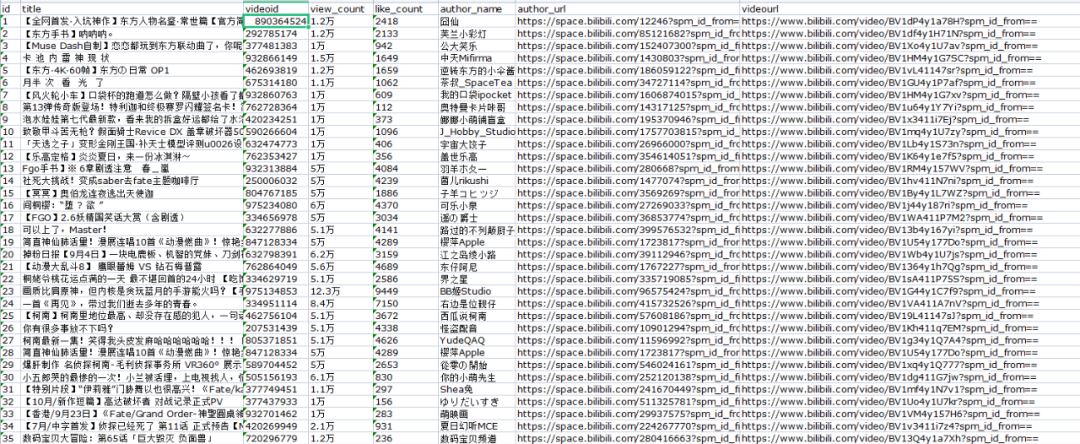
⑤导出的文件打开如下图所示:
l 前嗅简介
前嗅大数据,国内领先的研发型大数据专家,多年来致力于大数据技术的研究与开发,自主研发了一整套从数据采集、分析、处理、管理到应用、营销的大数据产品。前嗅致力于打造国内第一家深度大数据平台!















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









