







 本文详细介绍了Rasa框架,包括Rasa的架构、配置文件、常用命令,以及NLU(自然语言理解)和Rasa Core(对话管理)组件。Rasa NLU涉及Tokenizer、Featurizer和意图识别、实体提取,而Rasa Core则负责根据NLU输出和历史对话信息决定执行的actions。此外,文章还提到了训练数据的构造、自定义组件和策略等关键概念。
本文详细介绍了Rasa框架,包括Rasa的架构、配置文件、常用命令,以及NLU(自然语言理解)和Rasa Core(对话管理)组件。Rasa NLU涉及Tokenizer、Featurizer和意图识别、实体提取,而Rasa Core则负责根据NLU输出和历史对话信息决定执行的actions。此外,文章还提到了训练数据的构造、自定义组件和策略等关键概念。
本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展
1. Rasa介绍
1.1 架构
- Rasa Open Source: NLU (理解语义) + Core (决定对话中每一步执行的actions)
- Rasa SDK: Action Server (调用自定义的 actions)
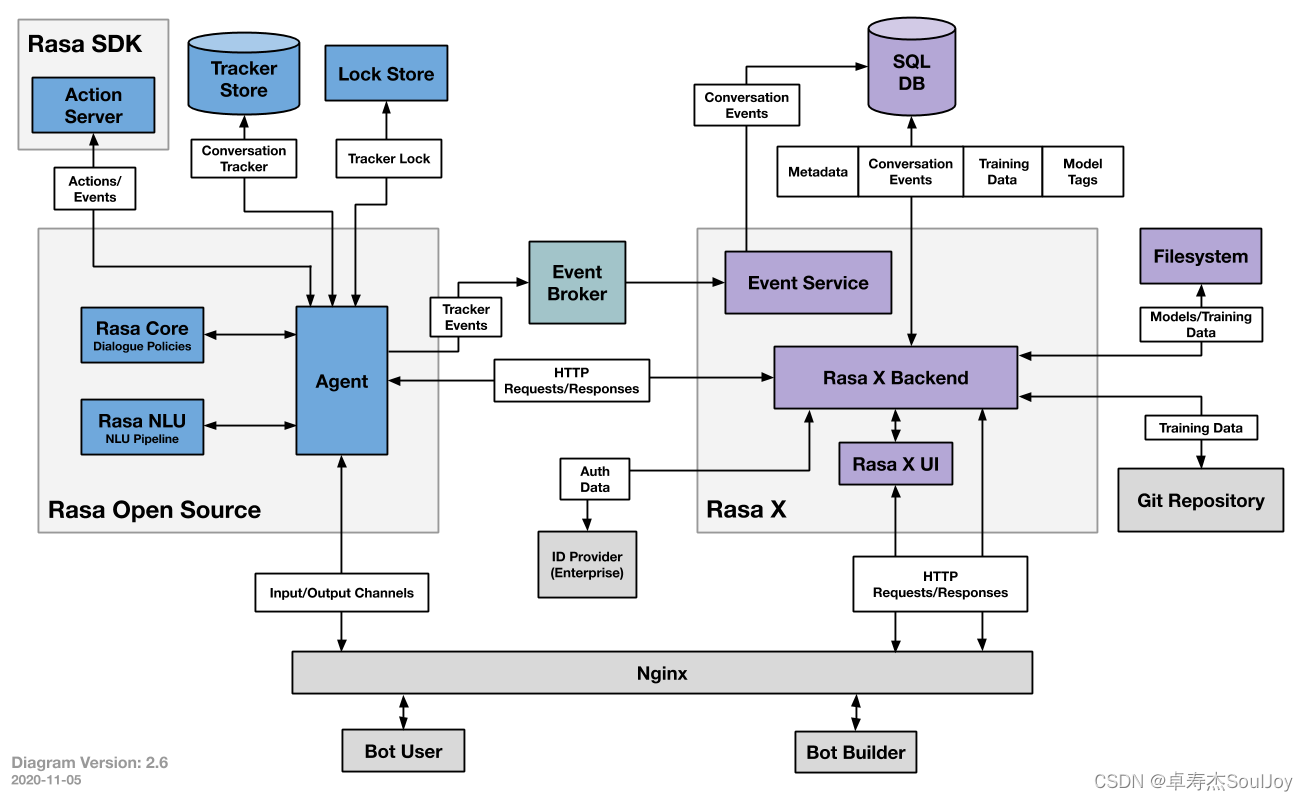
- Rasa NLU
理解用户的对话,提取出感兴趣的信息 (如意图分类、实体提取等),以pipeline的方式处理用户对话,在config.yml中配置。 - Rasa Core
根据NLU输出的信息、以及Tracker记录的历史信息,得到上下文的语境:预测用户当前最可能表达的意图;决定对话中每一步执行哪一个action - Agent
从user来看,它是整个系统的代理,接收用户输入信息,返回系统的回答。在系统内,它是一个总控单元,引导系统启动,连接NLU和DM,得到并调用actions,保存对话数据到存储中 - Action Server
提供了Action和Policy解耦的一种方式。用户可以自定义任何一种action连接到action server上,通过训练学习,rasa可以将policy路由到这个action上。 - Tracker Srore
对话的存储单元,将用户和机器人的对话保存在Tracker Store 中。Rasa提供了针对不同存储类型的开箱即用的实现,包括Redis、MongoDB等。 - Lock Store
是一个ID产生器,使用ticket lock机制来确保全局唯一的conversation ID,并在消息处于活动状态时锁定对话,保证消息的顺序处理。使得多个Rasa服务器可以并行运行,当客户端为给定的conversation ID发送消息时,不需要寻址到相同的节点 - Event Broker
事件代理,bot通过event broker连接到其他服务,可以发布一个消息给其他服务来处理这些消息,也可以转发rasa server的消息到其他服务。目前支持的有SQL、RabbitMQ、Kafka - File System
提供无差别的文件存储服务,比如训练好的模型可以存储在不同位置。支持磁盘加载、服务器加载、云存储加载。
1.2 配置文件
📂 /path/to/project
┣━━ 📂 actions
┃ ┣━━ 🐍 init.py
┃ ┗━━ 🐍 actions.py
┣━━ 📂 data
┃ ┣━━ 📄 nlu.yml
┃ ┣━━ 📄 rules.yml
┃ ┗━━ 📄 stories.yml
┣━━ 📂 models
┣━━ 📂 tests
┃ ┗━━ 📄 test_stories.yml
┣━━ 📄 config.yml
┣━━ 📄 credentials.yml
┣━━ 📄 domain.yml
┗━━ 📄 endpoints.yml
- nlu.yml
本模块会具体针对意图识别,实体提取等任务,配置意图以及触发该意图的文本,提供用户在各种意图下的文本作为examples:询问Query:用户对聊天机器人发出的询问。行动Action: 聊天机器人根据用户询问做出的回应。意图Intent:用户输入蕴含的目的或意图,eg. 用户:你好;intent:打招呼。实体Entity:从用户输入中提取的有用信息
- responses.yml
提供bot在各种类型下的响应,预设定好的内容,不需要执行代码或返回事件。和actions中的response对应,定义格式为utter_intent
responses:
utter_greet:
- text: "今天天气怎么样" #添加文字
image: "https://i.imgur.com/nGF1K8f.jpg" #添加图像
我们在激活form之后,会循环请求slot值,为了让用户知道机器人正在请求哪一个slot值,我们会在responses里添加utter_ask_<slot_name>,使得机器需要填这个槽时,会对用户发出询问。下面是机器需要填name_spelled_correctly这个slot的回复实例:
responses:
utter_ask_name_spelled_correctly:
- buttons:
- payload: /affirm
title: Yes
- payload: /deny
title: No
text: Is {
first_name} spelled correctly?
- stories.yml
提供用户和bot的对话信息作为examples,用来训练bot的 Core (DM) 模型,能推广到看不见的对话路径。
stories:
- story: happy path
steps:
- intent: greet
- action: utter_greet
- intent: mood_great
- action: utter_happy
-
forms.yml
定义表单信息,分别需要哪些slots,以及如何填充slots -
rules.yml
对特定的意图,执行特定的action,始终遵循相同的路径,可用于训练RulePolicy的小部分对话 -
config.yml
定义了 NLU pipeline和Dialogue Policies分别使用了哪些组件 -
domain.yml
列举了bot中包含的所有信息,指定了意图、实体、槽位slot、响应、表格、动作以及对话配置 -
slot
slots是助手机器人的记忆,它可以帮助我们的机器人记住之前实体提取到的信息,从而在后续操作中可以针对用户信息做出应答。
1.3 常用命令
rasa init # 使用自带的样例数据生成一个新的 project
rasa train # 训练模型
rasa test # 测试训练好的 rasa 模型 (默认使用最新的)
rasa interactive # 和 bot 进行交互,创建新的训练数据
rasa shell # 加载模型 (默认使用最新的),在命令行和 bot 对话
rasa run # 使用训练好的模型,启动 server,包括 NLU 和 DM
rasa run actions # 使用 rasa SDK,启动 action server
2. NLU
-
Tokenizer
将文本分割成token,便于导入featurizer进行特征化处理 -
Featurizer
从token中提取特征,特征种类包括稀疏sparse特征和稠密dense特征。所有Featurizer都可以返回两种不同的特征:序列特征和句子特征。序列特征是(number-of-tokens x feature-dimension)维度的矩阵,矩阵包含了句子中每个Token的特征向量,我们用这个特征去训练序列模型,如实体识别。句子特征由(1 x feature-dimension)大小矩阵表示,它包含完整对话的特征向量,可以用于意图分类等。 -
意图识别
配置方法:在example下加入符合此意图的文本。识别意图,rasa NLU提供了两种方法:1. Pretrained Embeddings:使用spaCy等加载预训练模型,赋予每个单词word embedding。Rasa NLU会将一条信息中的所有embedding取平均值,然后通过gridsearch搜索支持向量分类器的最优参数 2. Supervised Embeddings:从开始训练word embedding。得到embedding之后通过分类模型得到intent -
实体提取
实体提取有三种方法:
- 使用预训练模型:Duckling e.g. 提取数字,日期,url,邮箱地址等。SpaCy e.g. 提取名字,商品名称,地点等
- 使用正则 Regex (eg. RegexEntityExtractor):适用于满足特定规则的实体。RegexEntityExtractor 不需要训练示例来学习提取实体,但至少需要提供两个带注释的实体examples,以便 NLU 模型可以在训练时将其标记为实体。
nlu:
- regex: car_type
examples: |
- ^[a-zA-Z][0-9]$
- 使用机器学习的方法。nlu.yml 配置训练数据:实体识别的训练数据需要将文本里的实体内容用[]括起,后面接其所属的实体名字(entity_name)
- intent: 手机产品介绍
examples: |
- 这款手机[续航](property)怎么样呀?
输出结果:包括实体的取值"value",类别"entity",置信水平"confidence"和抽取器"extractor"等的json格式:
{
"entities": [{
"value": "续航",
"start": 20,
"end": 33,
"confidence" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











