









 文章介绍了对话机器人技术的发展,特别是Rasa框架在自然语言处理中的作用。Rasa作为一个全面的开源机器学习框架,包括RasaNLU(自然语言理解)和RasaCore(对话管理),相比传统的基于规则的对话系统如AIML,Rasa提供了更高的效率和灵活性。Rasa支持自定义动作和丰富的对话管理机制,广泛应用于各大企业的对话AI解决方案中。
文章介绍了对话机器人技术的发展,特别是Rasa框架在自然语言处理中的作用。Rasa作为一个全面的开源机器学习框架,包括RasaNLU(自然语言理解)和RasaCore(对话管理),相比传统的基于规则的对话系统如AIML,Rasa提供了更高的效率和灵活性。Rasa支持自定义动作和丰富的对话管理机制,广泛应用于各大企业的对话AI解决方案中。
引言
自然语言是人类表达情感、观念的主要工具和人类思维的重要载体,而最常见的自然语言应用场景则是对话。人们希望通过自然语言控制机器,甚至实现机器与人类的对话与交流。使用自然语言作为输入输出的媒介,会使用户获得更自然友好的人机交互体验,从而为人类生活提供便捷服务。近年来,人工智能技术蓬勃发展,实现基于自然语言的对话系统逐渐成为了人工智能领域的热门研究之一,受到了工业界和学术界的高度重视和广泛关注。如果说自然语言处理是人工智能皇冠上的明珠,那么对话系统就是其中最闪亮的明珠之一。
随着自然语言处理的发展,对话机器人技术也不断更新。现在越来越多的场景需要对话机器人,有纯文本对话的各类助手,如医院导诊的助手,购物网站的智能导购,智能销售客服,证券领域智能投顾等等,也有语音对话机器人,如智能语音外呼系统,智能语音客服系统等。对话机器人因为不同功能场景,不同的应用领域有着各种各样的分类,虽然背后的技术支撑都是自然语言处理,但在具体工程实践中又有一定差别。
对话机器人应用逐渐普及,相关理论和技术不断更新。很多知名企业先后研发并推出了自己的对话系统,如百度开源的基于检索式机器人的框架AnyQ;Google开源的基于生成式对话系统DeepQA;Facebook开源的Blender系统,它具有个性人物聊天的功能,可以知识问答,是有史以来最大的开放域(Open-Domain)聊天机器人;还有Uber开源的Plato系统,也具有比较完整的功能。但要从框架完整性,可扩展性,易用性等各方面来说,Rasa当仁不让是目前最全面的系统之一。
Rasa成立于2016年,为对话AI提供了基础设施层,包括构建上下文助手所需的工具。公司企业端以开源的形式免费提供核心平台和免费工具集Rasa X,也提供商业版,包括企业级对上下文助手大规模开发的支持。Rasa致力于通过更好的研究、对开源软件的投资、优秀的开发人员工具和培训,以及灵活的本地部署或云部署,支持开发人员创建健壮的、任务关键型机器人程序。据统计,全球前十大银行中有六家、全球前十大电信公司中有五家、前十大保险公司中有五家都在使用Rasa的产品。著名客户包括德国电信公司和奥多比系统公司(Adobe Systems Inc .)、巴耶希汽车公司(Bayerische Motoren Werke AG)、空中客车公司(Airbus SE)、英国通用电气公司(ENGIE SA)、美国HCA医疗保健公司(HCA health Inc .)、奥兰治公司(Orange SA)和中国的阿里巴巴等。
本文先介绍对话机器人的发展历史,通过与传统对话机器人进行比较,突出Rasa框架的优势。接着详细介绍了Rasa的组织架构及核心部分。
传统对话机器人
早期的对话机器人架构主要基于模版和规则,如AIML。
规则的描述主要基于正则表达式和类似正则表达式的模版。将用户的问题匹配到这样的模版上,可以取得预定义好的答案好结果。AIML本身有比较强大的描述能力,可通过规则从用户问题中获取重要信息,随机选择备选答案,甚至运行相应的脚本通过外部API获取数据集等。事实上,像AliceBot这样基于AIML的对话机器人,拥有4万多个不同的类别数据,是一个海量的规则数据库。
使用规则的好处是准确率高,但缺点明显:用户的句式千变万化,规则只能覆盖比较少的部分。仅仅像简单的询问天气或者时间,用户就可以有几百种不同的询问方式。随着时间推移,规则会越写越多,难以维护,还常常互相矛盾,改动一个业务逻辑就会牵一发而动全身。此外,对话机器人需要维护一个庞大的问题数据库,对用户的问题通过计算句子之间的相似度来寻找数据库中已有的最相近的问题,从而给出相应的答案。
AIML
AIML,全名为Artificial Intelligence Markup Language(人工智能标记语言),是一种创建自然语言软件代理的XML语言,最初来源于一个名为"A.L.I.C.E."的聊天机器人。AIML通过定义的规则模板进行问答匹配,来实现聊天机器人自动问答的功能。
下面展示了一个最基本的例子,仅包含最主要的<category><pattern><template>三种标签:
<category>
<pattern>你好</pattern>
<template>您好,很高兴认识您。</template>
</category>当用户输入问题“你好”时,机器人就会匹配到这个pattern,然后将<template>中的内容作为答案返回。
AIML的工作流程主要分为以下几步:
1.系统初始化:首先根据配置文件进行系统的初始化操作,再将各类信息以及此前的对话情景变量读入系统,并把知识库以树的结构形式加载到内存当中。
2.接收用户输入:首先把输入的文字分成单独的句子,进行问句规范化处理,如替换字符等。
3.问句查询推理:这一过程是AIML的核心部分,将规范化处理后的问句与内存知识树中的模式进行匹配,寻找最佳匹配结果。
4.模版处理:模板中可能包含一些特殊标记需要处理,如还原星号部分所代表的内容,模板处理完后返回用户结果,等待用户输入新问句。
Rasa体系结构
Rasa是一个用于构建对话机器人的开源机器学习框架。它拥有大量的可扩展特性,几乎覆盖了对话系统的所有功能。相较于传统的对话机器人框架,Rasa更具高效性和灵活性。
Rasa框架的核心部分可以分为Rasa和Rasa SDK。
Rasa又可以细分为Rasa NLU和Rasa Core两个子部分。Rasa NLU主要负责将用户的输入转换成意图和实体信息,这一过程就是自然语言理解(Natural Language Processing,NLU)。Rasa Core主要负责基于当前和历史的对话记录,决策下一个动作(action),下一个动作可能是回复用户某种消息、调用用户自定义的动作类(class)。
RASA的NLU为开发人员提供了解消息,确定意图并捕获关键上下文信息的技术。支持多种语言,单一和多种意图,以及预训练和自定义实体等功能。其主要依赖于自然语言处理技术,是可以独立的、与整体框架解耦的模块,支持大量NLP前沿技术,以组件的形式,可以灵活与其他开源框架搭配使用。RASA的CORE提供了多轮对话管理机制,使用Transformer技术自动学习上下文的与当前意图的关联性,而不是比较固定的状态机,再结合RulePolicy,提供了最大的灵活性。
Rasa SDK是Rasa提供的帮助用户构建自定义动作的软件开发工具包。大多数机器人都需要调用外部服务来完成功能。例如,天气查询机器人需要天气信息服务商的接口来完成实际天气情况的查询,订票机器人需要调用第三方数据接口来完成车票信息的查询及订购。在Rasa中,这种由具体业务决定的动作被成为自定义动作(custom action)。自定义动作运行在一个单独的服务器进程中,也被称为动作服务器(action server)。动作服务器通过HTTP和Rasa Core进行通信。
值得一提的是,Rasa在软件包的规划上是经过充分考虑的。按照软件系统的结构反映组织结构的理论,也就是著名的康威定律,Rasa NLU和Rasa Core属于结合比较紧密的,都位于名为Rasa的软件包中,而Rasa SDK单独成为一个软件包。如此设计是考虑到通常情况下Rasa NLU和Rasa Core由算法团队负责,而自定义动作的开发由Python工程师团队负责。两个团队可以在低耦合的情况下,各自独立开发,独立部署,独立改进,从而提高工作效率。
除了上面介绍的核心部分外,Rasa还包括很多内容,Rasa的体系结构如下图所示:
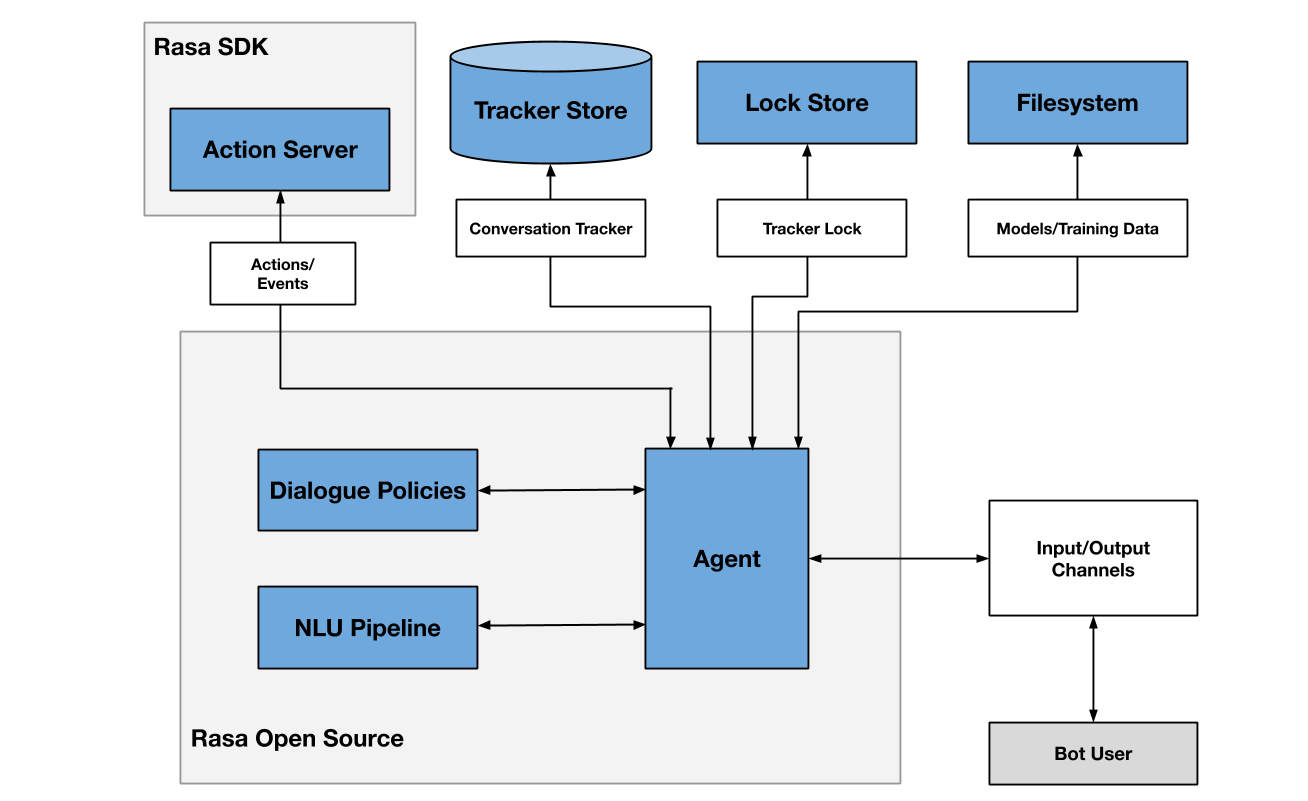
1.图中NLU Pipline指Rasa NLU的流水线组件,Dialogue Policies即对话策略管理,属于Rasa Core部分。
2.Agent:从用户角度来看,Agent就是整个Rasa系统的代理,主要是接收用户输入消息,返回Rasa系统的回答。从Rasa角度来看,它连接自然语言理解(NLU)和对话状态管理(DSM),根据Action得到回答,并且保存对话数据到数据库。
3.Action Server:提供了Action与Policy解耦的一种方式。用户可以定义任何一种Action链接到Action Server上,通过训练学习,Rasa可以将Policy路由到这个Action上。此外,通过Rasa SDK可以实现Rasa的一个热插拔功能,比如查询天气预报等。
4.Tracker Store:将用户和Rasa机器人的对话存储到Tracker Store中,Rasa提供的开箱即用的数据库包括PostgreSQL、SQLite、Oracle、Redis、MongoDB、DynamoDB,当然也可以自定义存储。
5.Lock Store:一个ID产生器,当Rasa集群部署的时候会用到,当消息处于活动状态时锁定会话,以此保证消息的顺序处理。
6.Event Broker:简单理解就是一个消息队列,把Rasa消息转发给其它服务来处理,包括RabbitMQ、Kafka等。
7.FileSystem:提供无差别的文件存储服务,比如训练好的模型可以存储在不同的位置。支持磁盘加载,服务器加载,S3这样的云存储加载。
8.Channel:channels连接用户和对话机器人,支持多种主流的即时通信软件对接Rasa。
Rasa NLU
Rasa NLU负责意图(intent)识别和实体(entity)提取。例如当用户键入“明天北京的天气如何?”,Rasa NLU识别该句子的意图为查询天气,相应的实体信息包括:明天是日期;北京是城市。
Rasa NLU使用基于监督学习的算法来实现功能,因此需要开发者提供适当数量的语料,语料包含意图信息和实体信息。从结构上来说,训练数据都在键为nlu的列表中。列表中每个元素都是一个字典,依靠字典中某个具有特殊含义的键来区分不同字典的功能。如intent键表示意图识别的相关训练语料,除此外还有同义词(synonym)、查找表(lookup)、正则表达式(regex)等键。
Rasa NLU在软件架构上设计得很灵活,允许开发者使用不同的算法来实现功能,这些算法的具体实现被称为组件(component)。 此外,为了让组件灵活配置和维持正确的前后组件的依赖关系,Rasa NLU引入了基于有向无环图的组件配置系统。有向无环图描述了模型中组件之间的依赖关系,以及数据如何在它们之间流动。在Rasa NLU中,该无环图被称为流水线(pipline)。为了完成实体提取和意图识别两个任务,一个典型的Rasa NLU流水线通常包含以下组件:
1.语言模型组件
2.分词组件
3.特征提取组件
4.NER组件
5.意图分类组件
6.结构化输出组件
Rasa Core
Rasa Core是Rasa体系中负责对话管理的部分,主要职责是记录对话的过程和选择下一个动作。Rasa Core是一种机器学习驱动的对话管理引擎。
领域(domain)是Rasa NLU中很重要的一个部分。领域中定义了对话机器人需要知道的所有信息,包括意图、实体、词槽、动作、表单和回复。这些信息对模型的输入和输出进行了明确的范围指定,意图和实体表示输入范围。词槽和表单相当于内部的变量,用于表征状态和存储记忆。动作给定了模型输出的范围。回复字段作为对话机器人回复的模版,既可以认为是一种简单的动作,又可以认为是复杂动作的自然语言生成步骤。

















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









