









 本文介绍对话机器人的发展历程,从基于模板的传统方法到利用NLU、DM、NLG等现代技术的智能对话系统,并详细讲解Rasa框架的安装、配置及应用。
本文介绍对话机器人的发展历程,从基于模板的传统方法到利用NLU、DM、NLG等现代技术的智能对话系统,并详细讲解Rasa框架的安装、配置及应用。
目录
3.4 Rasa常用命令
前言
人机对话是一个很难的问题,在商业与技术上都没有固定的套路,被称为NLP领域中“王冠上的钻石”。
一、传统对话机器人架构
早期的对话机器人架构主要基于模板和规则,如AIML(Artifical Intelligence Maekup Language)。这里以AIML的查询天气模板为例讲述规则系统。
<?xml version="1.0" encoding="utf-8"?>
<aiml version="1.0">
<category>
<pattern>*</pattern>
<that>你现在在什么地方</that>
<template>
<think><set name="where"><formal><star/></formal></set></think>
<random>
<li><get name="where"/>是个好地方.</li>
<li>真希望我也在<get name="where"/>, 陪你.</li>
<li>我刚刚看了下<get name="where"/>的天气哦.</li>
</random>
</template>
</category>
<category>
<pattern>外面热吗</pattern>
<template>
你现在在<get name="where"/>,
<system>python getweather.py reltime <get name="where"></system>
</template>
</category>
</aiml>规则的描述主要基于正则表达式。将用户的问题匹配到类似模板,可以取得预定义好的答案。事实上,像AliceBot这样基于AIML的对话机器人,拥有4万多个不同的类别数据,是一个海量的规则数据库。
使用规则的优点是:准确率高,但缺点明显:规则只能覆盖较少部分,且随着时间推移,规则越写越多,难以维护。此外,对话机器人还需要维护一个庞大的问答知识库,对用户的问题通过计算句子之间的相似度来寻找数据库中已有的最相近的问题,从而给出相应答案。
知乎和Quora等问答网站不希望用户提问很多重复的问题,因此对用户的每一个新的问题,这些网站都会和已有的问题进行匹配,从而产生一些skip-thought计算句向量等方法。
二、对话系统流程
当前人机对话按流程主要分为5个部分:
- ASR:语音识别模块;
- NLU:自然语言理解模块;
- DM:对话管理模块;
- NLG:自然语言生成模块;
- TTS:语音合成模块;
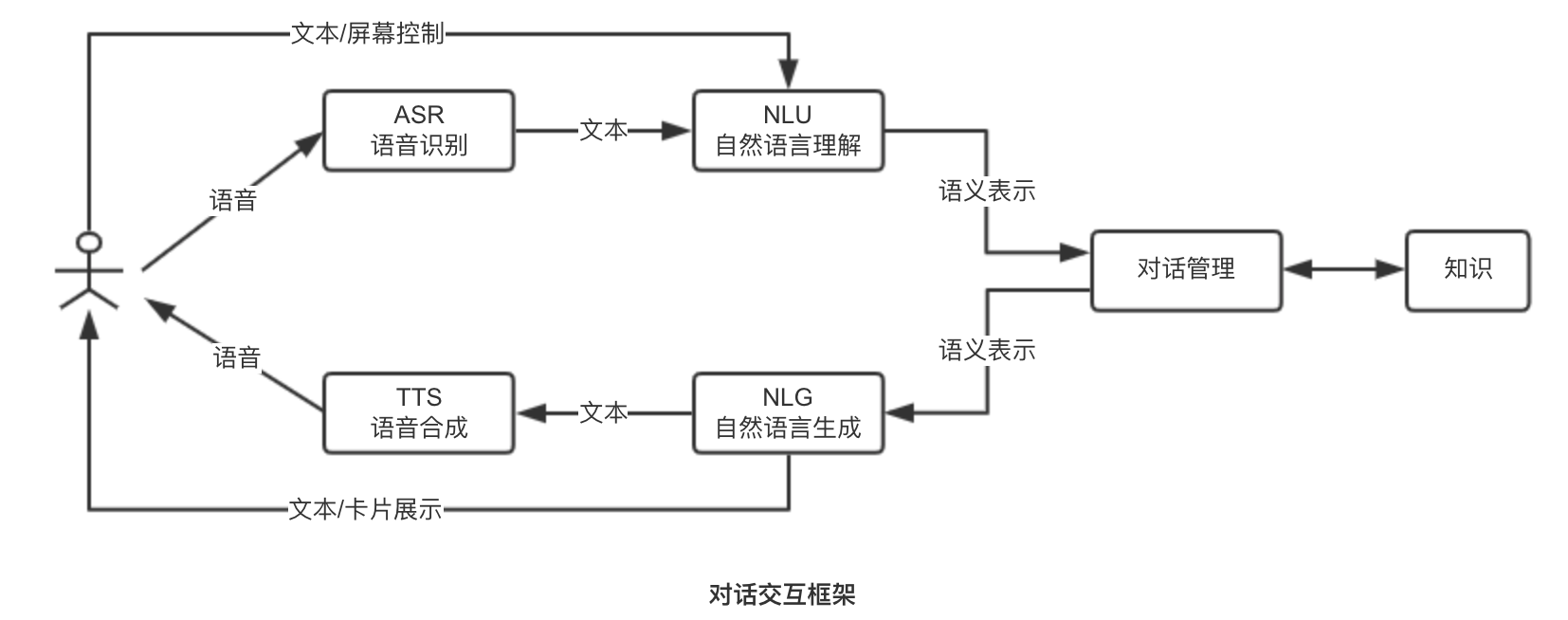
2.1 ASR语音识别
语音识别(Automatic Speech Recognition, ASR)也称语音转文字,是将人类的语音内容转换成相应文字的技术。这方面已经有比较多的商业解决方案(科大讯飞、百度等)和开源项目(Kaldi、DeepSpeech等),技术已经相对成熟。
2.2 NLU自然语言理解
自然语言理解(Natural Language Understanding, NLU)是一个比较宽泛的领域。这里的NLU是指分析用户语言中表达的意图(intent)和相关实体(entity)的技术。
NLU模块主要对用户的就问题在句子级别进行分类和意图识别,同时在词级别找出用户问题中的关键实体,并且进行实体槽填充。举个例子:用户说"我想吃羊肉泡馍",NLU要识别出用户的意图是"寻找餐馆",而关键实体是"羊肉泡馍"。有了意图和关键实体,就方便DM模块对后端数据库进行查询。
从NLP和机器学习角度看,意图识别是一个文本分类问题,实体槽填充是一个传统的命名实体识别问题。两者都需要标注数据。下面是Rasa中NLU数据的格式:
nlu:
- intent: greet
examples: |
- 你好!
- 早上好!
- intent: restaurant_search
examples: |
- 找个吃[拉面](food)的店。
- 这附近哪里有吃[麻辣烫](food)的地方。
这看上去和AIML数据非常像。然而NLU数据实际用到了以这些标注数据训练出的复杂的机器学习模型,表现能力和泛化能力大大增强。只要列出了"拉面"和"麻辣烫",如果出现"凉皮"、"糖葫芦"等词,Rasa良好的NLU系统依旧会把它们标注为食物。
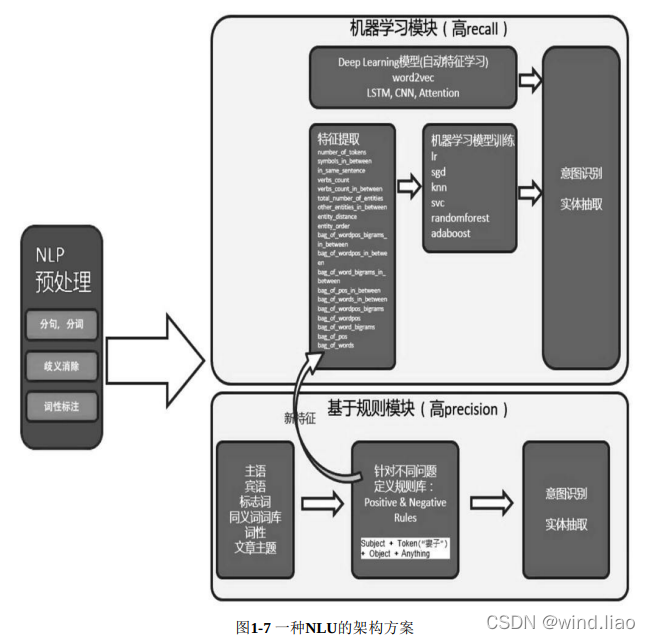
一种常见的NLU架构方案如下图所示,对输入的文本首先经过分句、分词、词性标注等基础自然语言预处理。对某些应用来讲,指代消解是非常重要的步骤。将原有的指代词甚至零指代补全成完整名称,可以消除很多NLU数据的歧义。之后通过机器学习、深度学习、规则等方式进行意图识别和实体标注。
2.3 DM对话管理
对话管理(Dialog Management, DM)是指根据对话历史状态决定当前的动作或对用户的反应。DM模块是对话系统流程的控制中心,有着至关重要的作用。其首要任务是负责管理整个对话的流程。通过对上下文的维护和解析,DM模块要决定用户提供的意图是否明确,以及实体槽的信息是否足够,以进行数据库查询或开始执行相应的任务。
当DM模块认为用户提供的信息不全或模棱两可时,就要维护一个多轮对话的语境,不断引导式地询问用户以得到更多的信息,或者提供不同的可能选项让用户选择。DM模块要存储和维护当前对话的状态、用户的历史行为、系统的历史行为、知识库中的可能结果等。当DM模块认为已经清楚得到了全部需要的信息后,就会将用户的查询变成数据库查询语句去知识库(或知识图谱)中查询响应资料,或者实现和完成相应的任务(如购物下单,或者类似拨打电话等)。
一个DM例子如下图所示:
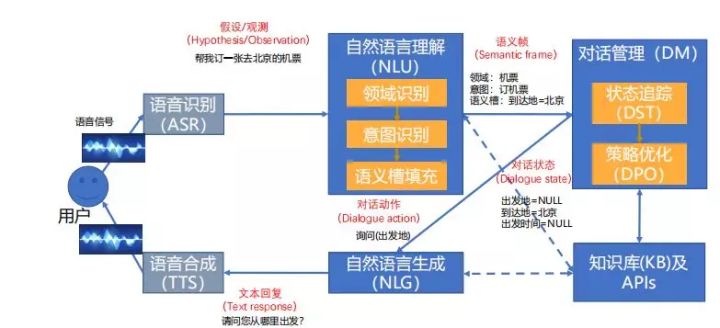
在实际中,DM模块肩负着大量杂活,是与使用需求强绑定的,大部分使用规则系统,实现和维护都比较繁琐。因此,在新的研究中,将DM模块的状态建模成一个序列标注的监督学习问题,甚至用强化学习加入一个用户模拟器来将DM模块训练成一个深度学习模型。我们后面会看到Rasa在其Core模块中是如何简洁又巧妙地实现DM的。
2.4 NLG自然语言生成
自然语言生成(natural Language Generation, NLG)是将意图和相应的实体转换成人类用户可以理解的文本的过程。当前主要的方案有模板法和神经网络序列生成法。模板法比较单一,然而是人工设计的,所以可读性最好。神经网络序列生成法的形式变化多样,类似千人千面,响应的质量和稳定性难以控制。目前在实际应用中,多以模板法为主,对模板法稍加改造(如随机选择一组模板中的一个)以克服其过于呆板的缺点。
NLG模块是机器与用户交互的"最后一公里"。闲聊机器人往往在大量语料上用一个seq2seq的生成模型,直接生成反馈给用户的自然语言。然而在垂直领域的任务型机器人中并不适用,用户需要的是解决问题的准确答案,而不是俏皮话。
当下很多人尝试用深度学习做端到端的以任务为目标的对话机器人,有的基于传统的对话机器人框架,即NLU+DM+NLG,每一个模块都换成深度学习模型,再加入用户模拟器进行强化学习,进行端到端的训练;还有的使用"Memort Networks"方式,偏向于seq2seq,将整个知识库都编码在一个复杂的深度网络中,再和编码过的问题结合起来解码生成答案。这主要应用在机器阅读理解上,注明的斯坦福的SQuAD比赛,有一些神乎其技的结果,但在垂直领域任务导向的对话机器人上的成功应用还有待观察。
2.5 TTS语音合成
语音合成也称文字转语音(Text to Speech, TTS),是将文字转换成人类可以理解的语音技术。TTS已经发展许多年,业界有比较成熟的解决方案,从效果来说达到了可以实用的地步。出于研发成本的考虑,在实际使用中多直接使用专业公司(科大讯飞、百度)提供的TTS引擎或服务。
三、Rasa组件介绍
3.1 Rasa简介
Rasa是一个用于构建对话机器人的开源机器学习框架,几乎覆盖了对话系统的所有功能,是目前主流的开源机器对话机器人框架。
Rasa框架包含4个部分:
- Rasa NLU:提取用户想要做什么和关键的上下文信息;
- Rasa Core:基于对话历史,选择最优的回复和动作;
- 通道(channel)和动作(action):连接对话机器人与用户及后端服务系统(使用界面),支持即时通信软件对接Rasa;
- tracker store、lock store、event broker等辅助系统;
Rasa的核心工作逻辑如下:
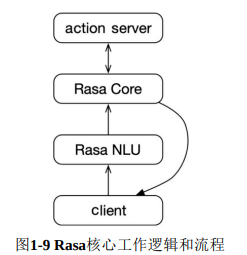
大多数机器人都需要调用外部服务来完成对应功能,例如,在天气查询机器人需要天气信息服务商的接口来完成实际天气情况的查询,订餐机器人需要调用外部服务完成金融消费和餐品下单。在Rasa中,这种由于具体业务决定的动作被称为自定义动作(custom action)。自定义动作运行在一个单独的服务器进程中,也被称为动作服务器(action server)。动作服务器通过HTTP和Rasa Core进行通信。
3.2 Rasa安装
安装Rasa非常容易,在命令行中使用pip命令即可安装。
pip install rasa
3.3 Rasa项目基本流程
构建一个完整的Rasa项目工程会有如下步骤:
(1)初始化项目
(2)准备NLU训练数据
(3)配置NLU模型
(4)准备故事(story)数据
(5)定义领域(domain)
(6)配置Rasa Core模型
(7)训练模型
(8)测试机器人
(9)让人们使用机器人
3.4 Rasa常用命令
Rasa常用命令如下表所示:
| 命令 | 功能 |
| rasa init | 创建一个新的项目,包含样本训练模型、配置和动作 |
| rasa train | 使用NLU训练数据、故事数据、配置训练模型,默认情况下模型保存在./models目录中 |
| rasa interactive | 交互式的训练:通过和机器人对话修正可能的错误,并将对话数据导出 |
| rasa run | 运行rasa服务器 |
| rasa shell | 等价于执行rasa run命令,开启基于命令行界面的对话界面和机器人交流 |
| rasa run actions | 运行rasa动作服务器 |
| rasa x | 启动Rasa X服务器(如果没有安装Rasa X的话会提示安装) |
| rasa -h | 打印Rasa命令的帮助信息 |
3.4 Rasa常用命令
成功安装Rasa后,开发者就可以使用Rasa自带的命令行工具创建一个示例项目:
rasa init
rasa init运行后会询问新创建的项目位于哪里(默认是当前目录),一级创建示例项目后是否立即训练模型(默认是Yes),开发者可以选择No,然后自己通过rasa train命令训练模型。
示例项目创建成功后,选择的项目目录下将会增加如下文件:
—— actions
—— actions.py
—— __init__.py
—— config.yml
—— credentials.yml
—— data
—— nlu.py
—— rules.py
—— stories.py
—— domain.yml
—— endpoints.yml
—— tests
—— test_stories.py所有Rasa命令行工具都默认使用这套文件目录布局,因此这是创建Rasa工程的最佳方法。我们鼓励在命令行中运行rasa train命令来训练这个项目模型,并通过使用rasa shell命令来和机器人进行对话。

















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









