







浅显研究了归一化的内容和代码,想写个文章记录关键信息,及自己的理解
先放个最直观的图(我只重点研究了LN)
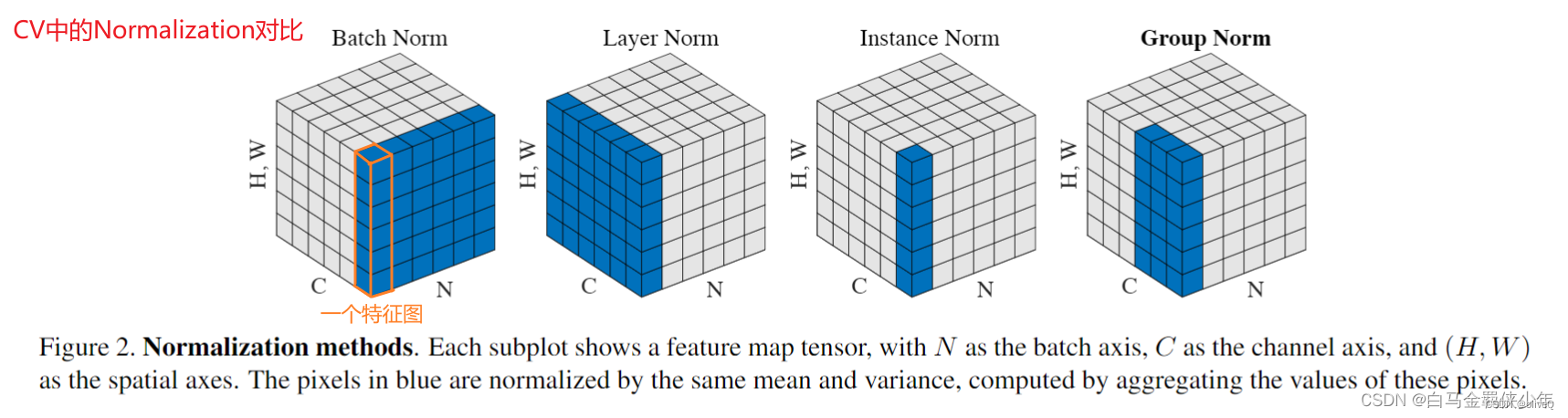
我用三维数据举例:N,C,H:batch_size, channel_size, hidden_dims
LayerNorm
- 适合NLP序列数据:独立于批统计量N=1,计算均值和方差的数据维度(C,H)
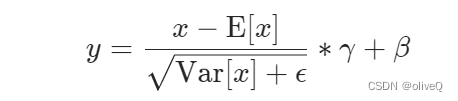
- LayerNorm中没有batch的概念,无法跟踪全局均值和方差,LN是对一个单词的embedding向量进行归一化的。
nn.LayerNorm©中的C(channel_size)是最后的几维,
LayerNorm中weight和bias的shape就是传入的C。
LN是把C这几个轴的元素都放在一起取平均值和方差,假设输入数据的维度为(N, C),将会得到N个平均值和方差,然后对每个元素进行归一化,最后再乘以对应的γ和β(独立)。
- 应用代码:这里认为
seq_len=channel_size, d_model=hidden_dims
不会像BatchNorm那样跟踪统计全局的均值方差,因此train()和eval()对LayerNorm没有影响。
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
"""
inputs: [batch_size, seq_len, d_model]
"""
# inputs shape: [batch_size, seq_len, d_model]
residual = inputs
output = self.fc(inputs)
# output shape: [batch_size, seq_len, d_model]
return nn.LayerNorm(d_model).to(device)(output + residual)
- 实现代码:
class LayerNorm(nn.Module):
# hidden_size
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
# [B,S,H] → [B,S,1]
mean = x.mean(-1, keepdim=True)
# [B,S,H] → [B,S,1]
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
BatchNorm
- 适合CV图像数据:基于批统计量(C=1)来计算样本的均值和方差(N,H)
- 解决各层内部协变量偏移的问题(也许),使损失平面更加的平滑,从而加快收敛速度,因为有批统计量的需求,所以需要使用 指数滑动均值来计算统计量,并保存。
- 缓解了梯度饱和问题(如果使用sigmoid这种含有饱和区间的激活函数的话),加快收敛。
- BN的计算是要受其他样本影响的,由于每个batch的均值和标准差不稳定,对于单个数据而言,相对于是引入了噪声,适合high level(结果和数据的整体分布有关系)
nn.BatchNorm2d©中的C一般是输入数据的第2维(从1开始数),BatchNorm中weight和bias与C一致。
BN是把除了轴C外的所有轴的元素放在一起取平均值和方差,然后对每个元素进行归一化,假设输入数据的维度为(N, C, H, W),将会得到C个平均值和方差,然后对每个元素进行归一化,最后再乘以对应的γ和β(共享)。
- 应用代码:Batch size比较小的时候,效果会比较差。训练阶段利用当前 batch 的均值和方差,测试阶段则利用训练阶段通过移动平均统计的均值和方差。
在pytorch中可以使用model.train()将BatchNorm层切换到train模式。
在pytorch中可以使用model.eval()将BatchNorm层切换到eval模式。
# With Learnable Parameters
m = nn.BatchNorm1d(400) # 例如,房价预测:x的特征数是400,y是房价
# Without Learnable Parameters(无学习参数γ和β)
# m = nn.BatchNorm1d(100, affine=False)
m = nn.BatchNorm2d(3, momentum=0.1) # 例如, CIFAR10数据集是三通道的,3x32x32
print(m.state_dict().keys())
# 输出:odict_keys(['weight', 'bias', 'running_mean', 'running_var', 'num_batches_tracked'])
- 实现代码
import torch
from torch import nn
from d2l import torch as d2l
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# Use `is_grad_enabled` to determine whether the current mode is training mode or prediction mode
if not torch.is_grad_enabled():
# If it is prediction mode, directly use the mean and variance obtained by moving average
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# When using a fully-connected layer, calculate the mean and variance on the feature dimension
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# When using a two-dimensional convolutional layer, calculate the mean and variance on the channel dimension (axis=1). Here we need to maintain the shape of `X`, so that the broadcasting operation can be carried out later
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# In training mode, the current mean and variance are used for the standardization
X_hat = (X - mean) / torch.sqrt(var + eps)
# Update the mean and variance using moving average
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # Scale and shift
return Y, moving_mean.data, moving_var.data
InstanceNorm
- 适合low level(目标与数据分布无关)的数据:instance norm的信息都是来自于自身的图片,相当于对全局信息做了一次整合和调整
- 应用代码:训练与预测阶段行为一致,都是利用当前 batch 的均值和方差计算,在GAN和style transfer的任务中,IN比BN好。
归一化统计量是通过nn.moments函数计算的,决定如何从inputs取值的是axes参数,对应源码中的moments_axes参数。
其中的center和scale便是分别对应BN中的参数β和γ。
def instance_norm(inputs, center=True, scale=True,
epsilon=1e-6, activation_fn=None,
param_initializers=None, reuse=None,
variables_collections=None, outputs_collections=None,
trainable=True, data_format=DATA_FORMAT_NHWC, scope=None)
- 实现代码:对比BN的公式,它只需要它只需要去掉批量维的求和即可。提取源码中的核心部分,并通过注释的方法对齐进行解释(假设输入的Tensor是按N HW C排列的):
inputs_rank = inputs.shape.ndims # 取Tensor的维度数,这里值是4
reduction_axis = inputs_rank - 1 # 取Channel维的位置,值为3
moments_axes = list(range(inputs_rank)) # 初始化moments_axes链表,值为[0,1,2,3]
del moments_axes[reduction_axis] # 删除第3个值(Channel维),moments_axes变为[0,1,2]
del moments_axes[0] # 删除第一个值(Batch维),moments_axes变为[1,2]
EvoNorm
谷歌在算法中也搜索了两类计算,一种是需要使用批统计量的,这一类算法被称为EvoNorm-B系列。一种是独立于批统计量的,这一类算法称为EvoNorms-S系列。而两个系列中评分最高,总体效果最好的,则分别就是EvoNorm-B0和EvoNorm-S0。这就是本文的主角。
EvoNorm-B0
-
这个计算图保证了输入和输出的维度不变,因为归一化层+激活层的特点也是不改变输入维度,只是进行函数映射。
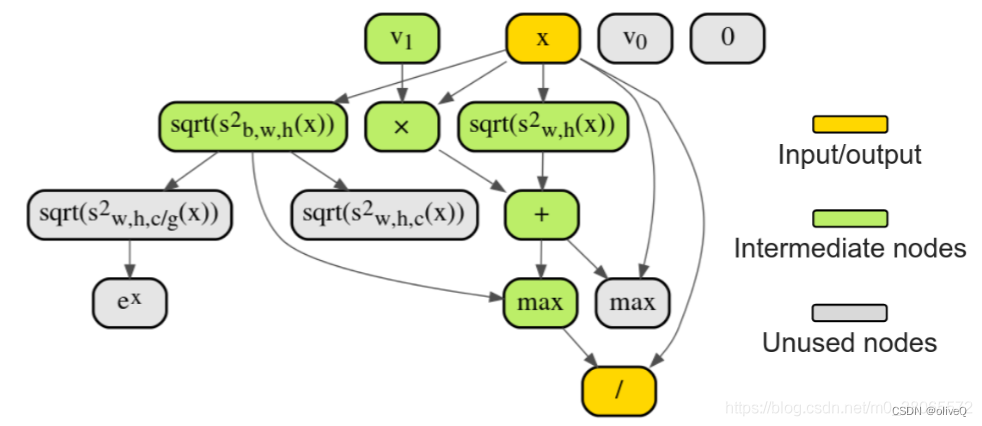
-
特点就是不单单使用一种方差,而是使用两种方差的混合作为分母,前者就是BatchNorm中使用的方差,后者则是InstanceNorm使用的方差,显然这个计算更加复杂
-
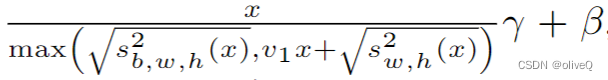
-
前者方差可以在batch中捕获数据的全局信息,而后者则很好捕获每张图像的局部信息。然后在分母上取了最大,这样提供了非线性,连激活函数都省了。
-
实验结果表明,在ImageNet上,在目标检测和分割任务中,甚至在生成任务中,EvoNorm-B0都是相对于BN-ReLU更好的。
EvoNorm-S0
- 对标GN-ReLU这种不需要使用指数滑动均值来计算批统计量的算法
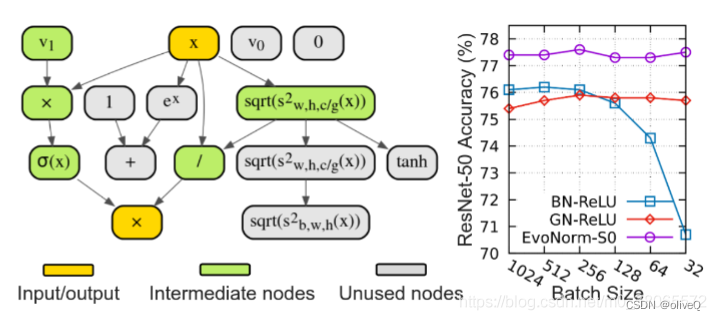
- 分子部分其实就是一个很类似于swish函数的表达式(x没有经过减均值除方差这个标准化),而分母部分,恰好就是GroupNorm的表达式。
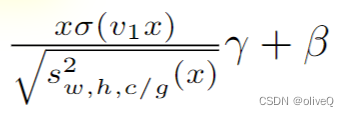
- 实验表明,EvoNorms-S0全都要比GN-ReLU,和GN-Swish要好。
全文参考自:
深入理解NLP中LayerNorm的原理以及LN的代码详解
激活函数发展的新里程——EvoNorms
pytorch:层标准化的实现,Layersnorm
深入理解BatchNorm的原理、代码实现以及BN在CNN中的应用
模型优化之Instance Normalization
Instance norm














 1724
1724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









