







摘至 邹欣《构建之法》一书,以作学习之用
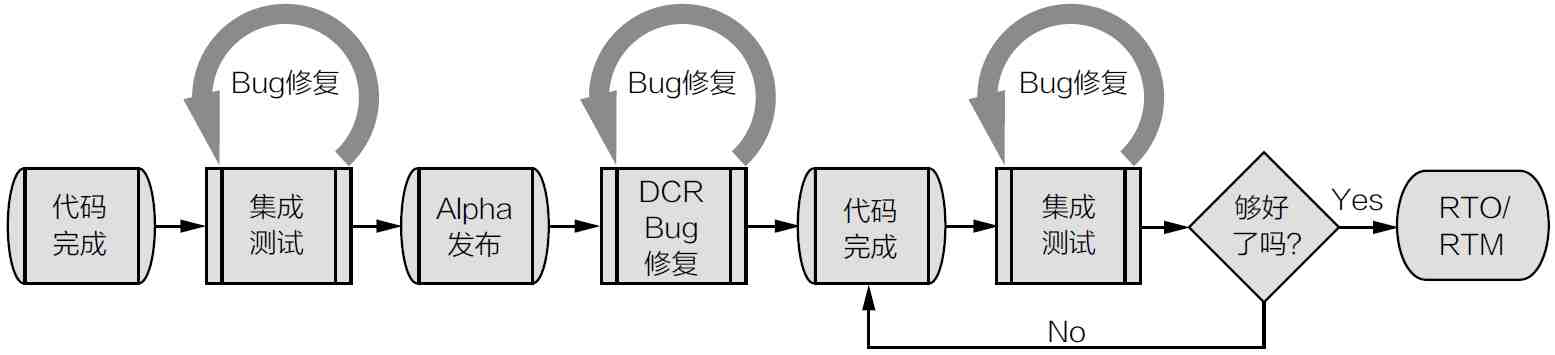
从代码完成到发布
一个团队经历了计划/设计/开发等阶段,达成代码完成(Code Complete)这一目标,似乎后面的事情就水到渠成了。其实不然,软件生命周期的最后阶段往往是最考验团队的,不但考验团队项目管理水平、应变能力,也考验团队的“血型”。原计划的软件发布时间快到了,但是软件还是有各种问题,怎么办?
软件团队的血型
优秀的软件团队会发布有已知缺陷的软件么?在我看来,与人类的血型类似,软件团队也有“血型”,也可以分4种。
A型:他们知道优秀的软件公司会发布有已知缺陷的软件
B型:他们不相信这一点
O型:他们不知道这一点,因此嘴巴惊讶成O型
AB型:他们对于自己开发的软件是A型,对于别人开发的软件是B型
说到“质量”,我们不提“全面质量管理”,因为大家都讲“全面质量管理”,往往意味着我们的质量管理没有抓到点子上。而且有些庸人往往会以“高质量”为由,阻碍正常的工作进程。而那些口口声声要求“高质量”的人士,往往是出于下列情况。
缺乏对用户、行业、软件开发的洞察力,对于“高质量”并没有具体的定义
没有具体的招数让软件达到所谓的“高质量”
害怕真实世界的反馈,因此不发布软件,能拖一天是一天
那么,从软件的代码完成(Code Complete)到最后发布,我们要经历哪些步骤,有哪些招数让我们能以比较大的共识、比较小的痛苦走完这“血腥”的流程,需要什么样血型的团队才能按时推出优秀软件?我们先来看看一些常用的名词。
Alpha:指集成了主要功能的第一个试用版本。在这个版本中有些小功能并未实现。事实上很多软件的Alpha版本只是在内部使用。给外部用户使用的Alpha版本会起一个比较美妙的名字,例如,技术预览版(Tech-nical Preview),等等
Beta: 功能基本完备,稳定性较Alpha版本高,用户可以在实际工作中小范围使用,可以有Beta1、Beta2、Beta3……
ZBB(Zero Bug Build):某天的版本要把在之前(例如48小时前)记录的Bug都解决掉
RC(Release Candidate):发布候选版本,RC1、RC2……直到RTM为止,版本间隔时间较短
RTM(Release To Manufacturer):最终发布版本。如果某一个RC版本没有很大的问题,那么这一RC就会成为最终的版本,通常情况下,软件公司会把最终的版本和相关的文件及其他资料交给另一个团队(Manu-facturer)去包装、刻制光盘。在AppStore/Marketplace的年代,我们有相应的RTM(Release
To Market)
RTW(Release To Web):和RTM类似,对于网络应用来说,我们无须依赖“Manufacturer/Market”制作软件的光盘或者管理软件的发布渠道,但是要依赖“Web”来发布我们的最终版本。如果软件产品是一个网站服务,则一般会交给网站运营团队(Opera-tion Team)去管理,这样的发布也可以叫做RTO(Release To Operation),运营团队和研发团队一起决定什么时候系统上线(Go Live)。把软件提交到各个应用商店则可以称为Release To Store
会诊小组(Triage Team)
软件团队的各个角色代表(PM/Dev/Test/UX等)组成了会诊小组,处理每一个影响产品发布的问题。打个比方,就像医院的门诊或急诊室(TriageRoom),一下子涌入很多病人,但是医院里人手和设备有限,值班的医生护士要根据病人的情况安排不同的处理方法。另一个场景类似但更为紧急,在战地医院里,两次战斗的间隙,医护人员冲上硝烟尚未散尽的战场搜救伤员,有些做简单包扎即可,有些要抬担架,有些伤情太重的,只好放下不管了。大家的血型和勇气在这一次次的会诊中得到了展现。下面的招数都是在会诊小组的领导下进行的。对于每一个Bug,会诊小组要决定采取下面哪一种行动:
修复
设计本来如此(As Designed)//用户或测试人员可能对功能有误解,或者功能的解释不完备
不修复(Won’t Fix)//这是一个问题,但是这个软件版本不打算修复
推迟(Postpone)//如果我们的软件是真正解决用户问题的,是有价值的,那它一定会有下一个版本
在大型复杂项目中,软件团队还会进行更为复杂的会诊工作。
复杂项目的会诊
在稳定阶段的初期,团队只要决定需要修复哪些缺陷,然后团队成员就会进行必要的设计、实现、测试工作,并签入代码修改。但是,随着项目进展和发布日期的临近,团队还要保证修改方案不会给产品带来负面的影响。这时,还要对修改方案进行会诊,包括以下三个方面:
第一步:开发者提交参加会诊的Bug和修改方案
第二步:会议决定是否同意修改方案
第三步:执行
详细说明如下:
第一步:开发者提交参加会诊的Bug和修改方案,以及伙伴测试结果。开发者必须向与会者报告的是:
Bug是什么
危害是什么,如果不修复,有何后果
用户会有什么变通办法
是否经过代码复审,是否经过伙伴测试
第二步:会议决定是否同意修改方案
决定哪些缺陷必须现在就进行修复,哪些可以推迟到下一个里程碑。会诊应该对每一个修复选择下列处理方式。
Must——必须修复,缺陷很严重,修复方案可行,相关的测试都通过
More Info——需要更多的信息,可能的原因有:
- 缺陷的影响不明确,例如,这个缺陷是在任何情况下都发生,还是只在某一特定情况下才出现?后果如何?因此不能马上做出决定
- 相关的测试不完备
- 解决方案有缺陷(会诊会议成员可以复审解决方案和代码的改动)
No——不能接受,可能是推到下一个里程碑,可能是提出的解决方案不符合要求
Like——可能,不一定必须修复,但是解决方案相对比较安全。在更复杂的项目中,可以考虑引入这一个中间的状态“Like”(在相对简单的系统中,这个选项可以不用)。如果在今天的会诊中有“Must”,那么处于待命状态的“Like”修复就可以一起集成到代码库中。如果没有“Must”级别的修复,那么“Like”级别的修复就只能处于“待命”状态,直到以后出现了“Must”级别的修复为止
如果再也没有“Must”的修复,咋办?这些“Like”的修复只好等到下一个里程碑了。这样做的好处是最终发布的版本不会因为一些小的修复而不断地更新,消耗过多的测试资源。
对于管理团队来说,重要的是要通过每天的会诊让团队了解Must/No的标准,帮助团队的成员了解整个项目的现状。举例说明,在每一次会诊之后,列出下面的两个极端情况:
刚超过门槛的修复(The lowest“Must”)——意味着这个修复可以集成到Release代码库中
刚好达不到门槛的修复(The hardest“No”)——意味着这个修复不能集成到Release代码库中。项目接近尾声时,要确保门槛越来越高。今天的“Must”(超过门槛的修复)必须比昨天及以前的“No”严重性要高,这样才能不断提高系统的稳定性。
招数:设计变更(Design Change Request)
经过Alpha/Beta阶段,收到了不少用户的反馈,有些是意料之中的,有些是意料之外的。大家都看到,原来的设计也有不少要改进的地方。有了用户反馈,大家也能够取得比较一致的意见。另外,大家也有了很多新想法。一时间,众说纷纭,很多人都嚷嚷着——DCR,DCR!
重写或重构
重构——在尽量保持原有界面的基础上优化部分代码
重写——重新实现原有功能,同时,要分清是全部重写原有功能,还是偷偷加上许多新的功能(Feature Sneak)?
记住项目的当前阶段是一个阻尼振荡的过程,要收敛和稳定。等到下一个版本开始的时候再进行发散的思考吧。
怎么做DCR?下面列出了DCR的要点:
1. 如何提出DCR?
- 在提交一个DCR时,选用任务作为工作件类型,并在标题中标明DCR
- DCR的描述文字中,说明:
- a. 问题在哪里,问题的影响;
- b. 如果不修改,会有什么后果?
- c. 几种修改方案,各种方案的优缺点和成本。
2. 如何决定DCR的执行次序?
- 会诊所有DCR
- 按照影响、成本排序,得到一个自上而下的名单,根据现有资源,按照名单执行。
另外,适合在Beta分支实现的修改并不一定适用于主分支(Main Branch),我们要做好源代码管理。
招数:ZBB
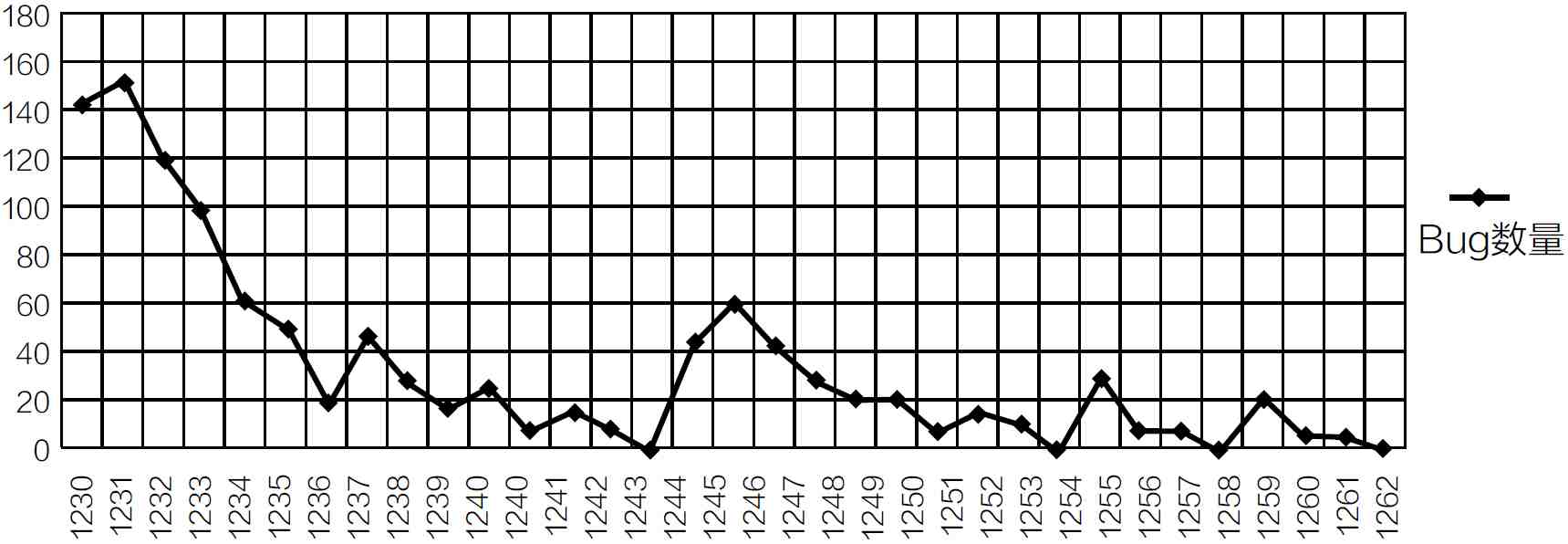
团队要有把Bug都搞定的执行力。ZBB = Zero BugBuild,即这一版本的构建把所有已知的Bug都解决掉了。
Zero Bug Bounce:通常在一个ZBB之后,Bug数目会以惊人的速度反弹,故称Bounce。系统要经历几次反弹,像阻尼振荡一样,Bug的数目在反弹了几次之后,最后固定在(或者无限逼近于)0。
要注意必须要保证Bug的数量到0,以防止一些问题拖而未决,有些Bug长期拖而未决,有可能掩盖了深层次的设计问题,要尽早把这些问题暴露出来,而且划定一个时间期限,一定要解决。
下图是一个60人团队的“预想ZBB进军图”。每个小组的Bug数量累加起来,就是团队的Bug总量。下图中的黑线表示已修复的Bug总量。
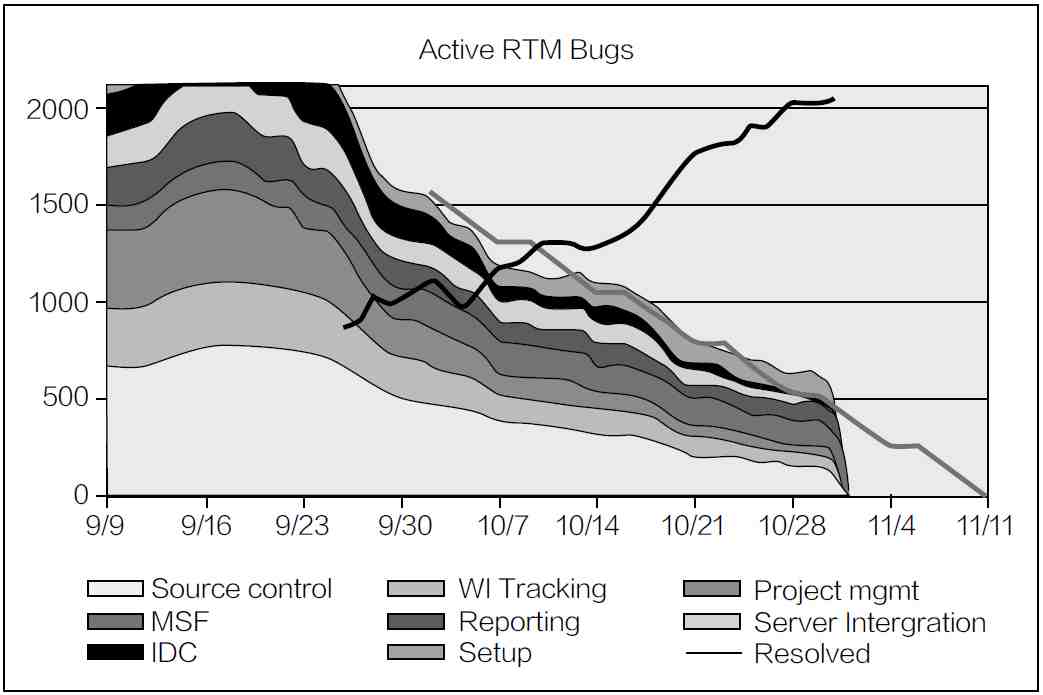
第一个ZBB达到了,同时产生了一个ZBB的构建,由于这个构建质量很好,因此测试团队铆足了劲把各个部分都测试了一遍。同时也测试了复杂的场景,进行了效能和压力测试。结果报出不少新问题。因此ZBB之后的Bounce就跳得特别高。第二次ZBB后,由于各个模块质量的提高,这一次的反弹就低很多,随着每次ZBB过程中质量的加强,Bug的数目会越来越少。同时也有几个功能被砍掉,这些功能的Bug也就不计入总数。下面ZBB的趋势图显示了Bug经过几次反弹,逐渐到0的情况。
招数:最后回归测试
项目临近结束时,所有人员(开发、管理、测试)都要回归测试所有的Bug。每个人都要帮助团队确保这些Bug的确是被修复了,而且别的更改没有导致功能的“回归”。为便于管理,我们可以考虑新增一个字段,标记某个Bug已做过回归测试。
招数:砍掉功能
有一个模块看来不能实现预期的设计需求,时间快到了,怎么办?砍!这是因为“沉没成本”(Sunk Cost)
如果类似的功能需要N个单位时间才能最终完成,那么我们没有理由相信新功能会花少于N个单位时间。我们再回顾一下以前看过的功能/资源/时间的平衡图,我们要不断保持这些因素的平衡:
招数:修复Bug的门槛逐渐提高
在Beta期间,修复Bug的门槛要逐渐提高,昨天修复了同类的Bug,今天如果还找到了类似的问题,团队未必要修复。在RC阶段,只有影响巨大的Bug才能修复。其他优先级较低的Bug就只好在一边等着。如果有严重的Bug要修复,那么这些不严重的Bug也许有机会跟着一起修复。
在Alpha阶段,如果开发人员拿到一个Bug,那他/她就可以马上去修复,只是在签入之后告诉大家做了什么样的修改。
在Beta阶段,在新代码签入之前,就要告诉会诊小组这个修改潜在的风险是什么,如何应对,等等。
在RC阶段,开发人员在拿到Bug进行修复工作之前,就要和会诊小组沟通,看看这个Bug是否值得花时间。
招数:逐步冻结
随着程序功能的完善,我们要让程序的各个方面有次序地“冻结”,这样才能把稳定的软件交付给用户。一般来说,程序的人机交互界面最先开始“冻结”,不能再随意修改,因为很多项目的文字信息要被本地化成多种语言,只有人机界面所用的文字和布局固定后,我们才能把这些文字交给负责本地化的部门。随着时间的推移,一些功能也可以“冻结”,这些功能都经过全面测试,所有的Bug都解决了,功能进入稳定状态,在下一个版本前不要再碰与此功能相关的代码。如果有新的功能要加怎么办?那就在当前源代码的基础上创建分支,让当前版本和将来版本的工作分开进行。
不同频率和不同覆盖范围的渐进发布
上文提到的Alpha,Beta,Beta1,Beta2等发布方式,发布的间隔是一个月以上,一般来说,后一个发布是前一个版本的升级,发布的目标人群也类似。在互联网时代,出现了一个产品同时对不同的目标用户用不同的频率来发布的情况,例如中国小米公司的MIUI软件:
外界一直觉得MIUI每周更新的频率很好,但是这个节奏并不适合每个企业。事实上MIUI的更新频率对不同的用户组是不一样的。MIUI有三个更新频率,一天一更新,面对的用户大概是几千个,这个用户组我们叫荣誉内测组;一周一更新,面对几百万用户,这个组叫开发组;一个月一更新,面对的是90%的普通用户,有几千万,推出的版本叫稳定版。
只有几年历史的小米公司都能成功地运行这样的分级分频率的快速而渐进的发布系统,那么世界上大部分软件公司都应该能做到。
发布之后——事后诸葛亮会议
一个里程碑结束了,接下来怎么办?团队有什么经验教训?产品怎么才能做得更好?我们常说“软件的生命周期”——这个软件开发的周期结束了,生命也结束了。我们能不能像医学的尸体解剖一样,把这个软件开发的流程解剖一下?解剖的过程可以叫:Postmortem,Retrospective,Review,事后诸葛亮会议,等等……
不一定要拘泥于模板,要见机行事,根据会议的进展灵活地变动计划。要牢记会议的核心问题:“如果你可以重新来过,什么方面可以做得更好?”另外,在问“为什么”的时候,要多问几次,层层推进,找到问题的根源。例如:软件发布后用户报告了一个大问题。“为什么?”因为程序没有考虑某种边界条件。“为什么在测试阶段没有测出来?”因为这个代码是测试的最后阶段才加进去的。“为什么不通知PM/Test?”因为Dev认为没有问题的,是很简单的修改。“为什么不通知别人?”因为Dev认为那些都是软件工程无聊的规定……Dev是大牛人,不必遵守的。“为什么?!”问到这个层次,就把问题根源暴露出来了。
现代软件工程 项目回顾(Postmortem)模板
设想和目标
我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述?
是否有充足的时间来做计划?
团队在计划阶段是如何解决同事们对于计划的不同意见的?
用户量、用户对重要功能的接受程度和我们事先的预想一致么?我们离目标更近了么?有什么经验教训?如果历史重来一遍,我们会做什么改进?
计划
你原计划的工作是否最后都做完了?如果有没做完的,为什么?
有没有发现你做了一些事后看来没必要或没多大价值的事?
是否每一项任务都有清楚定义和衡量的交付件?
是否项目的整个过程都按照计划进行?
在计划中有没有留下缓冲区,缓冲区有作用么?
将来的计划会做什么修改?(例如:缓冲区的定义,加班。)
我们学到了什么?如果历史重来一遍,我们会做什么改进?
资源
我们有足够的资源来完成各项任务么?
各项任务所需的时间和其他资源是如何估计的,精度如何?
测试的时间、人力和软件/硬件资源是否足够?对于那些不需要编程的资源(美工设计/文案)是否低估难度?
你有没有感到你做的事情可以让别人来做(更有效率)?
有什么经验教训?如果历史重来一遍,我们会做什么改进?
变更管理
每个相关的员工都及时知道了变更的消息吗?
我们采用了什么办法决定“推迟”和“必须实现”的功能?
项目的出口条件(Exit Criteria——什么叫“做好了”)有清晰的定义么?
对于可能的变更是否能制定应急计划?
员工是否能够有效地处理意料之外的工作请求?
我们学到了什么?如果历史重来一遍,我们会做什么改进?
设计/实现
设计工作在什么时候,由谁来完成?是合适的时间,合适的人么?
设计工作有没有碰到模棱两可的情况,团队是如何解决的?
团队是否运用单元测试(Unit Test)、测试驱动的开发(TDD)、UML或者其他工具来帮助设计和实现?这些工具有效么?
什么功能产生的Bug最多,为什么?在发布之后发现了什么重要的Bug?为什么我们在设计/开发时没有想到这些情况?
代码复审(Code Review)是如何进行的,是否严格执行了代码规范?
我们学到了什么?如果历史重来一遍,我们会做什么改进?
测试/发布
团队有没有测试计划?为什么没有?
有没有做过正式的验收测试?
团队是否有测试工具来帮助测试?
团队是如何测量并跟踪软件的效能的?从软件实际运行的结果来看,这些测试工作有用么?应该有哪些改进?
在发布的过程中发现了哪些意外问题?
我们学到了什么?如果历史重来一遍,我们会做什么改进?
总结:
你觉得团队目前的状态属于CMMI中的哪个级别?
你觉得团队目前处于萌芽/磨合/规范/创造阶段的哪一个阶段?
你觉得团队在这个里程碑相比前一个里程碑有什么改进?
你觉得目前最需要改进的一个方面是什么?
现代软件工程 项目回顾(Postmortem)例子
设想和目标
我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述?
想做的事情还是太多,导致很长时间不能集中精力。是否有充足的时间来做计划?
有时间,但是大部分人并不知道如何利用这一段时间来做计划。团队在计划阶段是如何解决同事们对于计划的不同意见的?
主要通过喝酒聊天解决,另外阿超有某种“光环”,大家对他有些崇拜,这样他说的话别人都比较容易接受,也没有特别强烈的不同意见。
计划
你原计划的工作是否最后都做完了?如果有没做完的,为什么?
很多事情都没做完,大家认为最后没做完的事情,都是可有可无的。有没有发现你做了一些事后看来没必要或没多大价值的事?
很多,但是大家认为与其不断地争论某些事情有没有必要,不如做了再说。是否每一项任务都有清楚定义和衡量的交付件?
大部分都没有,因为我们大家都不知道做到多少才叫“好”。有些情况下,大家对细节过早地进行讨论,花了很多时间。不如等到后来再讨论。是否项目的整个过程都按照计划进行?
基本上,因为阿超的“光环”,大家大部分情况下都听他的。在计划中有没有留下缓冲区,缓冲区有作用么?
有缓冲区,原来认为没有必要,后来发现还是有用的。主要是各人进度不一,有些模块不断地有一些小问题,花了很长时间才能做好。将来的计划会做什么修改?(例如:缓冲区的定义,加班。)
应该明确缓冲区的长度。
资源
我们有足够的资源来完成各项任务么?
很多情况下,花了不少时间来设置机器,以及设置用来测试的数据。各项任务所需的时间和其他资源是如何估计的,精度如何?
开始精度很粗略,后来随着项目任务的加重,大家只顾得上干活,没时间考虑精度问题。用户测试的时间,人力和软件/硬件资源是否足够?
你有没有感到你做的事情可以让别人来做(更有效率)?
比如网页的CSS设计,最好由美工设计来做,开发人员最后做实现即可。我们要有专职的设计,不要临时拉人来帮忙。因为临时帮忙的设计师对整个项目了解不多,事后也找不到他。
变更管理
每个相关的员工都及时知道了变更的消息吗?
由于大家都坐得比较近,小道消息传播得比较快。我们采用了什么办法决定“推迟”和“必须实现”的功能?
用了“银弹”,除了导致一场短时间的斗殴之外,还可以。银弹的目的就是一种威慑。项目的出口条件(Exit Criteria)是否得到清晰的定义?
大家都不太懂“出口条件”是什么,经过这一个项目之后,稍稍清楚了一些。但是说实在的,在这个项目里面我们没有用到太多。对于可能的变更是否能制定应急计划?
基本没有,到时候随意抓人顶上。员工是否能够有效地处理意料之外的工作请求?
规定所有请求都转到PM那里处理,这样减轻了开发人员的压力,让他们有大部分时间花在自己那一亩三分地上。
设计/实现
设计工作在什么时候,由谁来完成?是合适的时间,合适的人么?
有些界面的设计过早,大家为了字体的大小、按钮的尺寸争论,事实上这些事情不应该由开发人员在项目早期来做。设计工作有没有碰到模棱两可的情况,团队是如何解决的?
很多,大家都不知道如何解决。就看具体执行的人是如何解决的,有的解决得好,大家并不知道出过问题;有的经常拿出来讨论,大家都知道问题在哪里,但是没法达成一致。团队是否运用单元测试(Unit Test)、测试驱动的开发(TDD)、UML或者其他工具来帮助设计和实现?这些工具有效么?
运用了单元测试的员工,整体来看Bug不多,没有用单元测试的员工,后期比较忙。TDD要求PM要清楚地确定功能说明(Spec),我们目前还做不到这一点。一个好处是:大家都追着PM要Spec,弄得PM的压力很大,以前谁都不搭理PM的Spec。什么功能产生的Bug最多,为什么?
交易功能由于牵涉的面太多,Bug也最多。代码复审(Code Review)是如何进行的,是否严格执行了代码规范?
刚开始还像那么回事,后来就变成走走形式。往往是“小飞,我要提交代码了,审核人填你的名字,怎么样?”其实小飞后来也没看代码。
测试/发布
团队有没有测试计划?为什么没有?
我们有测试计划,而且因为有了计划,测试人员好像不再像无头苍蝇一样胡乱测试。有没有做过正式的验收测试?
有些测试人员最后不敢说验收测试不成功,似乎是迫于某些开发人员的“淫威”。团队是否有测试工具来帮助测试?
有。团队是如何测量并跟踪软件的效能的?从软件实际运行的结果来看,这些测试工作有用么?应该有哪些改进?
TFS还是很有用的,至于改进,有这样一些建议:- 输入Bug还是步骤比较多,有很多需要手动重复填写的字段。
- 不是所有的Bug或Task都记录在TFS中。
在发布的过程中发现了哪些意外问题?
有些功能在新的机器上不能工作,因为很多设置没有明确的定义,也没有记录。软件发布时,这些设置没有能正确地拷贝到发布的机器上去。这说明很多关于这个系统的“知识”还没有形成文字,还是保留在某些人的脑袋中。我们学到了什么?如果历史重来一遍,我们会做什么改进?















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









