







1. 为什么需要模型评估

- 我们可以借助图像来判断模型是否良好。
- 但当我们用单一特征来绘制f(x)图像时,模型容易出现过拟合现象。但如果增加一些输入特征的种类,绘制图像又会变得很困难。而模型评估可以解决这一痛点。
2. 模型评估

- 通常我们将数据集的一大半设为训练集,一小半设为测试集。mtrain表示训练样例的个数,mtest表示测试样例的个数。

- 对线性回归模型,我们可以用带正则化项的成本函数来得到使成本函数最小的w、b
- 可以通过不带正则化项,且数据为测试集来得到模型是否在新数据上表现良好,即不过拟合,能很好的泛化新数据
- 可以通过不带正则化项,且数据为训练集来得到模型是否在训练集上表现良好
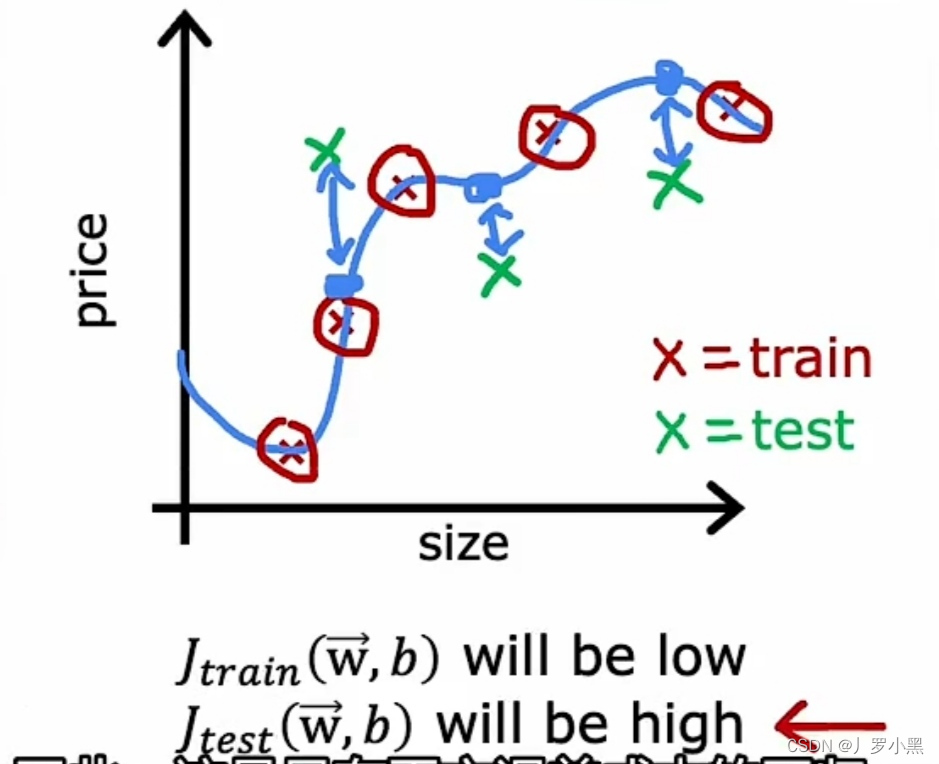
- 上图为线性回归模型过拟合的Jtrain、Jtest图像,它虽然能很好的拟合训练集,即Jtrain的值很小,但不能很好的拟合测试集,即Jtest的值很大

- 对逻辑回归模型,依然可以使用带正则化项的成本函数来得到使成本函数最小的w、b
- 用Jtest、Jtrain来判断模型对测试集和训练集是否拟合良好,而Jtest、Jtrain仍然不带正则化项

- 对于逻辑回归模型,还有一种方法用来判断模型是否对测试集和训练集拟合良好
- 分别计算Jtrain、Jtest对训练集和测试集分类错误的比例,并用此来判断模型是否拟合良好
3. 模型选择

- 用训练集数据生成的w、b组成的f(x)模型,对于训练集一般是过拟合,对测试集则是欠拟合,即训练误差Jtrain要比测试误差Jtest少很多,但Jtest比Jtrain更公平,在表示该模型对不在数据集中的新实例的泛化能力是否良好方面
- 选择模型的标准是泛化能力,泛化能力是指针对从未出现的新实例的拟合能力。因此不能使用Jtrain来判断,通过训练集得到w、b的模型是否泛化良好

- 引入超参数d,表示模型的多项式阶数,即不同模型的分类
- 使用测试集数据,计算每个d对应的Jtest,来得到一个能使测试误差最小的d,即对应的模型。
- 但此时只得出了在d的范围内,能使Jtest最小的模型,仍需要判断此模型是否良好,即泛化能力。注意:已经使用了测试集,不能再用测试集进行判断,会过拟合
4. 交叉验证集
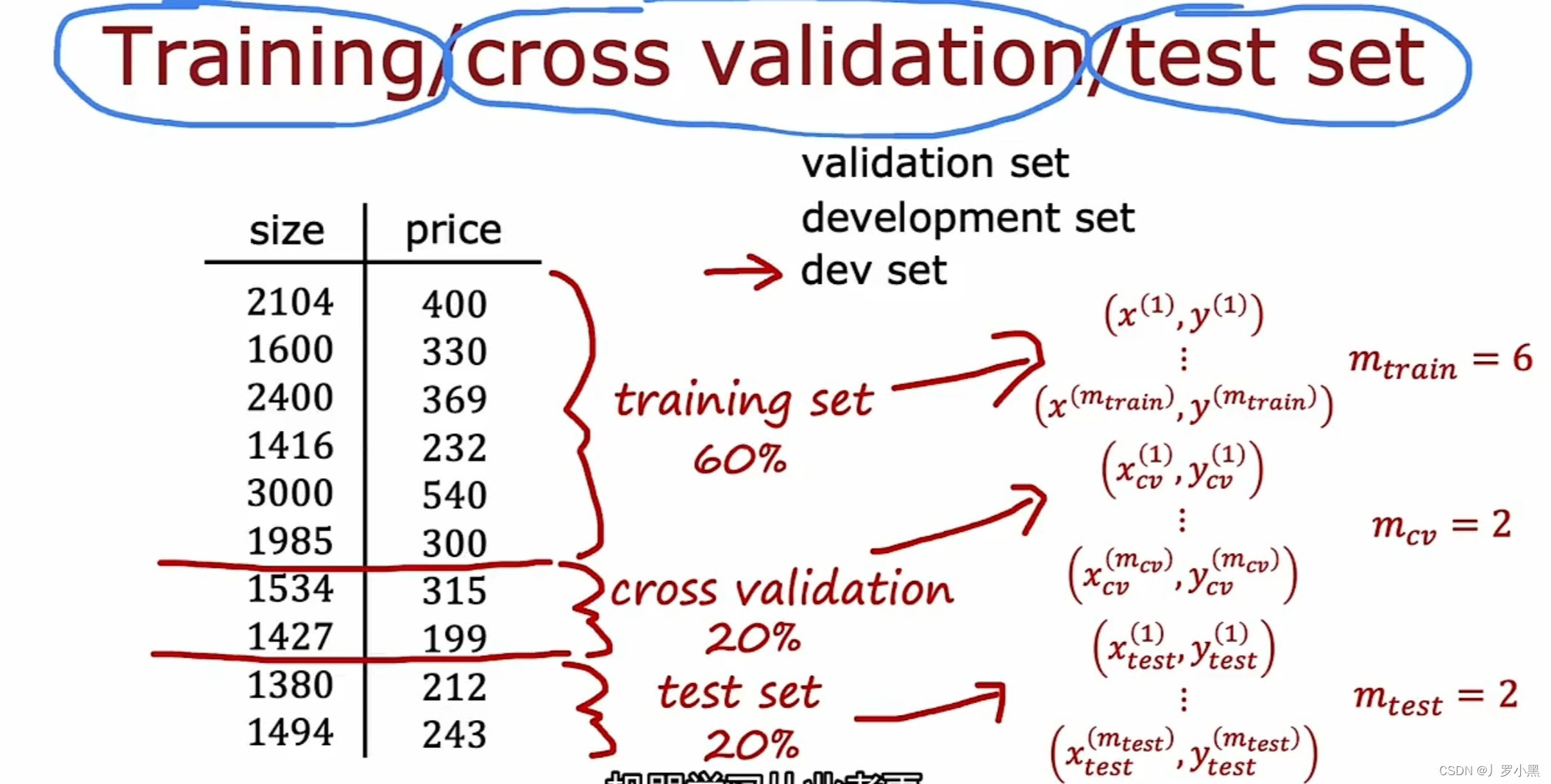
- 交叉验证集也叫开发集,至此,数据集共分为三部分:训练集、交叉验证集、测试集。

- 训练误差、验证误差、测试误差的公式如图,且都不包括正则化项

- 如上图所示:训练集–拟合w、b得到许多模型,验证集–拟合d挑选最优模型,测试集–测试模型的泛化能力

- 若为逻辑回归,则Jcv可以改为计算交叉验证集分类错误的比例
- 训练集在不同模型上拟合出每个模型的最优w、b,交叉验证集再从拟合好的模型中选择一个最优的模型,测试集最后测试这个模型的泛化能力
- 为了保证模型对新数据的泛化程度有公平的估计,在确定最终模型之前,不能使用测试集对模型有任何评估,只能使用训练集和交叉验证集















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











