








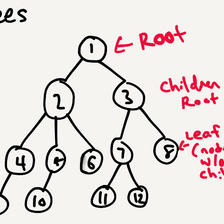
二叉查找树
介绍
二叉查找树(排序二叉树),是一种支持快速查找、插入、删除的数据结构。

它的特点是,每个结点必须大于它的左子树的所有结点,小于右子树的所有结点。通常,结点里携带的是一个记录,而不是一个单独的值(如上图),在比较的时候,用记录的关键字来比较的。
二叉搜索树最主要的优点,是和它对应的排序算法和搜索算法,比如用中序遍历,效率高,而且容易实现。
二叉搜索树通常作为其他高级数据结构的底层容器。比如set,multiset,associative array。
不过也有缺点。
- 多次随机的插入,删除后,树的高度变得不平衡
- 如果关键字比较长,那会花太多时间在于比较上。因为几乎每个操纵都要比较很多次。
实现
删除操作。这里有三种情况需要考虑。(假设找到的结点为N)
- N没有孩子结点。直接删除。
- N只有一个孩子结点。删除N,并用它的孩子结点代替它。
- N有两个孩子结点。先不去删除N,而是找到N的下一个中序遍历结点,或者上一个中序遍历结点,什么意思?我们知道,BST的左子树所有的结点都比根节点小,最接近根节点的节点(即左子树中最大的节点)是哪个呢?当然是左子树中最右的结点,也就是根节点中序遍历下的上一个节点。同理,右子树最小的节点就是根节点中序遍历的下一个节点。(下图6就是7的in-order predecessor,9是7的in-order successor)

void remove(const T& x, NodeRef& root) { if (root == nullptr) return; if (x == root->val) { // no children if (root->left == nullptr && root->right == nullptr) deleteNode(root); // two children else if (root->left != nullptr && root->right != nullptr) { // find p's in-order predecessor NodeRef predecessor = findMax(root->left); root->val = predecessor->val; root = predecessor; remove(root->val, root); } // one child else { if (root->left == nullptr) { NodeRef t = root; root = root->right; deleteNode(t); } else { NodeRef t = root; root = root->left; deleteNode(t); } } }插入操作。思路就是不断比较key,然后找到空节点。
NodeRef insert(const T& x, NodeRef& root) { if (size_ == 0) { size_++; root->val = x; return root; } if (root == nullptr) { size_++; root = newNode(x); return root; } if (x < root->val) return insert(x, root->left); else if (x >= root->val) return insert(x, root->right); }
AVL树
介绍
AVL树由两个苏联人,G. M. Adelson-Velskii , E. M. Landis 在1962年提出,他们是第一个提出平衡二叉搜索树概念的。这东西伟大在哪?AVL树能使树的高度保持平衡,从而把原先二叉搜索树操作的的最坏时间从O(N)降低到了O(logN)。

它其实是基于二叉搜索树之上实现的,只不过加了些功能来保证树的平衡。下面来看看,具体有哪些功能。
实现
首先,我们对树的节点引入了高度值。这里高度用一个字节来存储是为了节省空间。
struct TreeNode
{
NodePtr left;
NodePtr right;
unsigned char height; // can save space when meet large amount of nodes
T val;
TreeNode(const T& x) : val(x) , height(1) {}
};我们还需要一些辅助函数。(因为会频繁调用,所以让它们的时间复杂度都是O(1)吧)
// helper functions
unsigned char getHeight(NodePtr &p) {
return p?p->height : 0;
}
int getFactor(NodePtr &p) {
return getHeight(p->right) - getHeight(p->left);
}
void fixHeight(NodePtr &p) {
unsigned char hl = getHeight(p->left);
unsigned char hr = getHeight(p->right);
p->height = (hl > hr ? hl : hr) + 1;
}接下来是关键算法,单旋转。图左通过右旋就能得到图右,反之同理。好,现在观察图左,你只要想象用手拎着q结点,往上一拉,然后再把q的右子树B挂到p的左边就完成了一次右旋。

双旋转。其实就是按照不同的情况,应用两次单旋。观察下图,就是先对q来一次右旋,然后对p来一次左旋。这是特例,其他的情况该怎么分析,是要根据它们的平衡因子来看的。

用代码来解释就是这样。
NodePtr balance(NodePtr &p) {
fixHeight(p);
if( getFactor(p) == 2)
{
if( getFactor(p->right) < 0)
p->right = rotateRight(p->right);
return rotateLeft(p);
}
if( getFactor(p) == -2)
{
if( getFactor(p->left) > 0)
p->left = rotateLeft(p->left);
return rotateRight(p);
}
// if no balance need, return itself
return p;
}注意事项,因为所有对树的修改操作,都可能引起高度变化,所以对于这些类型的操作,我们都需要返回新的树的节点。这和普通的二叉搜索树是不一样的。
所以插入函数就变成了这样。思路还是和上一篇的BST版本一样。
NodePtr insert(const T& x, NodePtr& root)
{
if (size_ == 0)
{
size_++;
root->val = x;
return root;
}
if (root == nullptr)
{
size_++;
root = newNode(x);
return root;
}
if (x < root->val)
{
root->left = insert(x, root->left);// 因为重新修改了节点,所以需要更新
return balance(root);// 它修改的
}
else if (x >= root->val)
{
root->right = insert(x, root->right);
return balance(root);
}
}删除函数。
NodePtr remove(const T& x, NodePtr& root)
{
if (root == nullptr)
return nullptr;
if (x < root->val)
root->left = remove(x, root->left);
else if (x > root->val)
root->right = remove(x, root->right);
else // x == root->val
{
NodePtr l = root->left;
NodePtr r = root->right;
if( !l && !r) return nullptr;
if(!l && r) return r;
if(l && !r) return l;
NodePtr min = findMin(r);
root->val = min->val;
root->right = removeMin(root->right);
}
return balance(root);
}效果
为了检验实际效果和理论效果的差别,实验通过随机产生1000个数插入到树中,记录树的高度变化,然后综合多组数据画图。(纵坐标是树的高度,横坐标是节点数;红线是平均高度,绿线是最小高度,蓝线是最大高度,两条边界线代表上界和下界)

红黑树
介绍
花的时间太长了,目前只实现了RB树的插入操作,删除操作要考虑的case有点多,比较难,建议时间充裕的时候再去折腾。
推荐July的rbtree系列文章。
http://blog.csdn.net/v_JULY_v/article/details/6124989
http://blog.csdn.net/v_JULY_v/article/details/6114226
实现
可以看看这个人的代码
https://github.com/peterwilliams97/strings/blob/master/cst/rbtree.cpp
应用
stl里map,set的底层容器就是红黑树。顺便说一下,map和hash_map的区别就在于底层实现,后者需要hash函数,前者只需要定义一个key的比较器就行了。不过它们用起来还是差不多的。
参考资料
http://kukuruku.co/hub/cpp/avl-trees
https://en.wikipedia.org/wiki/AVL_tree















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









