









维度建模三种模式

一、星型模型
是最简单和常用的模型,它以一个事实表为中心,周围连接着多个维度表。事实表包含主要的业务数据,而维度表则用于描述事实表中的数据。
但由于其结构简单明了,查询效率较高,因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
★优点: 简单易理解、易于查询和数据仓库的高性能,良好的数据完整性和灵活性,可以轻松地添加或删除维度属性。
★缺点: 处理大规模、复杂数据时可能会出现瓶颈,而且它可能会消耗较多的存储空间和带宽,时效性跟不上。
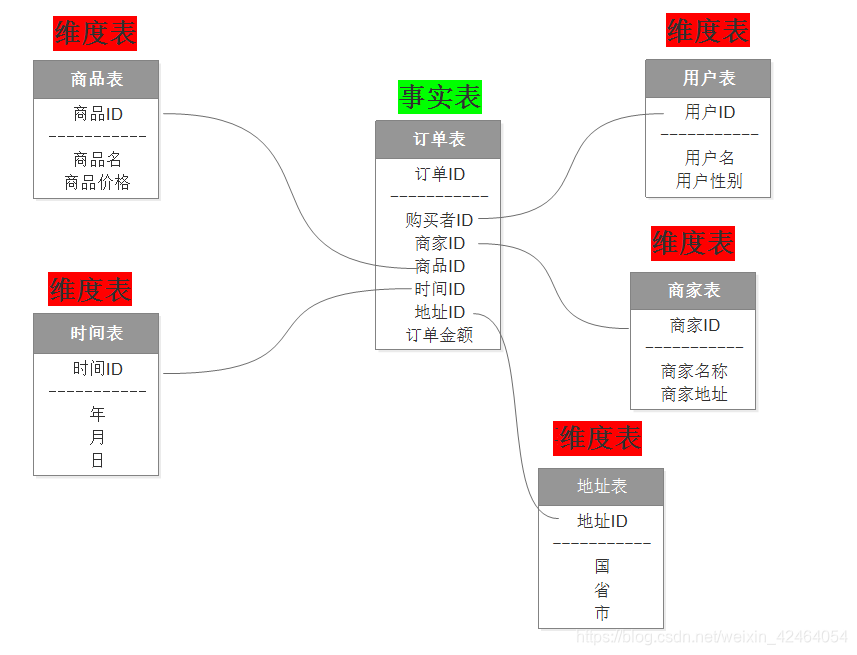
二、雪花模型
雪花模型是对星型模型的扩展,雪花模型是对星型模型的扩展,一个事实表为中心,周围连接着多个"层级"区域的维度表。雪花模型通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能,避免了数据冗余。
然而,它增加了主键-外键关联的几率,导致查询效率低于星型模型,并且不利于开发。
★优点: 提高了数据的规范性和统一性,缓解了数据冗余和不一致问题,可以更准确地表示数据结构。
★缺点: 它的复杂度较高,可能会影响性能,也需要更多的存储空间。
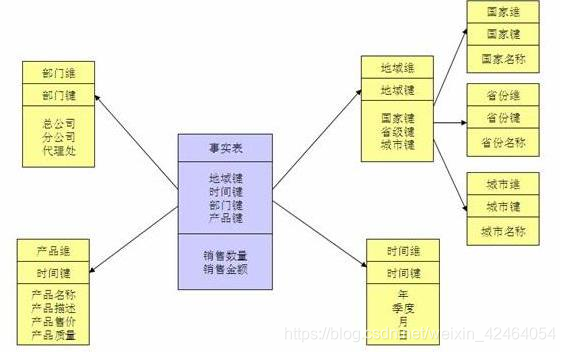
三、星座模型
星座模型是一种维度建模技术,它结合了星型模式和雪花模式的优点。每个事实表只有一个中心,但维度分为 事实维度 和 外部维度 。
事实维度:被拆分成更小的表,分别包含不同的度量指标和属性。
外部维度:则通过复杂的关系连接到事实表上,是由多个星型或雪花模型组成的复杂模型,它适用于多个主题或业务领域的数据建模。
重点说明: 在业务发展后期 , 数据中台与业务中台提供数据服务时,需要建设数据微服务化模型,都采用的是星座模式。
★优点: 高适应性、灵活性和可扩展性。它可以更好地支持复杂分析、查询和报告需求,并通过聚集、索引等优化技术提高查询性能。
★缺点: 它的建模难度较大,容易出现错误。
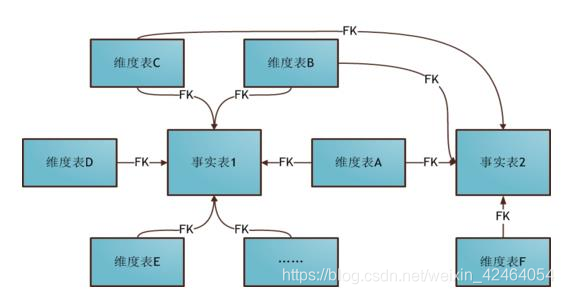
总之,这些模型的选择取决于具体的业务需求和数据特点。
星型模型通常更易于理解和查询,数据关系简单, 对查询性能要求较高,
雪花模型在某些情况下可以提供更好的数据规范化, 数据关系复杂,且需要避免数据冗余
星座模型则适用于复杂的多主题数据环境, 需要处理多个事实表并共享维表信息














 3791
3791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









