







Torch中optim的sgd(Stochastic gradient descent)方法的实现细节
Overview
sgd的全称是Stochastic gradient descent,关于Stochastic gradient descent我们不在本文详述。
Stochastic gradient descent
https://en.wikipedia.org/wiki/Stochastic_gradient_descent#cite_note-1
关于本文解释的代码传送门
https://github.com/torch/optim/blob/master/sgd.lua#L63
参数解释
输入参数
首先sgd的参数有三个,1)opfunc;2)x;3)config;4)state
1)opfunc&x:第一个参数opfunc是一个求cost function以及cost function针对于权重的导数的函数,而这个函数的参数就是sgd的第二个参数x了。
举个例子,对于一个sample x=[1 x1 x2 x3 … xn]T,我们有一组初始的权重w=[w0 w1 w2 … wn]T,那么我们可以定义cost function为:
cost(x)=||xT*w-y||2=||w0+w1*x1+w2*x2+…+wn*xn-y||2
dcost(x)/dw
opfunc返回的就是cost(x)以及dcost(x)/dw,注意:而opfunc(x)中的参数x不是指样本,而是指权重 w。
2)config:第三个参数是一些配置变量,用来优化梯度下降用的,为了防止求得的最优解是局部最优解而不是全局最优解。
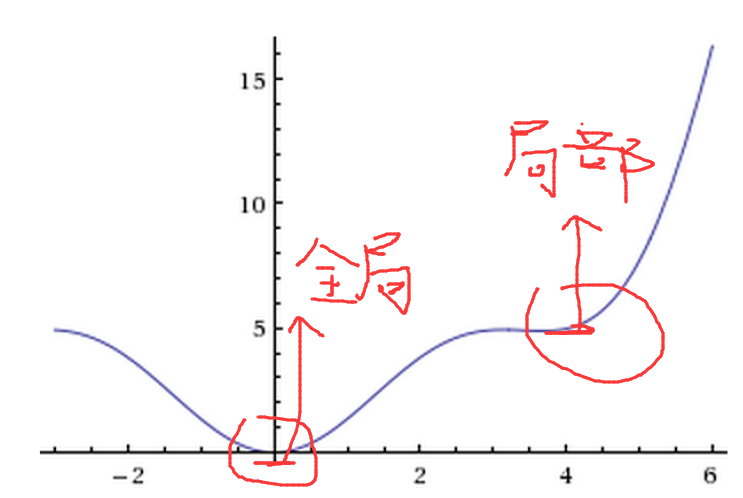
配置变量包括:learningRate(梯度下降速率),learningRateDecay(梯度下降速率的衰减),weightDecay(权重衰减),momentum(动量 or 冲量)等等
3)state:第四个变量state,个人认为最有用的就是state.evalCounter,因为它与学习速率有关,下文会有说明。
输出参数
new x和cost(x)新的权重以及旧的权重求得的cost function的值。
函数内部
1.省略开始的赋值操作,定位到代码:
local fx,dfdx = opfunc(x)
这里是求得cost(x) = fx,以及dcost(x)/dw=df/dx
2.如果weightDecay不等于0,就执行代码段
dfdx:add(wd, x) 这段代码是指:df/dx=df/dx+wd*x,为什么说这么做会衰减权重呢?
正常情况,权重:x=x-learningRate*df/dx
衰减情况,权重:x=x-learningRate*(df/dx+wd*x)
我们会发现x减少的更快,就达到了减少权重衰减的目的,这样收敛到最优解的速度会加快。
3.如果存在冲量momentum
state.dfdx:mul(mom):add(1-damp, dfdx)
dfdx = state.dfdx 这里我把代码展开成公式:
df/dx=mom*df/dx+(1-damp)*df/dx
大部分情况damp=0,所以公式简化为:
df/dx=mom*df/dx+df/dx
x=x-learningRate*(mon*df/dx+df/dx)=x-(learningRate*df/dx+learningRate*mon*df/dx)
我们比较一下wiki中的公式,基本一致:
动量的意义在于帮助梯度下降方法找到全局最优解。
4. 如果learningRateDecay速率衰减存在
local clr = lr / (1 + nevals*lrd) 这里nevals=state.evalCounter,而state.evalCounter是不断变大的,所以速率在不断的变小。
5.更新权重x
x:add(-clr, dfdx)
x=x+(-clr)*df/dx综上就是torch的optim的sgd的实现细节。















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









