







为什么要使用ConcurrentHashMap
线程不安全的HashMap
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。例如,执行以下代码会引起死循环。
final HashMap<String, String> map = new HashMap<String, String>(2);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}, "ftf" + i).start();
}
}
}, "ftf");
t.start();
t.join();HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。(Java HashMap的死循环)
- 效率低下的HashTable
- ConcurrentHashMap的锁分段技术可有效提升并发访问率
ConcurrentHashMap的结构
通过ConcurrentHashMap的类图来分析ConcurrentHashMap的结构,如图所示
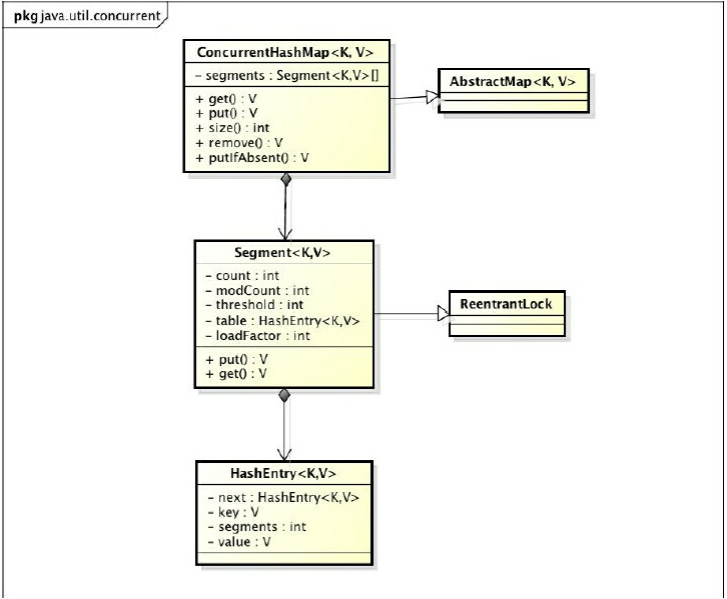
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁,如图所示

ConcurrentHashMap的操作
get操作
Segment的get操作实现非常简单和高效。先经过一次再散列,然后使用这个散列值通过散列运算定位到Segment,再通过散列算法定位到元素,代码如下:
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空才会加锁重读。我们知道HashTable容器的get方法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢?原因是它的get方法里将要使用的共享变量都定义成volatile类型,如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value。定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。
put操作
由于put方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须加锁。put方法首先定位到Segment,然后在Segment里进行插入操作。插入操作需要经历两个步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位置,然后将其放在HashEntry数组里。
size操作
如果要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是可能累加前使用的count发生了变化,那么统计结果就不准了。所以,最安全的做法是在统计size的时候把所有Segment的put、remove和clean方法全部锁住,但是这种做法显然非常低效。
因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put、remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。
弱一致性
- ConcurrentHashMap#get
- ConcurrentHashMap#clear
- ConcurrentHashMap中的迭代器
ConcurrentHashMap是弱一致性分析
copy-on-wirte
CopyOnWrite 的核心思想是利用读写分离,因为高并发往往是读多写少。进行读操作的时候,不加锁以保证性能;对写操作则要加锁,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性。
CopyOnWrite代码及使用场景















 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









