




 探讨HashMap在多线程环境下的并发问题,特别是在JDK1.7中因扩容引发的死循环现象及解决方案。
探讨HashMap在多线程环境下的并发问题,特别是在JDK1.7中因扩容引发的死循环现象及解决方案。
在多线程环境中,使用HashMap进行put操作时会引起死循环,因为在HashMap本来就不支持多线程使用,要并发就用ConcurrentHashMap。 HashMap扩容时会导致死循环是在JDK1.7中,由于扩容时的操作是使用头插法,在多线程的环境下可能产生循环链表,由此导致了死循环。在JDK1.8中改为使用尾插法,避免了该死循环的情况,暂无此问题。
源码分析:
在创建了新的数组之后调用transfer方法来完成元素的迁移操作,具体迁移逻辑如下:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next; //假设线程一在此处被挂起,线程二开始执行
//线程二完成扩容后,链表的顺序被反转了
//此时线程一在继续执行
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity); //线程1等线程2执行结束后
//从此处开始执行
//此时e的key=(3),e.next.key=(7)
//但是此时的e.next.next的key=3了
//(被线程2修改了)
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}假设HashMap初始化大小为4,插入个3节点,恰巧这3个节点都hash到同一个位置
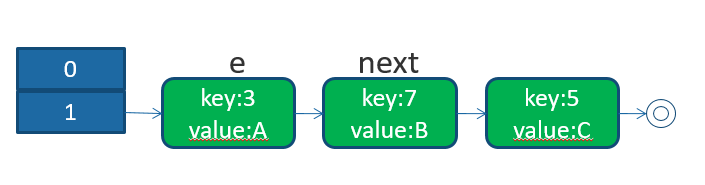
并发下的ReHash
在多线程环境下有线程一和线程二,同时对该map进行扩容执行扩容。
transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // 假设线程一执行到这里就被调度挂起了
// 此时e=key(3),next=key(7)
int i = indexFor(e.hash,newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while(e != null);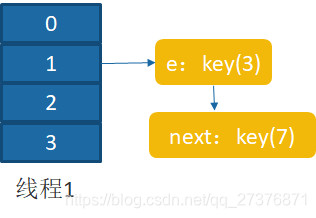
线程二继续执行并完成扩容后,(注意:这里的执行完成是指do...while循环执行 完毕,且HashMap中成员变量table已更新为线程二持有的newTable。注意!!!线程一和线程二进去transfer()后,newTable实际上是两个)
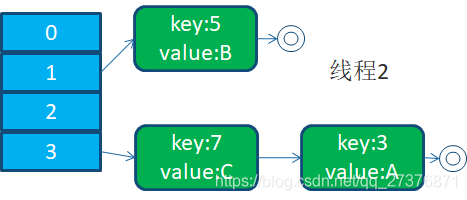
当线程一被调度回来执行之后,因为线程一执行的e.next =newTable[i];将key(3)插入到3号位置,同时3.next=key(7)。此时e=key(3),next=key(7);
线程一此时操作的HashMap已经是线程二扩容后的table了,此时的链表的顺序被反转了。因为在线程一挂起时e指向了key(3),而next指向了key(7),下一轮while时e指向了扩容完成后的key(7),而next指向了key(3),此时实际的链表结构是:

线程二扩容前原始链表(原始链表):key(3).next=key(7);key(7).next=key(5);key(5).next=null;
线程二扩容后链表:key(7).next=key(3);key(3).next=null;
线程一扩容继续扩容时的原始链表(在第二轮遍历时的链表 == 线程二扩容后链表):key(7).next=key(3);key(3).next=null;
线程一扩容后链表:key(3).next=key(7);key(7).next=key(3);key(7).next=key(3);(红色是根据原始链表产生,绿色是根据线程二扩容后链表产生)
总结
HashMap之所以在并发下的扩容造成死循环,是因为,多个线程并发进行时,因为一个线程先期完成了扩容,将原Map的链表重新散列到自己的表中,并且链表变成了倒序,后一个线程再扩容时,又进行自己的散列,再次将倒序链表变为正序链表。于是形成了一个环形链表,当get表中不存在的元素时,造成死循环。
链表头插法:插入顺序和遍历顺序相反,先进后出,后进的节点需要知道前一个节点的指针地址
链表尾插法:插入顺序和遍历顺序相同,先进先出,前一个节点需要知道后进的节点的指针地址
原因:
JDK1.8之前的头插法扩容前和扩容后的链变中节点顺序的会变化(头节点变尾节点,尾节点变头节点,循环往复)
JDK1.8之后的尾插法扩容前和扩容后的链表中节点顺序不变(以前是头节点就一直是头节点)
数据丢失(JDK1.8直接在resize()函数中完成了数据迁移)
- 假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。这里要注意的一个点就是,这个的覆盖不安全是由于是不同key所引起的,不是正常的HashMap自带的由于相同的key引起的覆盖,因此这里是不安全的。
- 除此之前,还有就是代码的第38行处有个++size,我们这样想,还是线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10,当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
文章参考:
https://zhuanlan.zhihu.com/p/67915754

















 4309
4309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









