






2024-04-18,由国防科技大学大数据与决策实验室联合东南大学和清华大学共同创建了CMNEE数据集,这个数据集为军事领域的事件抽取研究提供了宝贵的资源,解决了该领域数据稀缺的问题,对情报分析和决策辅助等应用具有重要意义。
数据集地址:CMNEE(Chinese Military News Event Extraction dataset)|军事新闻分析数据集
一、研究背景:
事件抽取是从非结构化文本中提取结构化信息的过程,它通常被分为两个子任务:事件检测和事件论元抽取。尽管当前研究主要集中在一般新闻或金融领域,军事领域的事件抽取同样不可忽视,因为军事文档中包含了丰富的事件信息,对这些信息的抽取对于情报分析、决策辅助和战略规划等下游应用至关重要。
目前遇到困难和挑战:
1、军事领域数据稀缺,阻碍了事件抽取模型的研究发展。
2、现有事件抽取数据集多针对一般或金融领域,军事领域专用数据集严重缺乏。
3、军事文本的复杂性和敏感性导致事件抽取任务面临独特挑战,需要专门的数据集和模型来应对。
数据集地址:CMNEE|自然语言处理数据集|军事新闻分析数据集
二、让我们来一起看一下CMNEE数据集
CMNEE是一个大规模的文档级开源中文军事新闻事件抽取数据集,包含17000份文档和29223个事件,覆盖8种事件类型和11种论元角色类型。
CMNEE数据集基于开源的中文军事新闻构建,旨在推动军事领域事件抽取技术的发展。数据集中的事件类型包括实验、机动、部署、支援、事故、展示、冲突和伤害等,论元角色类型则包括主体、对象、时间等。
数据集构建 :
数据集的构建过程包括数据收集、预处理、事件模式构建、预标注、人工标注和质量评估等步骤。通过两阶段多轮次的人工标注策略,确保了数据集的质量。
数据集特点 :
1、大规模:包含17000份文档,是军事领域最大的文档级事件抽取数据集。
2、多事件:文档中平均含有1.8个事件,近一半的文档包含两个或更多事件。
3、重叠事件:42%的实例包含重叠事件,增加了事件抽取的复杂性。
4、长论元:军事文本中涉及的专有名词较多,长论元的比例较高。
研究人员可以使用CMNEE数据集来训练和评估事件抽取模型,包括事件检测和事件论元抽取。数据集提供了预定义的事件类型和论元角色类型,方便研究人员进行模型开发和测试。
基准测试 :
通过对比几种先进的基线模型在CMNEE上的表现,实验结果表明CMNEE具有独特的挑战性,需要进一步的研究努力。例如,BERT+CRF模型由于CRF在建模多事件相关性方面的优势,在CMNEE上表现较好。
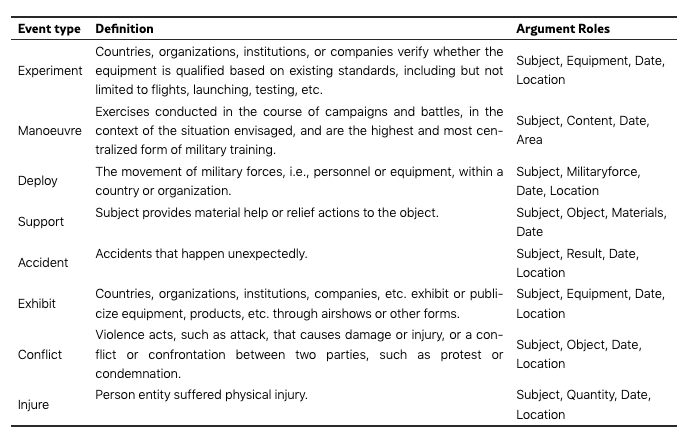
CMNEE 的事件架构
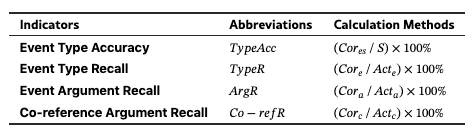
质量指标的定义
三、让我们一起展望CMNEE数据集的应用场景
比如,你是一名计算机科学家,正在为军队开发一种新的智能系统,这个系统能够帮助分析大量的军事新闻报道,自动找出里面的事件,比如某个国家进行了军事演习,或者两个国家之间发生了冲突。这些信息对于军队来说非常重要,因为它们需要快速了解全球的军事动态。
现在,你手头有CMNEE数据集,这个数据集就像是你的宝藏,里面包含了17000篇军事新闻报道,每篇报道都已经被人工仔细地标注了事件信息。比如,有一篇报道讲的是“2023年,某个国家在某个海域进行了军事演习”,在这篇报道里,人工标注者已经标出了“军事演习”这个事件,还标出了事件的类型、发生的时间、地点等详细信息。
你的任务就是利用这些标注好的数据来训练一个智能模型。你可以把这些数据输入到你的模型中,让模型学习如何从新闻报道的文本中找出事件,并且识别出事件的类型和相关参数。比如,模型需要学会从“2023年,某个国家在某个海域进行了军事演习”这句话中识别出“军事演习”这个事件,并且知道这个事件发生在2023年。
训练好模型后,你需要评估它的性能,看看它是不是真的能准确地从新的新闻报道中抽取出事件信息。这时候,CMNEE数据集又派上用场了,你可以用数据集中的另一部分没有用来训练模型的新闻报道来测试你的模型。如果模型能够准确地识别出这些测试报道中的事件和参数,那就说明模型训练得很成功。
通过CMNEE数据集,你的模型能够变得更加智能,更准确地理解和分析军事新闻中的事件,这对于军队来说是一个巨大的帮助。这就是CMNEE数据集在事件抽取模型开发与评估中的具体应用案例。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









