







概要
Druid是一个列式分布式数据存储,支持PB级扩展,次秒级查询,常用于基于时间序列的实时数据存储。
目标
Druid论文中指出,Druid是为了解决Olap应用中,大数据的任意维度的次秒级聚合查询而诞生的,而开源的的RDBMS和NoSQL并不能做到。
优势
Druid有如下优势
-
列式存储
Druid使用列式存储,列式存储可以查询指定的列,提升查询效率,同时可以根据每一列数据的类型做存储的优化。 -
弹性分布式系统
Druid是分布式系统,内部由五部分组成,便于扩容。 -
并行执行
被查询的数据会在MiddleManager Nodes和Historical Nodes同时进行聚合操作计算,再在Broker Nodes汇总。 -
实时性
ingested data可以立即被查询到。 -
24/7服务
Druid集群能够自我平衡,即使部分节点异常,依然能正常运转。 -
容错、数据安全
数据存在Deep storage,保证数据安全,以及用于数据恢复。 -
快速过滤
Druid使用Concise: Compressed ’n’ ComposableInteger Set或者Roaring Bitmaps创建索引,实现快速过滤。 -
近似算法
Druid提供近似算法,用于distinct、ranking等计算,适用于速度比准确性更重要的情景,例如著名的UV近似算法HyperLogLog。 -
提前聚合
MiddleManager Nodes会提前对数据进行聚合操作,提升效率。
架构
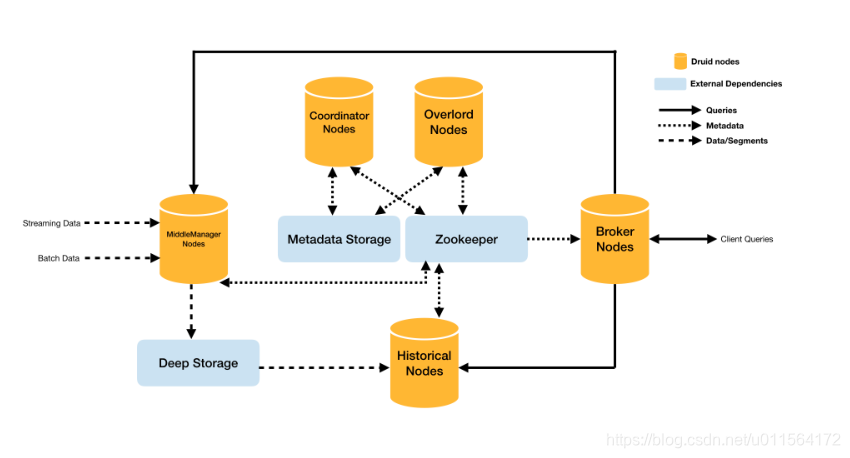
组件
从架构中可以看到,Druid由如下五部分构成,并且各部分功能如下
- MiddleManager Nodes
- Historical Nodes
- 加载Segment到本地,为Broker Nodes提供查询服务。
- Broker Nodes
- 为客户端提供数据查询服务,Broker能够同时查询MiddleManager Nodes和Historical Nodes中的Segments,并进行聚合操作。
- Coordinator Nodes
- 管理集群中的segments,通知Historical Nodes加载新segments,删除过期Segment,以及负载均衡Segment。
- Overlord Nodes
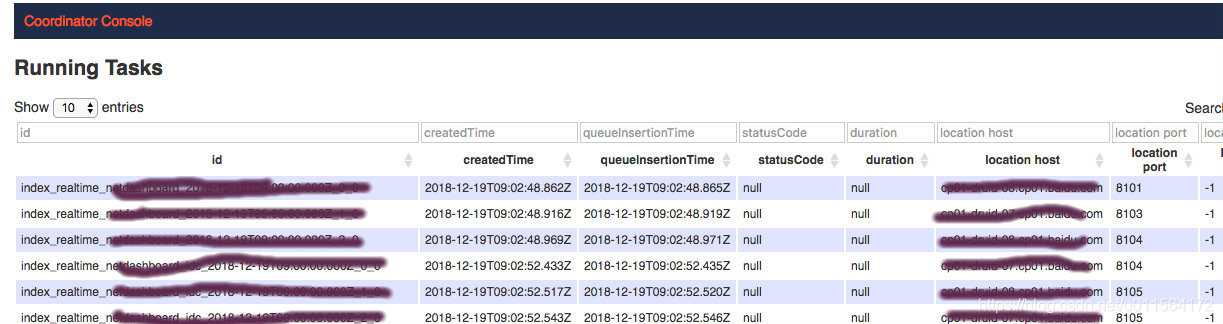
- 负责task的管理,包括接收提交的task、分发task给MiddleManager Nodes,kill task,提供task状态查询等,如下图所示
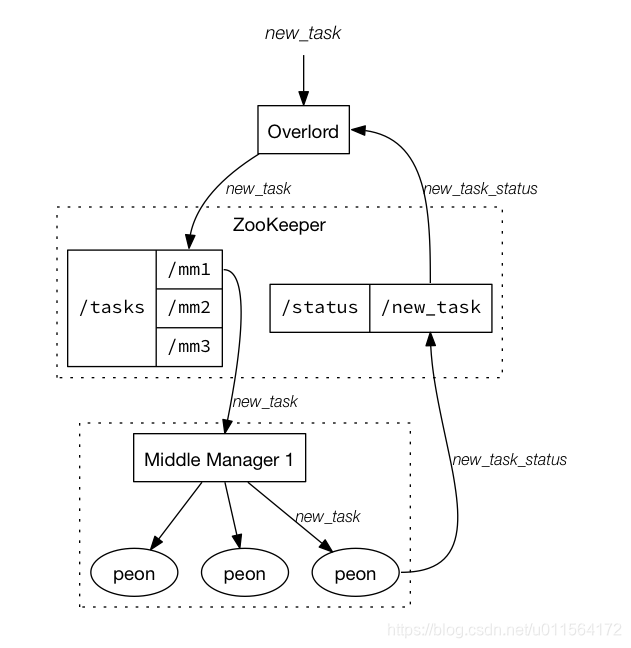
- 负责task的管理,包括接收提交的task、分发task给MiddleManager Nodes,kill task,提供task状态查询等,如下图所示
外部依赖
从架构图中可以看到,Druid还有三个外部依赖环境,如下
- Deep Storage
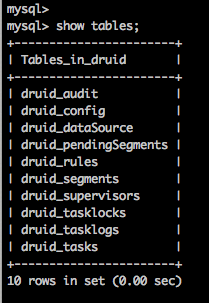
永久存储Segment,为Historical Nodes提供下载,通常是HDFS和S3。 - Metadata Storage
推荐使用MySQL,用于存储Segment的元数据和配置、task等信息,如下图
- Zookeeper
Druid集群各节点的状态信息等。
集群部署
生产环境的配置主要配置Deep Storage、Metadata Storage、Zookeeper和JVM信息。
集群信息
Overload和Coordinator能够查看集群和task等信息,如下图
- Overload
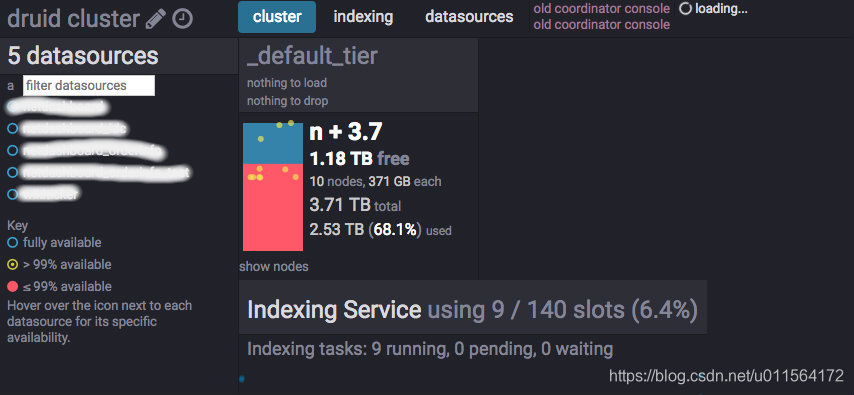
- Coordinator
数据可视化
我们使用Caravel对Druid数据进行可视化展示,其他方案可参考druid.io可视化调研。
遇到问题
Index Service task积压
- Coordinator节点异常
Coordinator Node负责segments的管理,Coordinator异常导致segments不能正常分配,导致task积压。 - Historical nodes磁盘空间满了
Historical nodes磁盘异常,不能正常接受MiddleManager Nodes的segments,导致积压。














 6163
6163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









