










目录
1.背景与问题
2.人工MOS评测的过程
3.评分等级与评分的转换
4.构建对话式指令数据集
5.Q-ALIGN模型结构
6.实验结果
7.源码分析
8.资料
一、背景和问题
多模态模型(LMMs)在视觉和语言方面展现出非常强大的能力,它们能够很好地理解高级视觉内容和感知低级视觉属性,但现有研究(Q-Bench)已经证明,它们在准确预测与人类偏好一致的分数方面仍然不足。
在本论文作者研究了它们重要的最后一英里:如何教导 LMMs 预测与人类一致的分数?
模拟人类对图片视频评测的过程,以评测等级而不是评分构建对话式指令数据集,基于阿里多模态模型mplug-owl2进行funetine,在画质评测上达到SOTA
二、人工MOS评测的过程
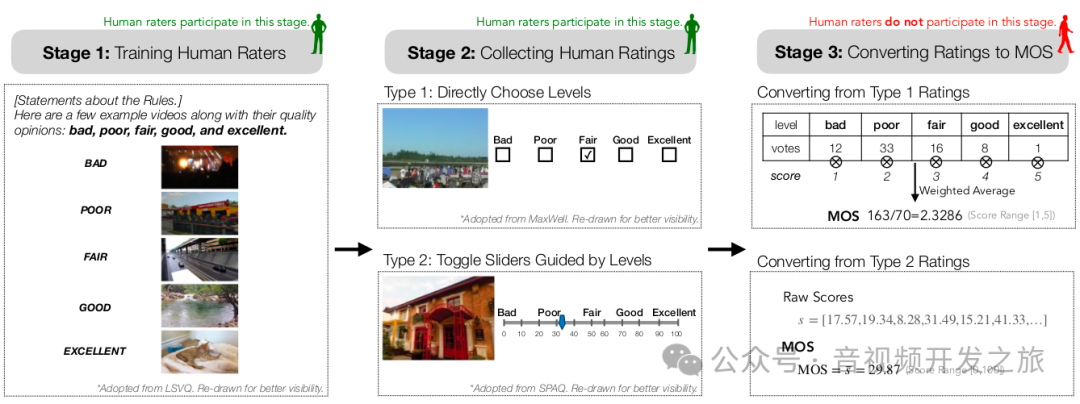
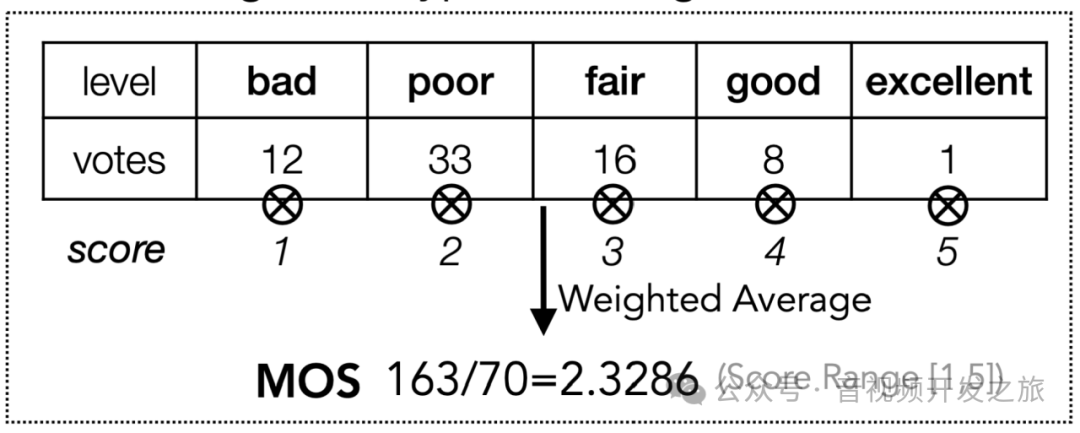
我们先来回顾下人类评测的过程,如下图所示
-
首先,组织者定义几个评分等级(例如 “优秀”、“良好”、“一般”、“差”、“很差”),并为每个等级选择参考示例图片,使评测人员有可参考的统一的标准
-
根据参考标准,评测人员通过选择按钮或等级引导滑块 而不是给出具体的分值(eg:3.1)作为评测结果,以最小化评测人员的认知负荷,并提高主观研究的结果
-
通过加权平均将初始评分转换为 MOS
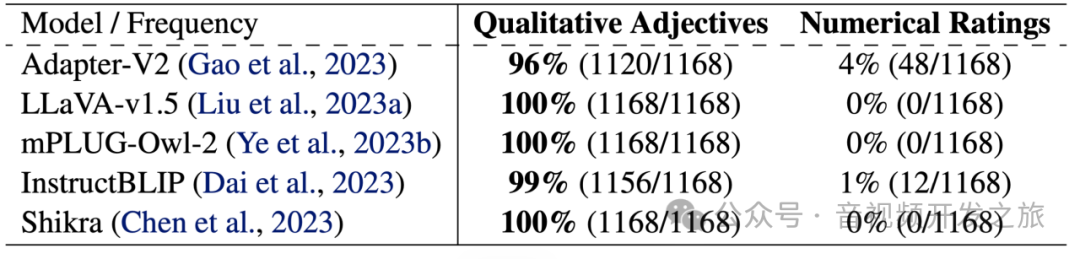
理论上LMMs 被设计为理解和生成类人的文本,应该与人类具有相似的行为模式。为了验证这一点,作者对五个 LMMs ,分别对1168张LIVE数据集中的图片,使用“对图像质量进行评分”这个指令,mLLM的响应倾向于定型的形容词,而不是分数。
因此,如果将分数作为 LMMs 的学习目标,它们需要首先学习输出分数,然后学习如何准确评分。为了避免这种额外的格式成本,作者选择评分级别作为 Q-A LIGN 的目标。
三、评分等级与评分的转换
3.1 训练阶段:Mos评分转为评分等级
现有数据集的Mos值都是一个分值,直接采用等距转换为对应的评测等级:将最高分(M)和最低分(m)之间的范围均匀地划分为五个不同的区间,并将每个区间内的分数转换为相应的级别
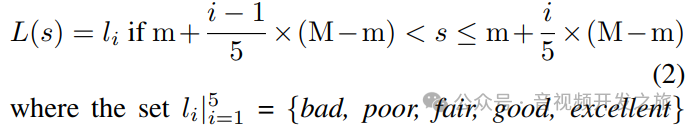
由于上述转换是多对一的映射,不可避免的会损失真实精度,考虑到Mos值本身有一定随机性,作者认为转换后的评分等级作为训练标签足够准确

3.2 推理阶段:评分级别→分数
模拟对人类评分的后处理,例如,“一般” 被转换为分数 3,“差” 被转换为 1,MOS 值通过转换后的分数及每个级别的频率fli的加权平均值计算得出的
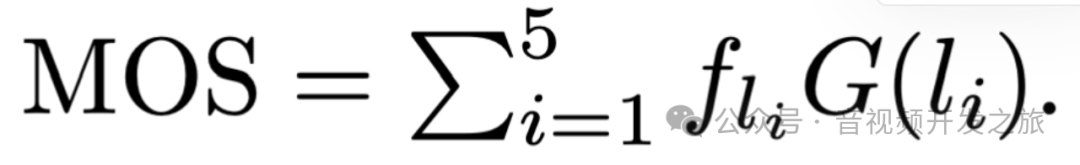
对于 LMMs,用对每个评分级别的预测概率来替代fli,然后进行softmax归一化处理
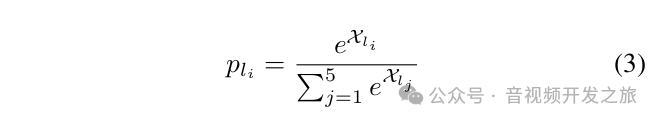
最终预测的得分计算公式如为:
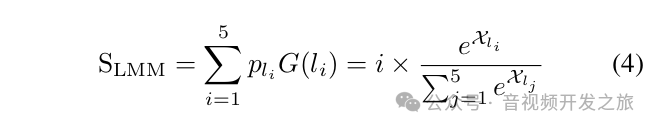
四、构建对话式指令数据集
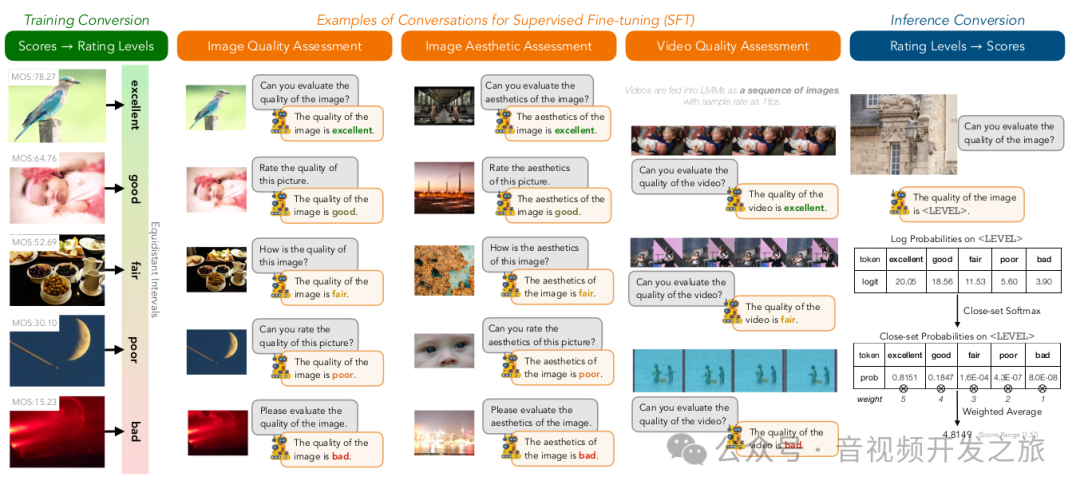
构建对话格式指令数据集
Image Quality Assessment (IQA)#User: Can you evaluate the quality of the image?#Assistant: The quality of the image is.Image Aesthetic Assessment (IAA)#User: How is the aesthetics of the image?#Assistant: The aesthetics of the image is.Video Quality Assessment (VQA)#User: Rate the quality of the video.#Assistant: The quality of the video is.
五、模型结构与微调
Q-A LIGN 基于多模态模型mPLUG-Owl-2(具有出色的视觉感知能力以及良好的语言理解能力),模型结构中除了将图像转换为嵌入的视觉编码器之外,还引入了一个额外的视觉抽象器,可以进一步的显著的减少了每张图像的token数量(1024 → 64)。
LLM使用的是 LLaMA2-7B,它拥有 2048 个上下文长度,在有监督微调(SFT)期间可以同时输入多达 30 张图像(没有抽象器则为 2 张),使能够将视频作为图像序列输入到 LMM 中,并在一个结构下统一图像(IQA,IAA)和视频(VQA)评分任务。
Q-ALIGN 使用常见的 GPT损失,即标签和输出对数几率之间的交叉熵。
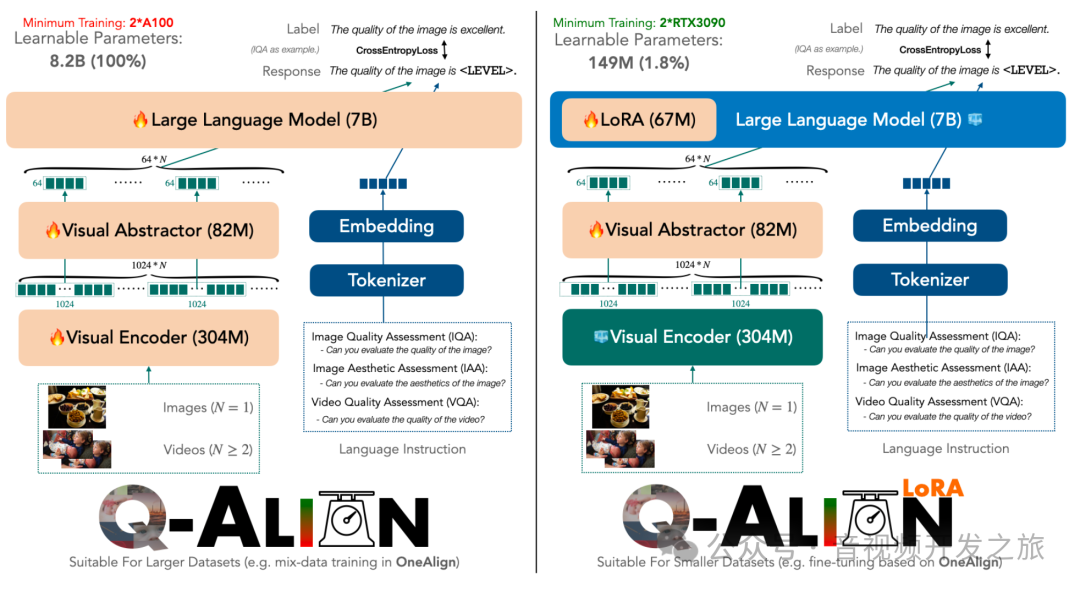
https://github.com/Q-Future/Q-Align/tree/main/lora_finetune
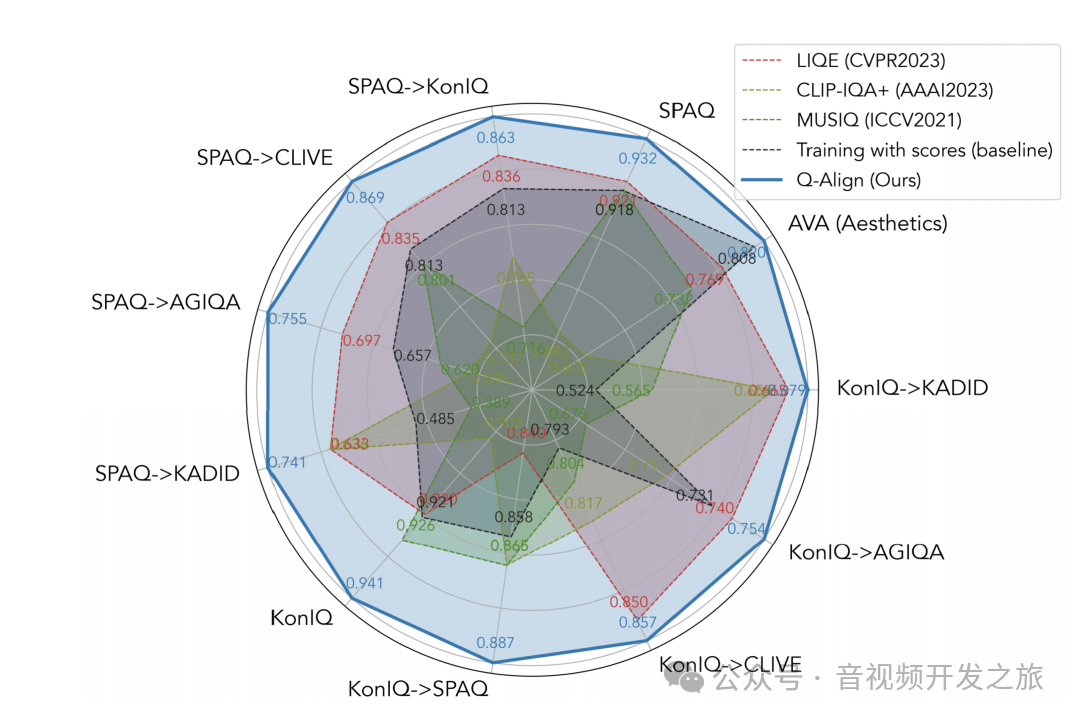
六、实验结果
对 mPLUG-Owl2的预训练权重进行微调,对于所有 IQA/VQA 数据集,将批处理大小设置为 64,而当 AVA 数据集参与训练时,批处理大小为 128。学习率设置为 2e−5,并且对所有数据集都训练 2 个周期,除了少样本设置,在少样本设置中我们训练 4 个周期以使模型完全收敛。
在未见过的(OOD)数据集上的改进尤其显著。Q-A LIGN 还有两个令人兴奋的特点:
1)数据效率。它在仅使用 1/5(IQA)甚至 1/10(IAA)的数据时SOTA效果,这在视觉评分任务中数据收集相当昂贵的情况下可能特别有用。
2)数据集的自由组合。凭借 LMMs 的强大能力,它可以自由地组合不同的数据集进行训练,甚至来自不同的任务(即 IQA 和 VQA),并获得性能提升
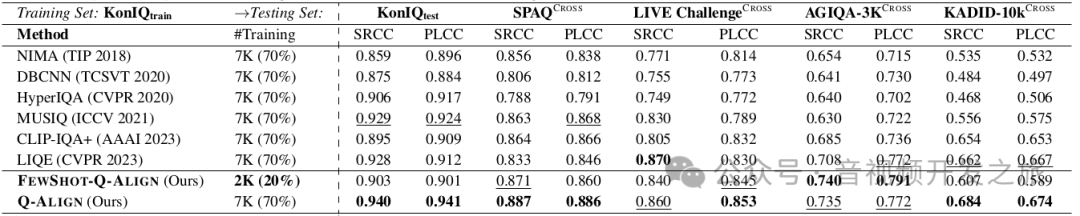
更细粒度的评估
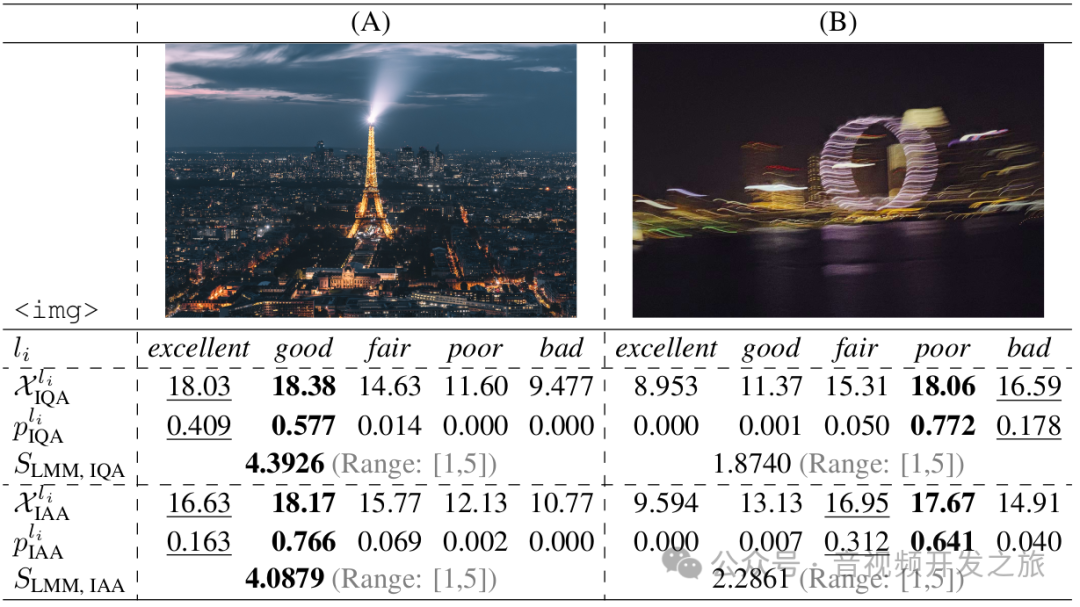
它的第2高等级(下划线)可以提供更细粒度的评估,我们发现它从不对不相邻的评级(例如好和差)预测为第一和第二高等级,这表明 LMMs 本质上理解这些文本定义的评级。
七、源码分析
class QAlignScorer(nn.Module):def __init__(self, pretrained=f"{root}/q-future/one-align", device="cuda:0"):super().__init__()"""#tokenizer: LlamaTokenizer tokenizer标识器,包含input_ids(文本首先被tokenizer标识器转为token,映射为一个唯一的id)和attention_mask(对于模型按写token是有用的) eg:tokenizer('USER: How would you rate the quality of this image?\n')输出{'input_ids': [1, 3148, 1001, 29901, 1128, 723, 366, 6554, 278, 11029, 310, 445, 1967, 29973, 13], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}#mode:MPLUGOwl2LlamaForCausalLM#image_processor:CLIPImageProcessor (crop_size:{'height': 448, 'width': 448} ;feature_extractor_type:'CLIPFeatureExtractor')"""print(f"pretrainedPath:{pretrained}")tokenizer, model, image_processor, _ = load_pretrained_model(pretrained, None, "mplug_owl2", device=device)prompt = "USER: How would you rate the quality of this image?\n<|image|>\nASSISTANT: The quality of the image is" #图像画质的promptself.preferential_ids_ = [id_[1] for id_ in tokenizer(["excellent","good","fair","poor","bad"])["input_ids"]] #[15129, 1781, 6534, 6460, 4319]self.weight_tensor = torch.Tensor([1,0.75,0.5,0.25,0.]).half().to(model.device)self.tokenizer = tokenizerself.model = modelself.image_processor = image_processor#prompt + iamge的tokenizertensor([[ 1, 3148, 1001, 29901, 1128, 723, 366, 6554, 278, 11029,310, 445, 1967, 29973, 13, -200, 29871, 13, 22933, 9047,13566, 29901, 450, 11029, 310, 278, 1967, 338]],device='cuda:0')self.input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).to(model.device)def expand2square(self, pil_img, background_color): #扩展为正方形(模型需要),上下或者左右添加background_colorwidth, height = pil_img.sizeif pil_img.mode == 'L':pil_img = pil_img.convert('RGB')if width == height:return pil_imgelif width > height:result = Image.new(pil_img.mode, (width, width), background_color)result.paste(pil_img, (0, (width - height) // 2))return resultelse:result = Image.new(pil_img.mode, (height, height), background_color)result.paste(pil_img, ((height - width) // 2, 0))return resultdef forward(self, image: List[Image.Image]):image = [self.expand2square(img, tuple(int(x*255) for x in self.image_processor.image_mean)) for img in image]with torch.inference_mode():#image_tensor 处理图像,提取特征 图像首先被填充为到正方形,输出的image_tensor的shpae为([1,3,448,448]),具体是怎么实现或者处理的要继续分析下image_tensor = self.image_processor.preprocess(image, return_tensors="pt")["pixel_values"].half().to(self.model.device)#输出的逻辑值 model为MPLUGOwl2LlamaForCausalLM,内部会调用LlamaDecoderLayer(来自llama2), model推理输出为CausalLMOutputWithPast;model()['logits']输出的shape为([1,92,32000]);[:,-1, self.preferential_ids_]表示选最后一个时间步的输出(表示汇总的信息),self.preferential_ids_为[15129, 1781, 6534, 6460, 4319]表示["excellent","good","fair","poor","bad"]的tokenid, 从最后一个时间步中选择特定的tokenid,最终输出为:tensor([[17.3750, 18.4844, 15.3750, 12.5391, 10.1172]], device='cuda:0',dtype=torch.float16)output_logits = self.model(self.input_ids.repeat(image_tensor.shape[0], 1),images=image_tensor)["logits"][:,-1, self.preferential_ids_]#softmax 其中output_logits为 tensor([[17.3750, 18.4844, 15.3750, 12.5391, 10.1172]], device='cuda:0',dtype=torch.float16);self.weight_tensor为tensor([1.0000, 0.7500, 0.5000, 0.2500, 0.0000], device='cuda:0',dtype=torch.float16)#output_logits是一个未经softmax处理的原始张量,它的形状为(1,5)表示一个样本,每个样本5个等级评分各自的原始分数#softmax(x,-1), -1表示softmax沿着最后一个维度(这个例子中就是5个等级评分)进行.softmax将这些原始分数转为概率分布,使其分布在0-1,且总和为1#self.weight_tensor是一个权重张量# @ 对张量进行矩阵乘法,由于softmax输出是(1,5),权重张量为(5,),矩阵相乘后结果为(1,)即包含单个数值的向量result = torch.softmax(output_logits, -1) @ self.weight_tensor# print(f"QAlignScorer-forward-->torch.softmax(output_logits, -1):{torch.softmax(output_logits, -1)},result:{result}")return result
八、资料
1、论文q-align:https://q-future.github.io/Q-Align/fig/Q_Align_v0_1_preview.pdf
2、论文:AIS 2024 Challenge on Video Quality Assessment of User-Generated Content:Methods and Results 2404.16205 (arxiv.org)
3、论文mplug-owl2:https://openaccess.thecvf.com/content/CVPR2024/papers/Ye_mPLUG-Owl2_Revolutionizing_Multi-modal_Large_Language_Model_with_Modality_Collaboration_CVPR_2024_paper.pdf
4、源码:https://github.com/Q-Future/Q-Align
5、mplug-owl:https://github.com/X-PLUG/mPLUG-Owl
6、图像质量评价与大模型——Q系列(3)Q-ALIGN https://blog.csdn.net/shyinnn/article/details/141968572
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









