









目录
1. 背景和问题
2. Swin Transformer模型结构
3.Patch Merging
4. Window Attention
5. Shifted Window Attention
6. 实验效果
7. 源码分析
8. 资料
一. 背景和问题
上一篇我们学习了Vision Transformer的原理,把图像分割为固定大小的patch,通过线性变换得到PatchEmbedding,然后将图像的patch embeddings送入transformer的Encoder进行特征提取。通过实验也验证了在大数据集上的效果要优于CNN。但是存在如下几个问题:
1、VIT中预训练的默认图像分辨率为224*224,对于大分辨率,随着分辨率的增加,VIT的自注意力机制计算复杂度呈平分级增加。
2、VIT采用固定大小的patch,难以捕捉不同尺寸的图像特征。
3、VIT处理不同分辨率的图像要单独预训练或者进行插值处理,因为PostionEmbedding和切割的patch个数有关,每个patch分辨率固定,随着分辨率的增加,patch也会相应增加。
4、VIT主要关注全局信息,可能忽略了局部细节。
可以借鉴CNN的层次化结构,采用特征金字塔融合不同分辨率的特征,实现关注全局和局部.但是计算复杂度的问题该如何解决呐?这就是SwinTransformer要解决的问题.
二. Swin Transformer模型结构
Swin Transformer基于VIT的思想,创新性的引入了WindowAttention,让self-attention的计算限制在窗口内,使得计算复杂度从 O(n²) 降低到 O(n),ShiftedWindowAttention滑动窗口机制让模型能够学习到不同窗口的信息。同时也借鉴了传统CNN的层次化结构,对图像进行下采样,是的模型能够关注全局和局部信息。Swin Transformer已成为CV领域通用的backbone
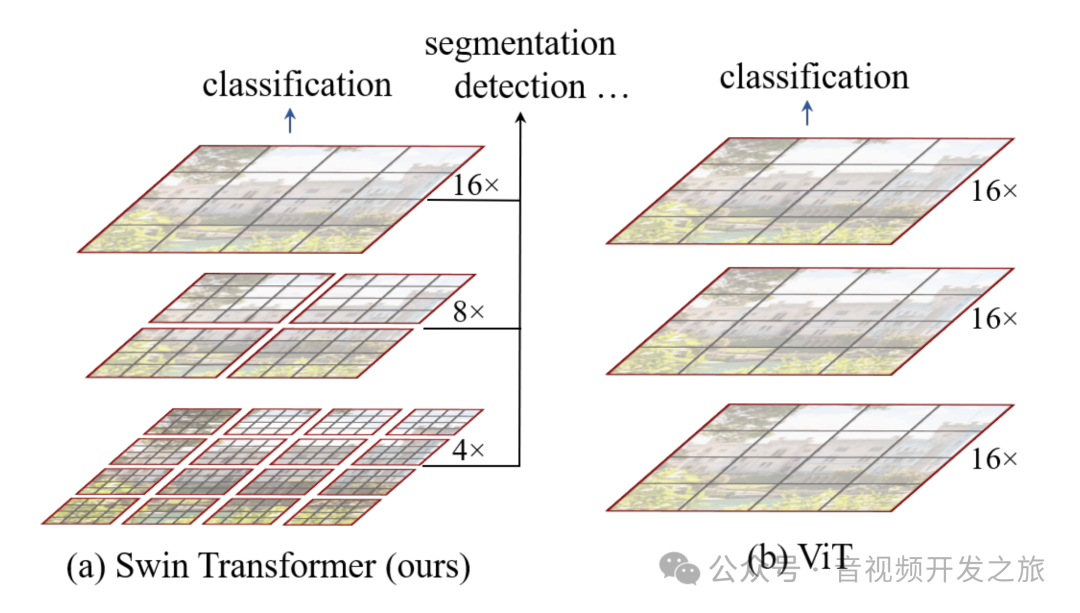
Swin Transformer相比VIT,采用局部窗口的自注意力计算以及层次化特征图结构,在处理大图像上更加高效。
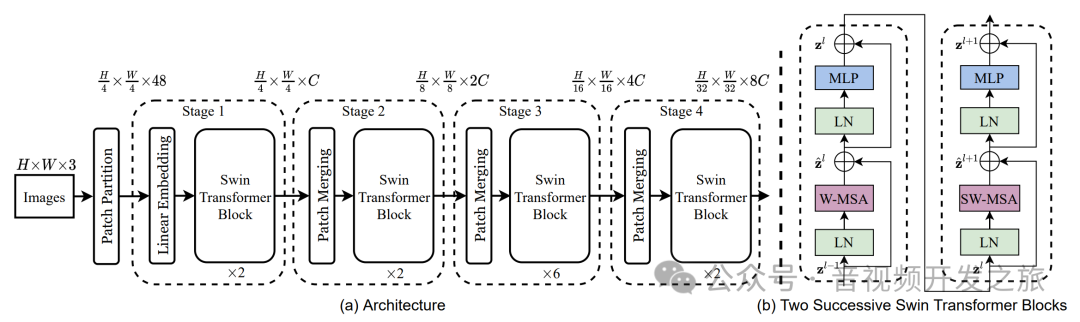
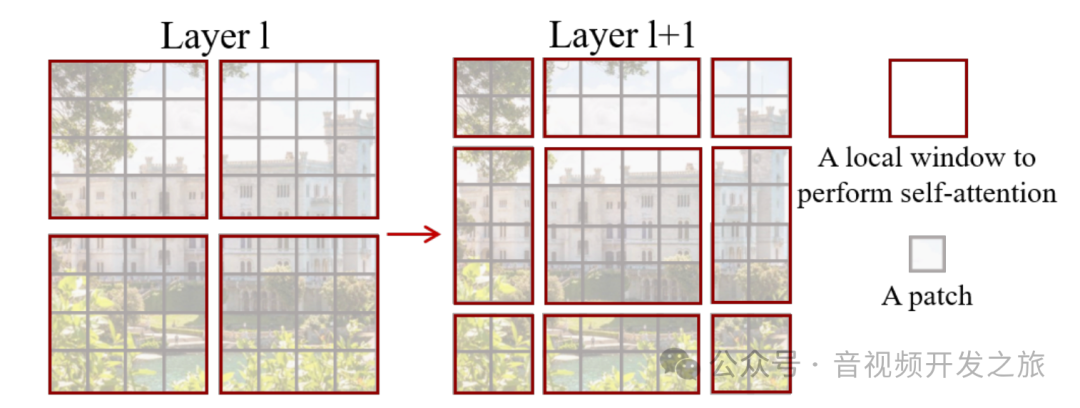
模型采取层次化的特征图和局部窗口注意力机制设计,共包含4个Stage,Stage由Patch Merging和Swin Transformer Block组成,Patch Merging模块会缩小输入特征图的分辨率,增加通道数,像CNN一样逐层扩大感受野,
SwinTransformerBlock是模型的核心,每个SwinTransformerBlock由W-MSA(非移动局部窗口注意力机制)和SW-MSA(移动窗口注意力机制)组成.W-MSA通过局部窗口注意力机制降低了计算的复杂度, SW-MSA通过滑动窗口自注意力机制增加了窗口之间的信息交互.
这种架构设计能够适应不同类型的视觉任务,eg:图像分类 目标检测和语义分割等.
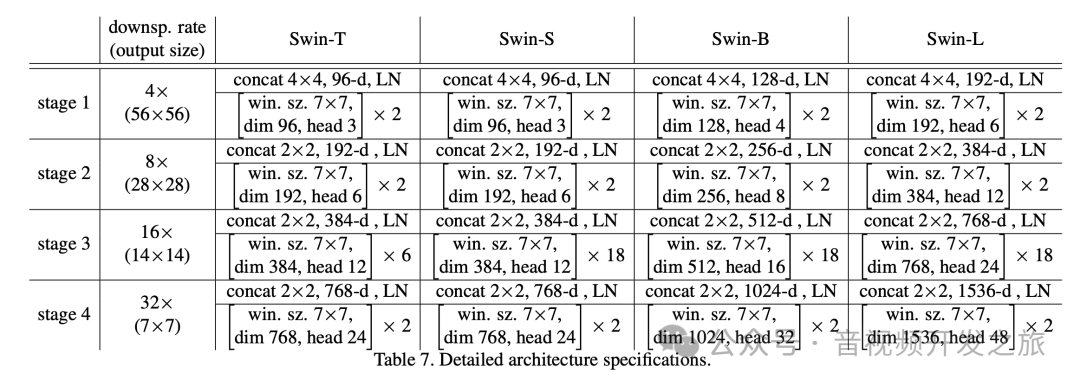
论文中给出了四种不同深度的参数配置,如下表所示.eg:Swin-T 4个stage中分别堆叠(2,2,6,2)个PatchMerging和SwinTrasformerBlock.
三. Patch Merging
Patch Embedding和VIT的作用一样,对图像且分为n个patch,然后对每个patch进行特征提取,在代码实现上有些区别,VIT中采用线性变换,SwinTransformer采用CNN,具体见后面的代码解析.
Patch Merging
在每个Stage开始前做降采样,用于缩小分辨率,调整通道数 进而形成层次化的设计,同时也能节省一定运算量。

图片来自:图解Swin Transformer
Swin Transformer Block 这部分是整个设计的核心,包含了论文中的很多知识点,涉及到相对位置编码、mask、window self-attention、shifted window self-attention,下面我们重点学习.
四. Window Attention
VIT是基于全局来计算注意力的,随着分辨率的增加,计算复杂度平方级增加。而 Swin Transformer 则将注意力的计算限制在每个窗口内,进而减少了计算量, 这就是WindowAttention.
假设一张图像可以切割为hxw个patches,每个窗口包括MxM个pathes
原始的self-Attention计算复杂度为(hw)的平方;而Swin Transformer的Window self-attention,在每个窗口内计算self-attention,计算复杂度为M的平方*hw, Window self-attention将计算复杂度从平方关系降低到线性关系.
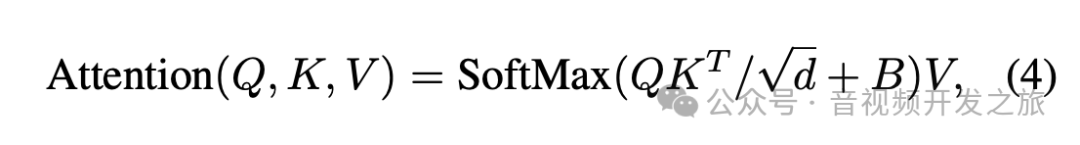
和传统的Attention相比,加入了相对位置偏置B (这里的相对位置偏置是如何计算的呐? 后面会有答案)
五. Shifted Window Attention
为了使不同window之间进行信息交互,Swin Transformer引入了shifted windowAttention
如下图所示,左边是不同窗口重叠交互的Window Attention,而右边是将窗口进行移位的Shift Window Attention。可以看到移位后的窗口包含了原本相邻窗口的元素,实现不同window之ian的信息交互,但这也引入了一个新问题,即window的个数翻倍了,由原本四个窗口变成了9个窗口。
为了避免Window增强, 作者巧妙的采用对特征图进行移位,分别在水平和垂直维度对内容进行roll翻滚(即上/左面的行/列 roll到最下/右面的行/列),把window降低到4个, 但在计算新的Window的局部注意力机制时,原本不同window的内容不应该参与到QKV的计算,为此作者又引入了Mask的方式,这个确实太叼了,代码实现也很巧妙. 通过relative_position_bias_table(相对位置偏移表)relative_position_index(相对位置索引)来计算
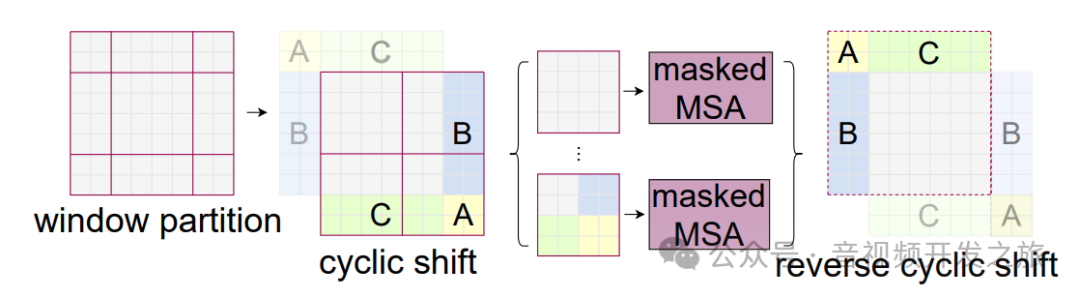
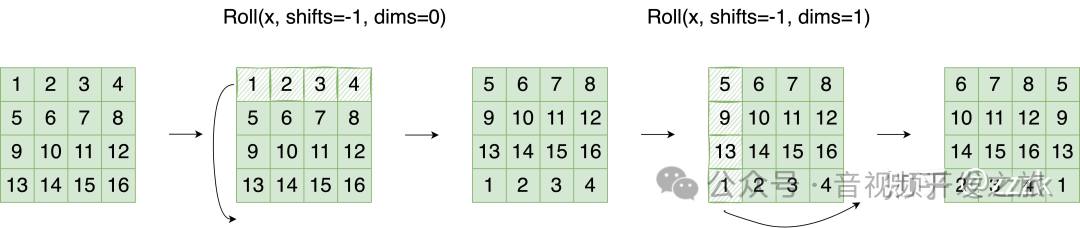
图片来自:图解Swin Transformer
整体计算公式如下

公式1: 计算l层的阶段输出z(l), 首先对前一层z(l-1)进行LayerNorm,然后应用W-MSA局部窗口注意力机制,最后再加上残差连接z(l-1),避免梯度消失
公式2:计算l层的输出z(l),首先对公式1的阶段输出z(l)进行LayerNorm,然后应用MLP多层感知机,最后再加上残差连接z(l)
公式3: 计算l+1层的阶段输出z(l+1),首先对公式2的输出z(l)进行LayerNorm,然后应用SW-MSA(移动窗口注意力机制),最后再加上残差连接
公式4: 计算l+1层的输出z(l+1),首先对公式3的输出进行LayerNorm,然后应用MLP,最后加上残差连接
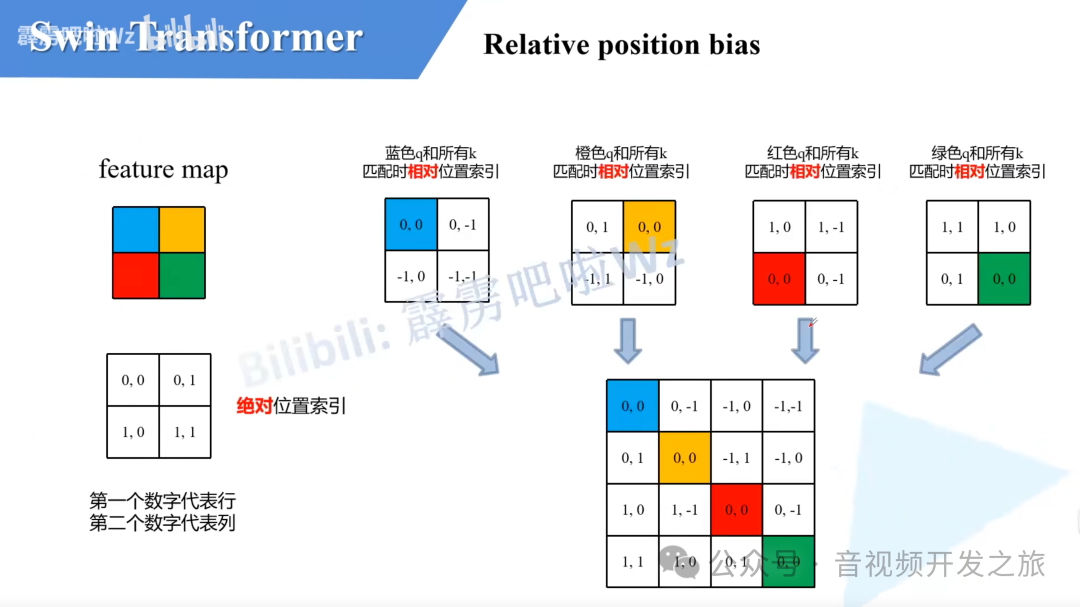
相对位置索引与相对位置偏置
相对位置偏置就是下面计算WindowAttention中的B.
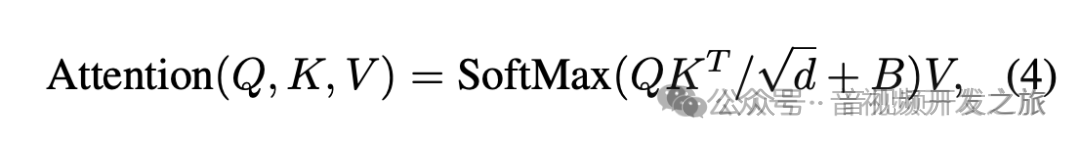
论文中没有关于相对位置索引的详细介绍,代码中看得也是一头雾水. B站视频Swin-Transformer网络结构详解-视频 解释的相当清楚,再结合源码分析有一种醍醐灌顶感觉.
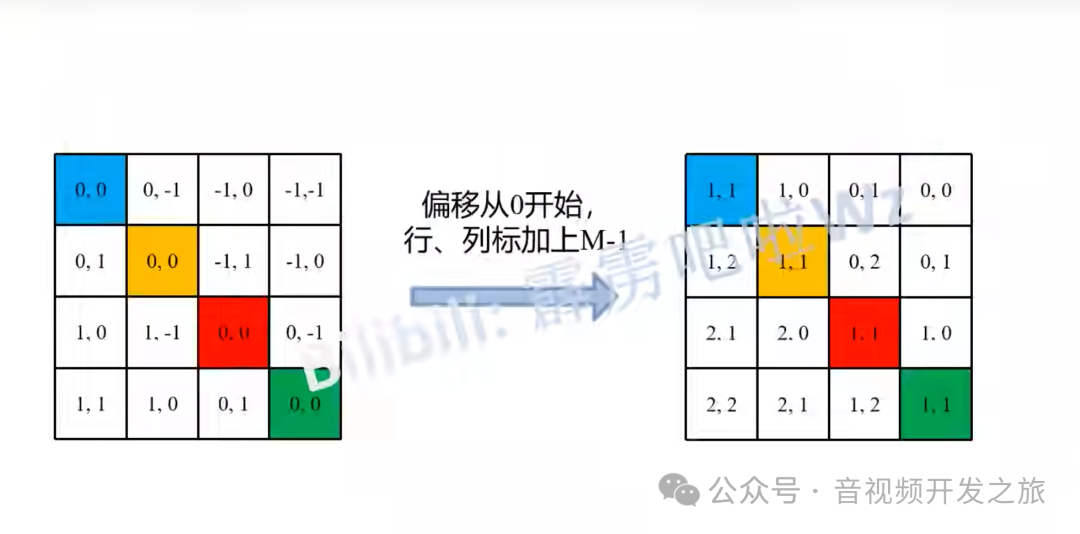
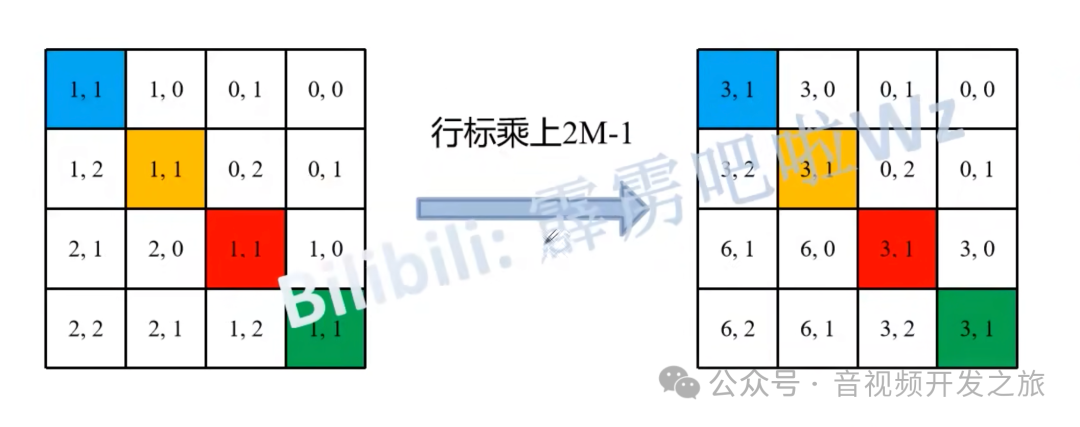
# define a parameter table of relative position bias 相对位置偏移表self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2#为了方便后续计算,相对坐标都加上偏移量,shift to start from 0relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1#后面我们需要将其展开成一维偏移量。而对于(2,1)和(1,2)这两个坐标,在二维上是不同的,但是通过将x与y坐标相加转换为一维偏移的时候,它们的偏移量是相等的,所以需要对其做乘法操作,进行区分relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1#将最后一个维度进行求和. 计算相对位置索引,它将用于索引相对位置偏移表,以便在self-attention中为每个元素分配一个特定的偏置值relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
偏移从0开始,行列都加上M-1
接着将所有的行标都乘上2M-1。
最后将行标和列标进行相加。即保证了相对位置关系,又不会出现 0 + ( − 1 ) = ( − 1 ) + 0 的问题了.太牛了
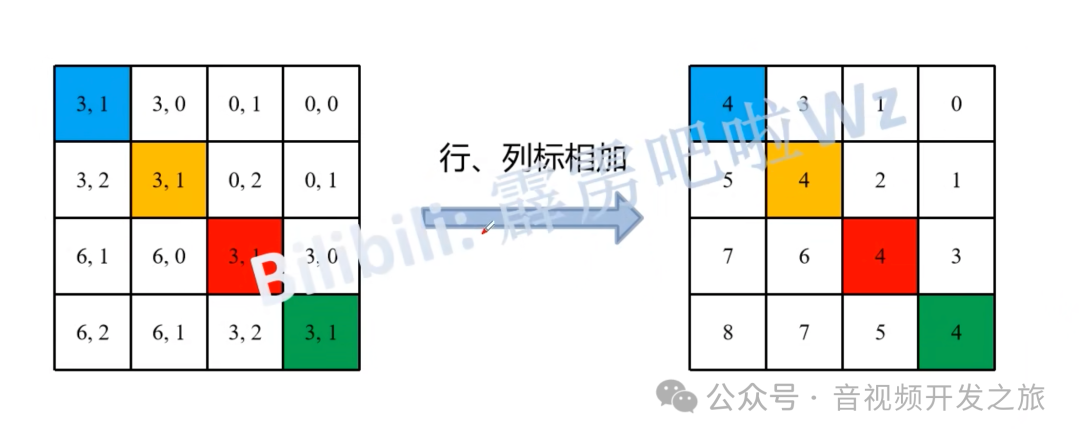
通过上面计算的相对位置索引,在相对位置索引表(relative_position_bias_table)中差表得到相对位置偏置的值B
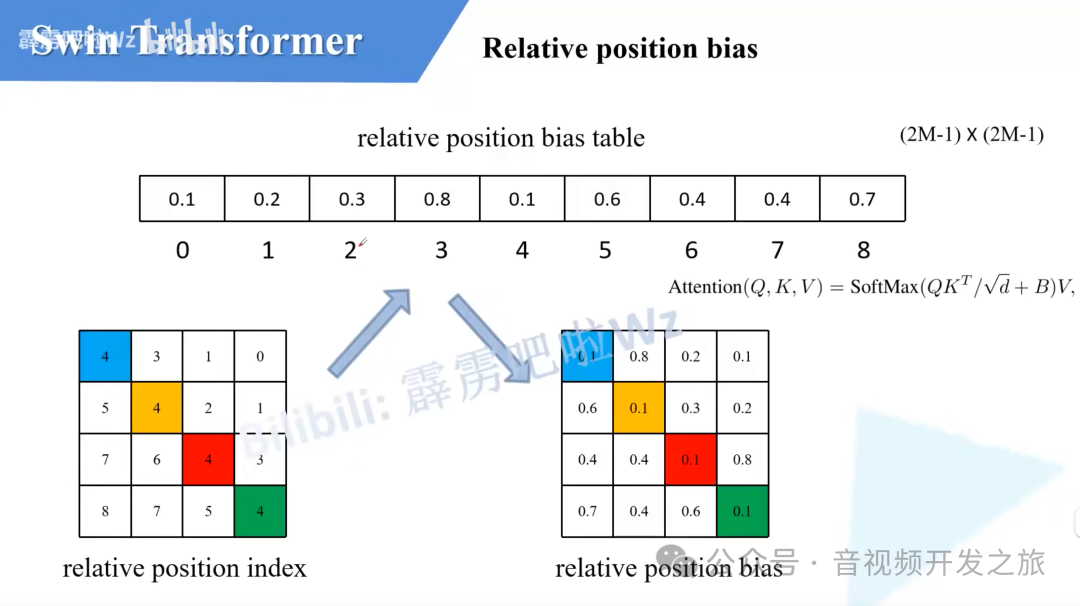
感谢霹雳吧啦Wz大佬,真是太透彻了
六. 实验结果
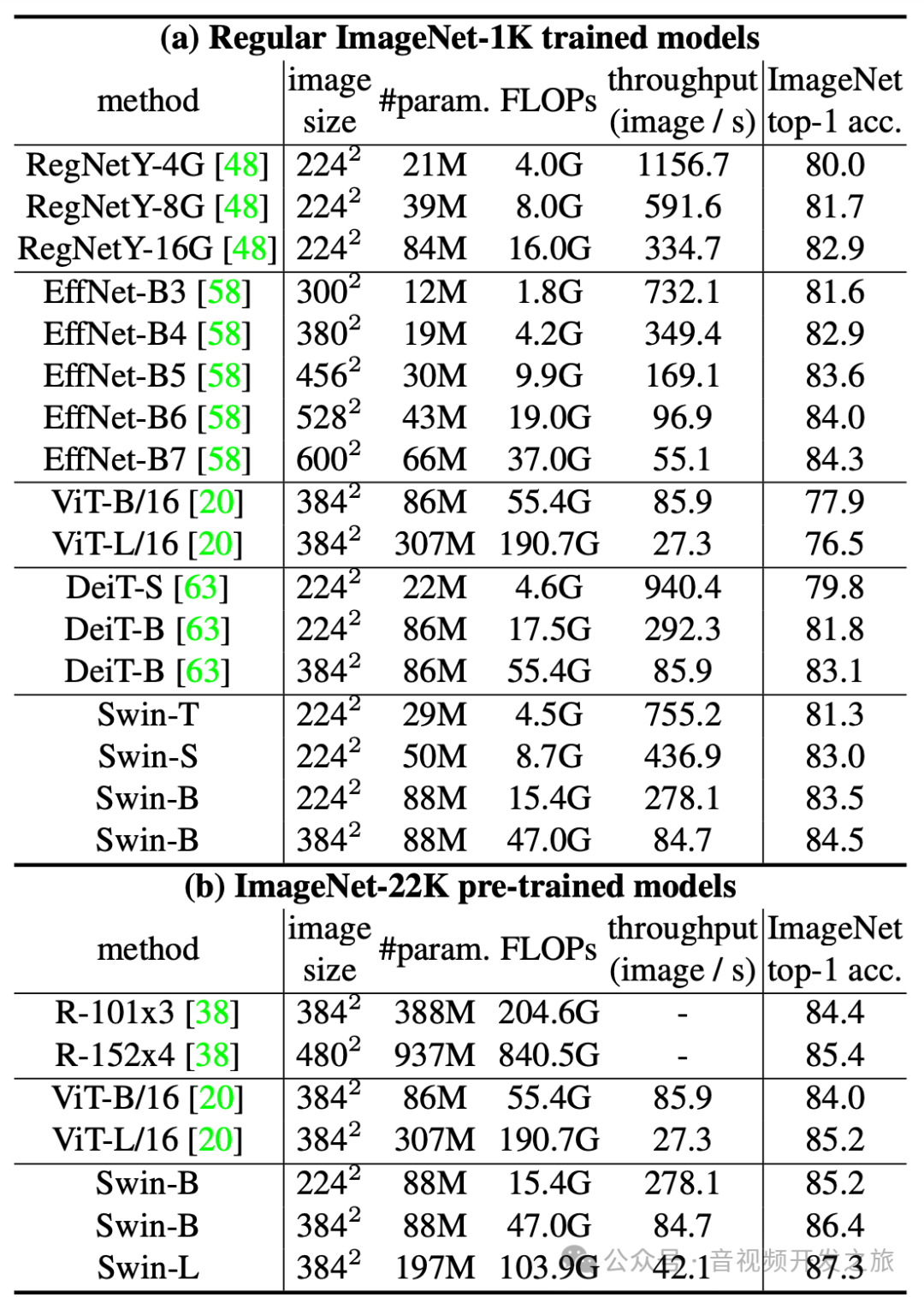
通过上表可以看出,不论是是否有预训练,SwinTransform的准确率都高于VIT,且计算量要小于VIT
七. 源码分析
源码地址https://github.com/microsoft/SwinTransformer/blob/main/models/swin_transformer.py
7.1 PatchEmbed
class PatchEmbed(nn.Module):r"""对输入的图像进行切分,对每个patch进行特征提取作为EmbeddingImage to Patch EmbeddingArgs:img_size (int): Image size. Default: 224.patch_size (int): Patch token size. Default: 4.in_chans (int): Number of input image channels. Default: 3.embed_dim (int): Number of linear projection output channels. Default: 96.norm_layer (nn.Module, optional): Normalization layer. Default: None"""def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):super().__init__()img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]self.img_size = img_sizeself.patch_size = patch_sizeself.patches_resolution = patches_resolutionself.num_patches = patches_resolution[0] * patches_resolution[1]self.in_chans = in_chansself.embed_dim = embed_dim#这里使用CNN进行特征提取作为Embedding,kernel_size为4*4,步长为4,输入channel为3,输出channel为96self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = Nonedef forward(self, x):B, C, H, W = x.shape# FIXME look at relaxing size constraintsassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]}).""""x.shape = (B,3,H,W)self.proj(x).shape = (B,96,H//4,W//4)x = self.proj(x).flatten(2).shape = (B,96,H//4 * W//4)self.proj(x).flatten(2).transpose(1, 2).shape = (B,H//4 * W//4,96)"""x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw Cif self.norm is not None:x = self.norm(x)return x
7.2 PatchMerging
class PatchMerging(nn.Module):r""" Patch Merging Layer.Patch Merging是Swin Transformer Stage的一部分,作用是分辨率减半,通道数加倍.Args:input_resolution (tuple[int]): Resolution of input feature. 输入特征图(patches)的分辨率dim (int): Number of input channels. 维度norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):super().__init__()self.input_resolution = input_resolutionself.dim = dimself.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)self.norm = norm_layer(2 * dim)def forward(self, x):"""x: B, H*W, C"""H, W = self.input_resolutionB, L, C = x.shapeassert L == H * W, "input feature has wrong size"assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."x = x.view(B, H, W, C)#将输入特征图分割为四部分,每部分都是(B,H/2,W/2,C)的形状x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 Cx1 = x[:, 1::2, 0::2, :] # B H/2 W/2 Cx2 = x[:, 0::2, 1::2, :] # B H/2 W/2 Cx3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C#最后一个维度C进行拼接,输出 (B,H/2,W/2,4*C)x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C#重新塑造形状,把 HW变为一维x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C#减少通道数,4*C变为2*Cx = self.reduction(x)x = self.norm(x)return x
7.3 WindowAttention
class WindowAttention(nn.Module):r""" Window based multi-head self attention (W-MSA) module with relative position bias.It supports both of shifted and non-shifted window.Args:dim (int): Number of input channels.window_size (tuple[int]): The height and width of the window.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if setattn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0proj_drop (float, optional): Dropout ratio of output. Default: 0.0"""def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# define a parameter table of relative position bias 相对位置偏移表self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])"""torch.meshgrid生成网格矩阵,torch.stack在新的维度堆叠起来,torch.flatten进行展平为一维张量eg:self.window_size =(2,2)torch.stack(torch.meshgrid([coords_h, coords_w]))的输出为tensor([[[0, 0, 0],[1, 1, 1],[2, 2, 2]],[[0, 1, 2],[0, 1, 2],[0, 1, 2]]])torch.flatten(coords, 1)的输出为:tensor([[0, 0, 0, 1, 1, 1, 2, 2, 2],[0, 1, 2, 0, 1, 2, 0, 1, 2]])"""coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2#为了方便后续计算,相对坐标都加上偏移量,shift to start from 0relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1#后面我们需要将其展开成一维偏移量。而对于(2,1)和(1,2)这两个坐标,在二维上是不同的,但是通过将x与y坐标相加转换为一维偏移的时候,它们的偏移量是相等的,所以需要对其做乘法操作,进行区分relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1#将最后一个维度进行求和. 计算相对位置索引,它将用于索引相对位置偏移表,以便在self-attention中为每个元素分配一个特定的偏置值relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Wwself.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)trunc_normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask=None):"""Args:x: input features with shape of (num_windows*B, N, C)mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None"""B_, N, C = x.shape'''x.shape = (num_windows*B, N, C)self.qkv(x).shape = (num_windows*B, N, 3C)self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).shape = (num_windows*B, N, 3, num_heads, C//num_heads)self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4).shape = (3, num_windows*B, num_heads, N, C//num_heads)'''qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)#为了解决不重叠窗口之间没有关联的问题,采用shifted window方法. 以(M/2,M/2)向下移动的窗口重新对原图进行分割,并将之前没有联系的patch划到新窗口.#但这带来了窗口增加的问题(4个增加到了9个),为了避免窗口增加导致的额外计算量并保证不重叠窗口之间有关联,论文提出了cyclic shift方案#为了保证shifted window self-attention计算的正确性,只能计算相同子窗口的self-attention,不同子窗口的self-attention结果要归0,# 不同编码位置间计算的self-attention结果通过mask加上-100,在Softmax计算过程中,Softmax(-100)无线趋近于0,达到归0的效果if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return x
7.4 SwinTransformerBlock
class SwinTransformerBlock(nn.Module):r""" Swin Transformer Block.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resulotion.num_heads (int): Number of attention heads.window_size (int): Window size.shift_size (int): Shift size for SW-MSA.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormfused_window_process (bool, optional): If True, use one kernel to fused window shift & window partition for acceleration, similar for the reversed part. Default: False"""def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm,fused_window_process=False):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeself.mlp_ratio = mlp_ratioif min(self.input_resolution) <= self.window_size:# if window size is larger than input resolution, we don't partition windowsself.shift_size = 0self.window_size = min(self.input_resolution)assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)if self.shift_size > 0:# calculate attention mask for SW-MSAH, W = self.input_resolutionimg_mask = torch.zeros((1, H, W, 1)) # 1 H W 1h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1mask_windows = mask_windows.view(-1, self.window_size * self.window_size)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))else:attn_mask = Noneself.register_buffer("attn_mask", attn_mask)self.fused_window_process = fused_window_processdef forward(self, x):H, W = self.input_resolutionB, L, C = x.shapeassert L == H * W, "input feature has wrong size"shortcut = xx = self.norm1(x)x = x.view(B, H, W, C)# cyclic shiftif self.shift_size > 0:if not self.fused_window_process:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))# partition windowsx_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, Celse:x_windows = WindowProcess.apply(x, B, H, W, C, -self.shift_size, self.window_size)else:shifted_x = x# partition windowsx_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, Cx_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C# W-MSA/SW-MSAattn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C# merge windowsattn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)# reverse cyclic shiftif self.shift_size > 0:if not self.fused_window_process:shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' Cx = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = WindowProcessReverse.apply(attn_windows, B, H, W, C, self.shift_size, self.window_size)else:shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' Cx = shifted_xx = x.view(B, H * W, C)x = shortcut + self.drop_path(x)# FFNx = x + self.drop_path(self.mlp(self.norm2(x)))return x
7.5 BasicLayer (即一个stage,包含SwinTransformerBlock PatchMerging模块)
class BasicLayer(nn.Module):"""BasicLayer为一个Stage,包含SwinTransformerBlock和PatchMerging模块"""def __init__(self, dim, input_resolution, depth, num_heads, window_size,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,fused_window_process=False):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.depth = depth# build blocksself.blocks = nn.ModuleList([SwinTransformerBlock(dim=dim, input_resolution=input_resolution,num_heads=num_heads, window_size=window_size,shift_size=0 if (i % 2 == 0) else window_size // 2,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop, attn_drop=attn_drop,drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer,fused_window_process=fused_window_process)for i in range(depth)])# patch merging layerif downsample is not None:self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)else:self.downsample = Nonedef forward(self, x):for blk in self.blocks:x = blk(x)if self.downsample is not None:x = self.downsample(x)return x
7.6 SwinTransformer
class SwinTransformer(nn.Module):r""" Swin Transformer网络"""def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,norm_layer=nn.LayerNorm, ape=False, patch_norm=True,use_checkpoint=False, fused_window_process=False, **kwargs):super().__init__()self.num_classes = num_classesself.num_layers = len(depths)self.embed_dim = embed_dimself.ape = apeself.patch_norm = patch_normself.num_features = int(embed_dim * 2 ** (self.num_layers - 1))self.mlp_ratio = mlp_ratio# split image into non-overlapping patchesself.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,norm_layer=norm_layer if self.patch_norm else None)num_patches = self.patch_embed.num_patchespatches_resolution = self.patch_embed.patches_resolutionself.patches_resolution = patches_resolution# absolute position embeddingif self.ape:self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))trunc_normal_(self.absolute_pos_embed, std=.02)self.pos_drop = nn.Dropout(p=drop_rate)# stochastic depthdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule# build layersself.layers = nn.ModuleList()for i_layer in range(self.num_layers):layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),input_resolution=(patches_resolution[0] // (2 ** i_layer),patches_resolution[1] // (2 ** i_layer)),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,mlp_ratio=self.mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,use_checkpoint=use_checkpoint,fused_window_process=fused_window_process)self.layers.append(layer)self.norm = norm_layer(self.num_features)self.avgpool = nn.AdaptiveAvgPool1d(1)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)@torch.jit.ignoredef no_weight_decay(self):return {'absolute_pos_embed'}@torch.jit.ignoredef no_weight_decay_keywords(self):return {'relative_position_bias_table'}def forward_features(self, x):x = self.patch_embed(x)if self.ape:x = x + self.absolute_pos_embedx = self.pos_drop(x)for layer in self.layers:x = layer(x)x = self.norm(x) # B L Cx = self.avgpool(x.transpose(1, 2)) # B C 1x = torch.flatten(x, 1)return xdef forward(self, x):x = self.forward_features(x)x = self.head(x)return x
存在一定的不足:
-
模型规模不够大
-
预训练与下游任务图片分辨率和窗口大小不适配
在Swin Transformer V2论文给出了解决方案,有兴趣可以进一步研究.
Swin Transformer 2.0 使得模型规模更大并且能适配不同分辨率的图片和不同尺寸的窗口
八. 资料
1.Swin Transformer 论文:https://arxiv.org/pdf/2103.14030
2.Swin Transformer V2论文:https://arxiv.org/pdf/2111.09883
https://github.com/microsoft/Swin-Transformer/tree/main/models
3.图解Swin Transformer https://zhuanlan.zhihu.com/p/367111046
4.Swin-Transformer网络结构详解-视频 https://www.bilibili.com/video/BV1pL4y1v7jC
5.Swin-Transformer网络结构详解-文章 https://blog.csdn.net/qq_37541097/article/details/121119988
6.https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/swin_transformer
7.论文详解:Swin Transformer https://zhuanlan.zhihu.com/p/430047908
8.CV+Transformer之Swin Transformer https://zhuanlan.zhihu.com/p/361366090
9.AI大模型系列之三:Swin Transformer 最强CV图解 https://blog.csdn.net/Peter_Changyb/article/details/137183056
10.Swin Transformer 论文详解及程序解读 https://zhuanlan.zhihu.com/p/401661320
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









