







将pytorch训练好的模型转cpp
1. 载入预训练的模型
和使用pytorch一样,载入预训练的模型,并将模型设置为“eval”模式。
code
net = YuFaceDetectNet(phase='test', size=None ) # initialize detector
net = load_model(net, args.trained_model, True)
net.eval()
2. 将模型的参数保存
因为模型只用了三种基本操作:conv,batchnorm,relu。这里只有conv和batchnorm层是有参数需要保存,并且作者将conv和batchnorm的参数进行了融合
conv和batchnorm的融合可以参考:https://zhuanlan.zhihu.com/p/49329030和pytorch batchnorm2d的公式
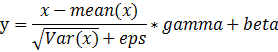
知乎的文章公式有点小问题,最好自己推导一下。libfacedetection项目是没有问题的
code
conv_result = nn.Conv2d(self.in_channels, self.out_channels,
self.conv.kernel_size, stride=self.conv.stride,
padding=self.conv.padding, bias=True) # 初始化一个conv操作,然后将预训练模型的参数写入进去
scales = self.bn.weight / torch.sqrt(self.bn.running_var + self.bn.eps) # 将conv和batchnorm进行融合
conv_result.bias[:] = (self.conv.bias - self.bn.running_mean) * scales + self.bn.bias
for ch in range(self.out_channels):
conv_result.weight[ch, :, :, :] = self.conv.weight[ch, :, :, :] * scales[ch]
3. 将参数转成int8
应该是为了提速将模型中conv的weight和bias参数都转换成了int8
具体要看libfacedetection的推理代码了
code
scale = 127 / maxvalue # 转成int8类型的范围
intw = np.round(w * scale).astype(int)
intb = np.round(b * scale).astype(int)
4. 将模型参数写入文件中
code
with open(filename, 'w') as f:
f.write(result_str)
f.close()
TO DO
- 解读libfacedetection的推理代码















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









