







1. 导语
国产化AI芯片的发展不仅反映了中国在信息技术产业的战略布局,更是对全球科技竞争格局的积极回应。随着人工智能与大数据技术的飞速进步,国内对高性能计算的需求日益增长,促使科研机构与高新技术企业加大对AI芯片研发的投入,旨在打破海外技术垄断,保障国家信息安全与技术自主。
2. 国产化AI芯片模型部署的重要意义
•安全与自主可控:在全球化的背景下,依赖海外AI芯片技术可能使国家面临供应链中断的风险,尤其是在当前国际形势复杂多变的环境下。国产AI芯片的部署,能够有效降低这种依赖,增强国家在关键技术领域的自给自足能力,保障国家安全与数据隐私。
•技术创新与核心竞争力提升:发展国产AI芯片不仅能够促进国内企业在芯片设计与制造领域的技术突破,还能加速上下游产业链的成熟,形成完整的创新生态系统。这将显著提升中国在全球AI芯片市场的竞争力,推动国内企业走向世界舞台。
•经济与社会价值:国产AI芯片的广泛应用将催生新的商业模式与应用场景,如智能制造、智慧城市、医疗健康等,带动经济增长点的形成。同时,通过推动技术普及与应用,可以提升公众生活质量,促进社会公平与可持续发展。
3. 香橙派 AIpro的硬件配置
CPU:昇腾 AI 处理器 4 核 64 位 Arm 处理器 + AI 处理器
NPU:
• 半精度(FP16):4 TFLOPS
• 整数精度(INT8):8 TOPS
内存:8GB 或 16GB
存储:
• 板载 32MB 的 SPI Flash
• Micro SD 卡插槽
• eMMC 插座:可外接 eMMC 模块
• M.2 M-Key 接口:可接 2280 规格的 NVMe SSD 或 SATA SSD
以太网:
• 支持 10/100/1000Mbps
• 板载 PHY 芯片:RTL8211F
Wi-Fi+蓝牙
• 支持 2.4G 和 5G 双频 WIFI
• BT4.2
• 模组:欧智通 6221BUUC
USB
• 2 个 USB3.0 Host 接口
• 1 个 Type-C 接口(只支持 USB3.0,不支持 USB2.0)
摄像头
2 个 MIPI CSI 2 Lane 接口
显示
• 2 个 HDMI 接口
• 1 个 MIPI DSI 2 Lane 接口
音频
• 1 个 3.5mm 耳机孔,支持音频输入输出
• 2 个 HDMI 音频输出
支持的操作系统
Ubuntu 22.04 和 openEuler 22.03
来张实图:

- 部署流程
整体流程是基于现有模型、使用pyACL提供的Python语言API库开发深度神经网络应用,用于实现目标识别、图像分类等功能。
整体流程如下图所示:
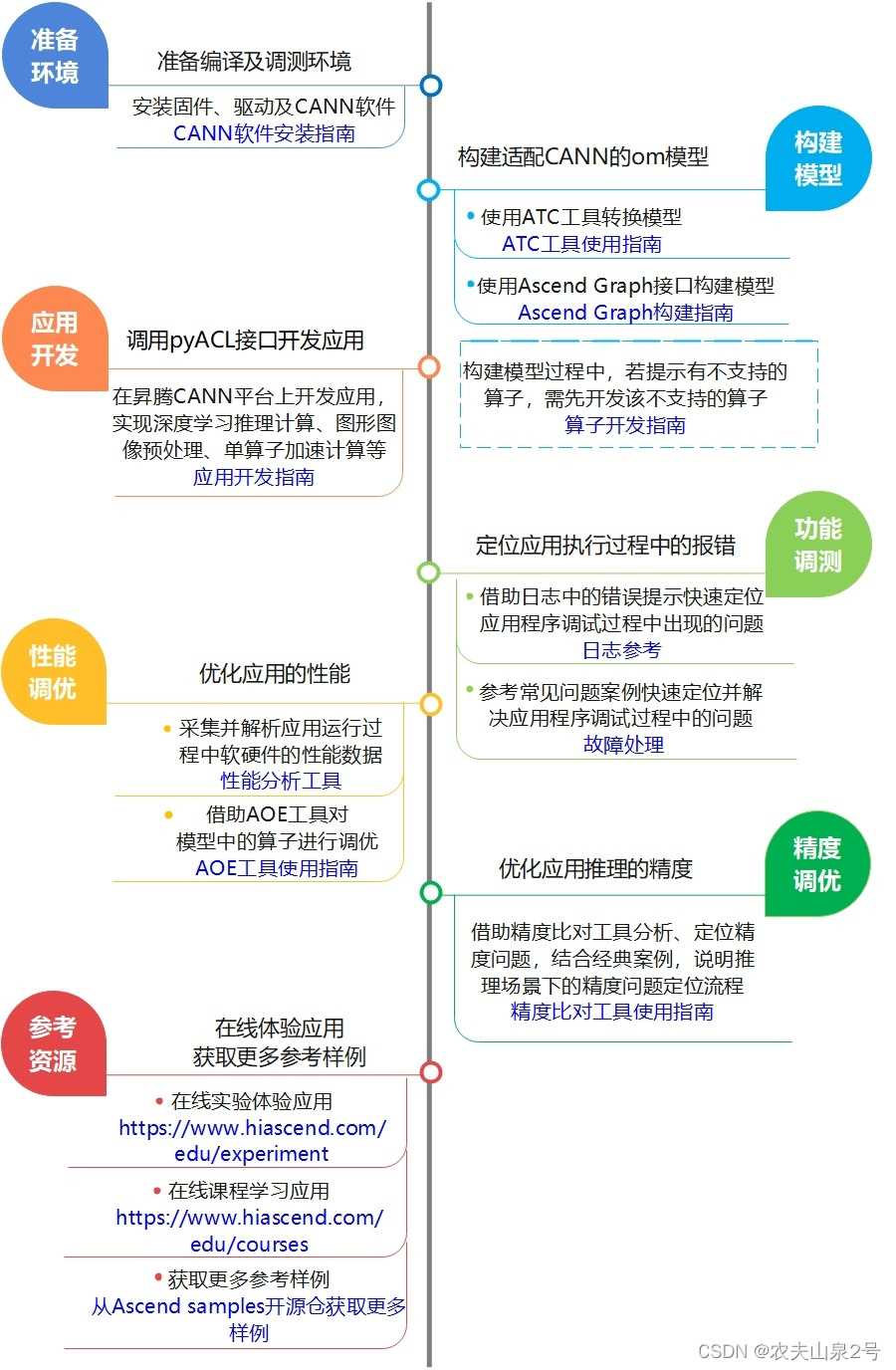
我们基于已有的系统进行开发,无须进行环境的搭建。我们只需要进行后面的模型转换,再调用python接口进行模型推理,。
5. 官方目标检测yolov5测试
登录 Linux 系统桌面,然后打开终端,再切换到保存 AI 应用样例的目录下,然后执行 start_notebook.sh 脚本启动 Jupyter Lab。
cd cd samples/notebooks
./start_notebook.sh
然后我们选择yolov5的项目,用我们自己的图像进行测试。
infer_mode = 'image'
if infer_mode == 'image':
img_path = '000000.jpg'
infer_image(img_path, model, labels_dict, cfg)
结果可视化

为模型加上推理耗时统计代码,统计前进行5次预热推理。这样统计的时间更加精确。
# 预热
for _ in range(5):
output = model.infer([img])[0]
# 模型推理
s0 = time.perf_counter()
for i in range(10):
output = model.infer([img])[0]
s1 = time.perf_counter()
print(f"模型推理耗时: {(s1-s0) * 1000 / 10} ms")
结果
[INFO] acl init success
[INFO] open device 0 success
[INFO] load model yolo.om success
[INFO] create model description success
模型推理耗时: 41.645452300144825 ms
odel success, model Id is 1
[INFO] end to destroy context
[INFO] end to reset device is 0
[INFO] end to finalize acl
6. own人脸模型face-parse测试
人脸分割模型为人像美颜,人像AR,人像AE调整等各种应用提供了基础能力,这里我们测试香橙派AIpro在通用模型部署上的通用性。
1.首先从百度网盘百度网盘 请输入提取码 code: 8gin,下载开源的模型:face_parsing_512x512.onnx
2.采用如下命令将onnx模型转换成ascend芯片支持的om模型,转换成功之后获得face_parse.om文件
atc --model=face_parsing_512x512.onnx --framework=5 --output=face_parse --input_format=NCHW --input_shape="input:1,3,512,512" --log=error --soc_version=Ascend310B13.然后使用以下的代码进行测试。
import cv2
import numpy as np
import ipywidgets as widgets
from IPython.display import display
import torch
from skvideo.io import vreader, FFmpegWriter
import IPython.display
from ais_bench.infer.interface import InferSession
from det_utils import letterbox, scale_coords, nms
import time
from PIL import Image
def preprocess_image(image, shape, bgr2rgb=True):
"""图片预处理"""
img, scale_ratio, pad_size = letterbox(image, new_shape=shape)
if bgr2rgb:
img = img[:, :, ::-1]
img = img.transpose(2, 0, 1) # HWC2CHW
img = np.ascontiguousarray(img, dtype=np.float32)
return img, scale_ratio, pad_size
class InferEngine(object):
def __init__(self, model_path, infer_shape) -> None:
self.model = InferSession(0, model_path)
self.infer_shape = infer_shape
def generate_mask(self, img, seg, scale=0.4):
'分割结果可视化'
color = [
[255, 0, 0],
[255, 85, 0],
[255, 170, 0],
[255, 0, 85],
[255, 0, 170],
[0, 255, 0],
[85, 255, 0],
[170, 255, 0],
[0, 255, 85],
[0, 255, 170],
[0, 0, 255],
[85, 0, 255],
[170, 0, 255],
[0, 85, 255],
[0, 170, 255],
[255, 255, 0],
[255, 255, 85],
[255, 255, 170],
[255, 0, 255],
[255, 85, 255]
]
img = img.transpose(1, 2, 0) # HWC2CHW
minidx = int(seg.min())
maxidx = int(seg.max())
color_img = np.zeros_like(img)
for i in range(minidx, maxidx):
if i <= 0:
continue
color_img[seg == i] = color[i]
showimg = scale * img + (1 - scale) * color_img
Image.fromarray(showimg.astype(np.uint8)).save("face_parse_res.png")
def infer_image(self, img_path, times=10):
# 图片载入
image = cv2.imread(img_path)
# 数据预处理
img, scale_ratio, pad_size = preprocess_image(image, self.infer_shape)
showimg = img.copy()
mean = np.asarray([0.485, 0.456, 0.406])
scale = np.asarray([0.229, 0.224, 0.225])
mean = mean.reshape((3, 1, 1))
scale = scale.reshape((3, 1, 1))
img = (img / 255 - mean) * scale
img = img.astype(np.float32)
for _ in range(5):
output = self.model.infer([img])[0]
# 模型推理
s0 = time.perf_counter()
for i in range(times):
output = self.model.infer([img])[0]
s1 = time.perf_counter()
print(f"模型推理耗时: {(s1-s0) * 1000 / times} ms")
seg = np.argmax(output, axis=1).squeeze()
self.generate_mask(showimg, seg)
if __name__ == '__main__':
# atc --model=face_parsing_512x512.onnx --framework=5 --output=face_parse --input_format=NCHW --input_shape="input:1,3,512,512" --log=error --soc_version=Ascend310B1
imgpath = 'test_lite_face_parsing.png'
modelpath = 'face_parse.om'
shape = (512, 512)
net = InferEngine(modelpath, shape)
out = net.infer_image(imgpath)
测试图像/可视化结果


7. 模型推理耗时统计
| 序号 | 模型 | 分辨率 | om模型大小/MB | 推理耗时/ms |
| yolov5s | 640x640 | 15 | 40.99 | |
| face_parse | 512x512 | 26 | 106.46 |
- 总结
优点:
- 香橙派AIpro全国产,在中美关系紧张下能替代nVidia jetson。
- 部署方便,模型转换,python调用,都很适合新手入手
- 文档和工具链完善方便学习
缺点:
- 发热严重,边跑程序,边写文档就很卡了。
TODO
- 更多sample的部署测试
- c++ api的调用
- 梳理asend的芯片链条
参考:
- CANN说明文档:什么是AIPP-AIPP使能-高级功能-ATC模型转换-推理应用开发-CANN商用版6.3.RC2开发文档-昇腾社区
- 浅谈国产化AI芯片模型部署实践:https://zhuanlan.zhihu.com/p/663715171















 1459
1459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









