







 本文介绍了强化学习的基本概念和结构,通过实例讲解如何使用Python训练智能体玩Flappy Bird游戏。智能体由神经网络构成,通过与环境交互并根据奖励进行迭代训练,实现游戏的自动控制。文章还分享了两个实现代码链接,展示强化学习在游戏控制领域的应用。
本文介绍了强化学习的基本概念和结构,通过实例讲解如何使用Python训练智能体玩Flappy Bird游戏。智能体由神经网络构成,通过与环境交互并根据奖励进行迭代训练,实现游戏的自动控制。文章还分享了两个实现代码链接,展示强化学习在游戏控制领域的应用。
1 概述
强化学习是机器学习里面的一个分支。它强调如何基于环境而行动,以取得最大化的预期收益。其灵感来源于心理学中的行为主义理论,既有机体如何在环境给予的奖励或者惩罚的刺激下,逐步形成对刺激的预期,产生能够最大利益的习惯性行为。结构简图如下:
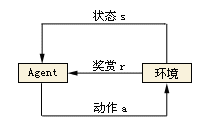
因为强化学习考虑到了自主个体、环境、奖励等因素,所以很多人包括强化学习的研究者Richard Sutton 都认为它是人工智能中最高层的模型,其它深度学习、机器学习模型都是它的子系统。
在围棋界先后打败世界冠军的李世乭和柯洁额alphaGo就使用了强化学习模型,也正是这两次比赛,把人工智能这个概念传递给了大众。
2 结构
智能体(Agent):智能体的结构可以是一个神经网络,可以是一个简单的算法,智能体的输入通常是状态State,输出通常是策略Policy。
动作(Actions):动作空间。比如小人玩游戏,只有上下左右可移动,那Actions就是上、下、左、右。
状态(State):就是智能体的输入
奖励(Reward):进入某个状态时,能带来正奖励或者负奖励。
环境(Environment):接收action,返回state和reward。
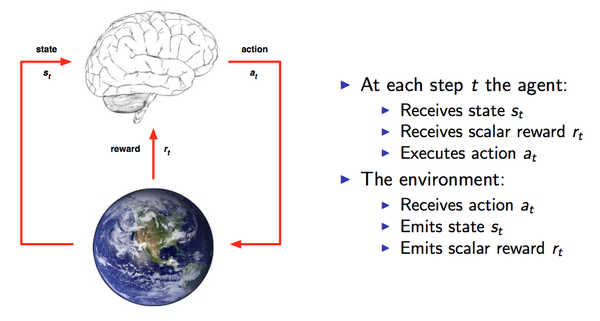
3 思想
智能体对环境执行一个动作,环境接收动作后把当前状态和奖励返回给智能体;然后智能体根据环境返回的状态和奖赏执行下一个动作。
4 相关概念
探索(exploration): 不去选择最优解,而是随机选择
开发(exploitation):选择最优解
马尔科夫决策: 马尔科夫决策过程指你接下来的所有状态和决策只取决于你当前的状态和决策。比如你下象棋,你走第四步时,影响你决策和接下来状态的只有第三步。
5 执行过程
拿教电脑玩flappybird游戏来说明:
我们需要确定的两个东西是游戏,一个是电脑,
目的是电脑玩游戏。
游戏接收一个Action操作,Action是一个一维数组,比如a = [0,1] 当a[1] = 1的时候,我们让小鸟向上飞。如果是其它的数,小鸟下落。
游戏返回的是什么呢,游戏返回的是State,reward,terminal。terminal是一个布尔值True或者false,它和reward是对应的。当reward=-1时,terminal为True。reward取值有三种(1,-1,0.1)当crash时为-1,当越过障碍时为1,其它状态为0.1。而State的结构是类似80x80x4这样的图像。
也就是 currentState, reward,newState, terminal是一条数据被保存起来了。
好现在我们有了游戏的输入和输出。
看一下人的输入和输出。这里的人其实就是一个神经网络。
它是边训练,边迭代。
它的输入是state,这个有了。
但是我们还没有y啊 ,没有y我们怎么进行迭代呢。
y的计算方法是:如果停止了,y就等于本次的reward。如果这次没有停止,就等于这次的reward加上下次的价值Q
好了 有了y和x和神经网络的结构
我们的目标函数是二次函数。(y-QValue)^2。
6 推导
就是我们定义一个概念叫价值(Value),就是在某个时刻,某个状态下执行某个动作会得到一个回报(Reward),然后在下一个时刻执行某个动作又会得到一个回报,依次类推。
我们把这些回报累加起来:

这里的G相当于目前状态决策下的总回报。
如果我们把该回报的价值用一个价值函数来表示:
v(s)=E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8053
8053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









