







文章来源于微信公众号(茗创科技),欢迎有兴趣的朋友搜索关注。
今天给大家介绍元分析软件 CMA 2.0 (Comprehensive Meta Analysis)。CMA 是一个专门用于元分析的程序,它包括三个版块:数据输入,数据分析,高分辨率图。
如果有小伙伴想学元分析,但是还不了解元分析是什么的话,可以看一看我们往期的元分析推文,帮助你更容易上手元分析 CMA 软件。
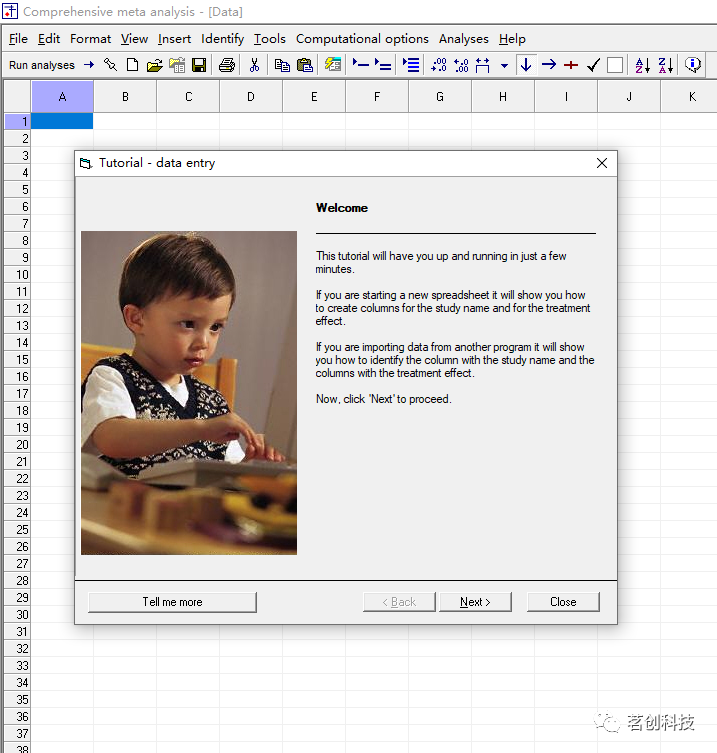
元分析的安装过程十分简单,这里就不再赘述。安装好后,在桌面上的图标是这样的。

打开 CMA,选择打开一个空白的表格,单击确定
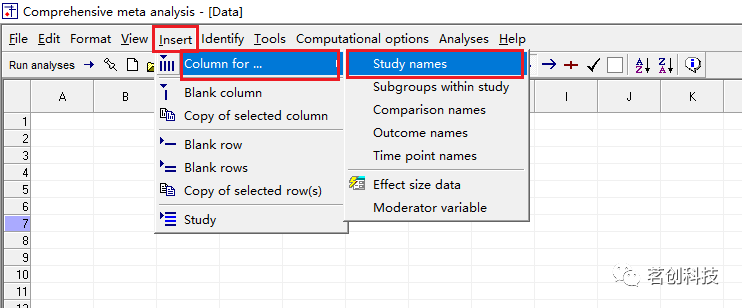
插入一列研究名称,即点击 Insert--Column for--Study names
这里以‘评估利尿剂降低子痫前期(PE)风险的能力’为例,患者被随机分配到治疗组或对照组,研究人员跟踪了每组中出现PE的人数。
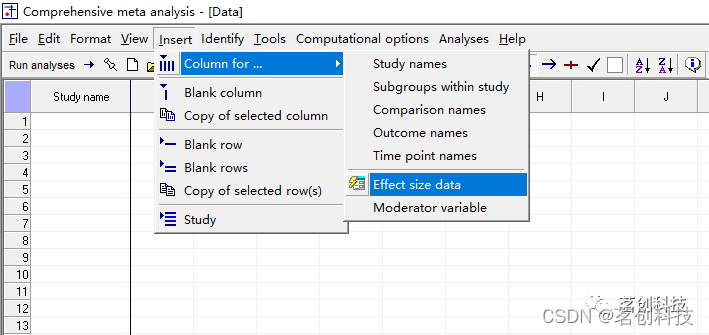
插入一列处理效果(或称疗效),即点击 Insert--Column for--Effect size data ![]()
单击两次 Next 会出来以下窗口:

这里一直点开,分别表示
-
两组(事件数)
-
不匹配组、前瞻性数据(如对照试验、队列研究)
-
每组的事件和样本量
-
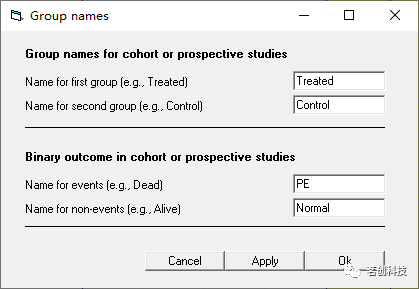
单击 Finish
给这些组命名。组名称输入“Treated”和“Control”。结果输入“PE”和“Normal”,单击“OK”
此时的表格应该是这样的:
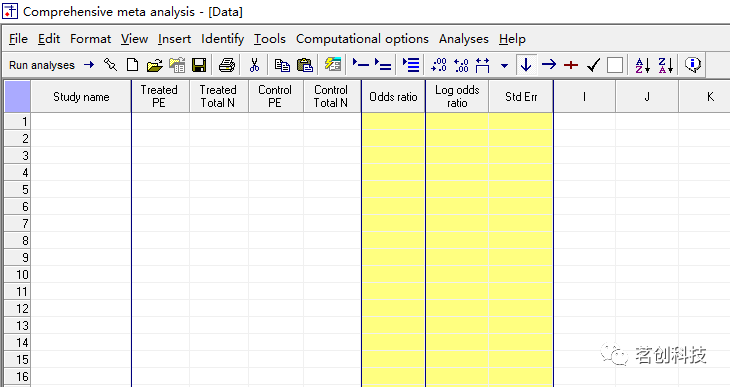
将初步研究的数据输入到第一行的白细胞中。
研究名称为:Weseley
Treated Events:14
Treated Total N:131
Control Events:14
Control Total N:136
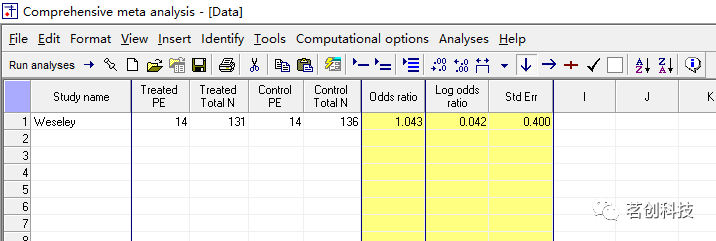
输入剩余数据。可手动输入,也可以将你所要研究的数据保存为“XXX.cma”格式,然后从“Files”菜单栏打开你保存的数据副本。
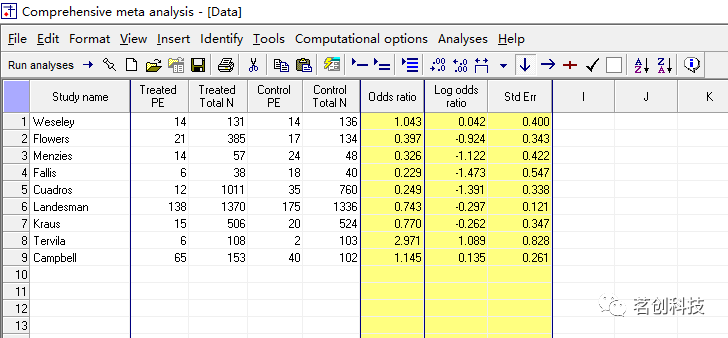
运行分析。即点击工具栏上的“Run Analysis”
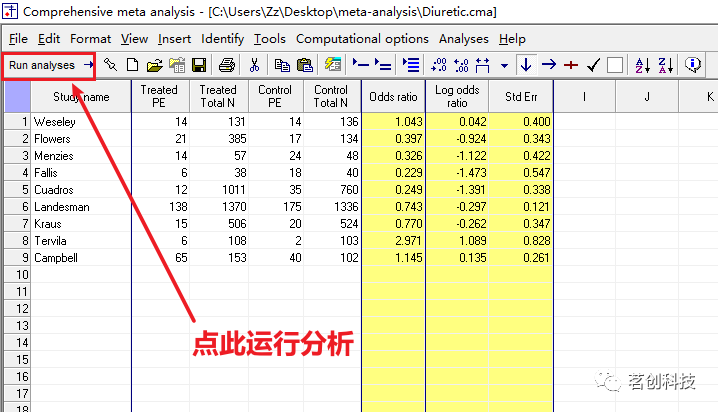
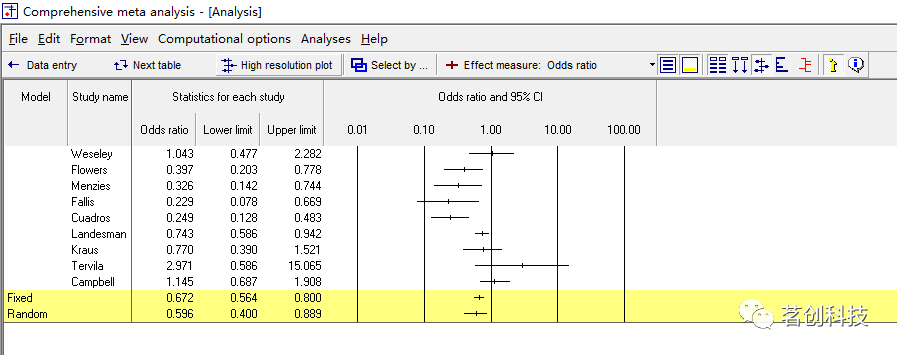
运行结果如下:
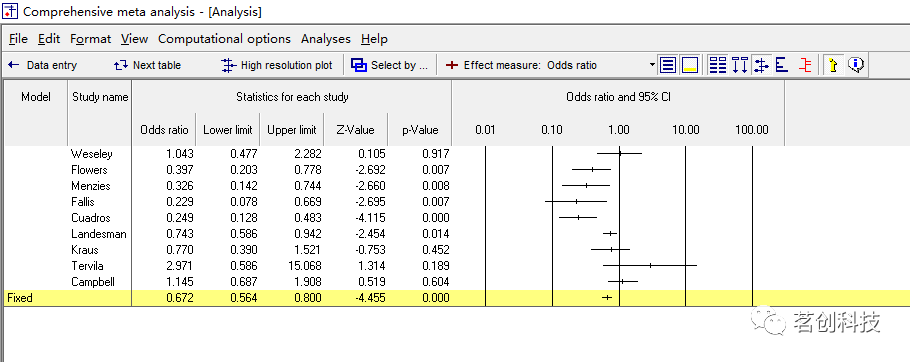
对于每一项研究,都显示了比值比(或称 OR 值)、下限和上限、Z 值和 p 值。右边则是一个森林图,其中每个研究的比值比由一个点表示,受其置信区间的限制。上图的比值比为 1.00,表示没有治疗效果。对于大多数研究来说,比值比低于 1.00,表明接受利尿剂治疗的患者不太可能发生PE。在一些研究中,比值比高于 1.00,表明接受利尿剂治疗的患者更有可能发生PE。每个研究的置信区间边界反映了估计的精度,小规模研究的置信区间较宽,大规模研究的置信区间较窄。在这幅图中,使用了 95% 的置信区间,因此这项研究统计学上的显著性为 p<0.05,当且仅当置信区间排除了空值 1.0。该图上的黄色底线被标记为“Fixed”,显示了 13 个研究的综合效应,使用固定效应模型。即比值比为 0.67,95% 置信区间为 0.56~0.80,Z 值为 -4.45,p 值<0.000。
生成高分辨率图。即点击工具栏上的“High-resolution plot”。如下图所示
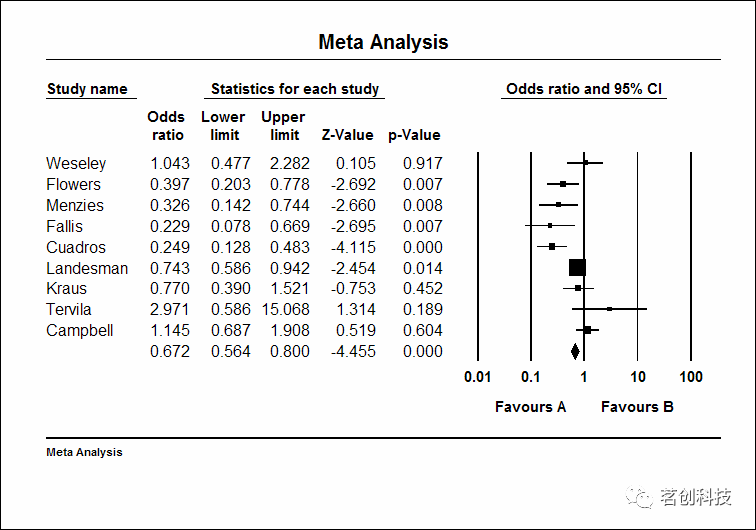
现在,是不是对 CMA 有了基本的了解?如何输入数据、如何运行分析以及如何生成高分辨率的图。然后,你可以尝试用 CMA 完成其它选项操作。比如,
①在数据输入部分,你可以:
-
查看公式
-
自定义显示
-
不止使用一个格式来输入数据
......
②在分析部分,可以:
-
显示额外的统计数据
-
选择计算模型
-
显示权重
......
③在高分辨率绘图部分,可以:
-
修改研究符号
-
修改图的宽度
-
改变配色方案
-
将图导出到 PPT 或 Word
......
①首先看数据输入部分
我们先把刚刚的高分辨率图和分析界面关闭,直接回到数据输入界面。
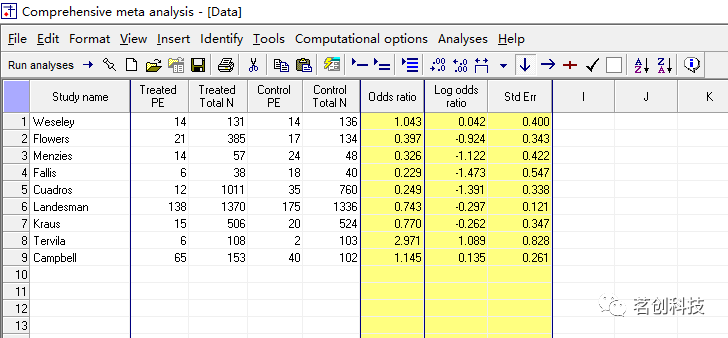
我们可以完成一系列未知按钮和界面的操作,比如,当我们在输入“Treated”和“Control”四列数值之后,这个黄色区域的值就自动计算出来了,是怎么计算的呢?
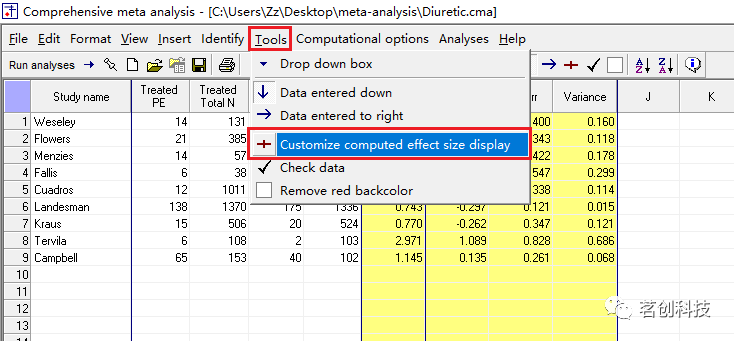
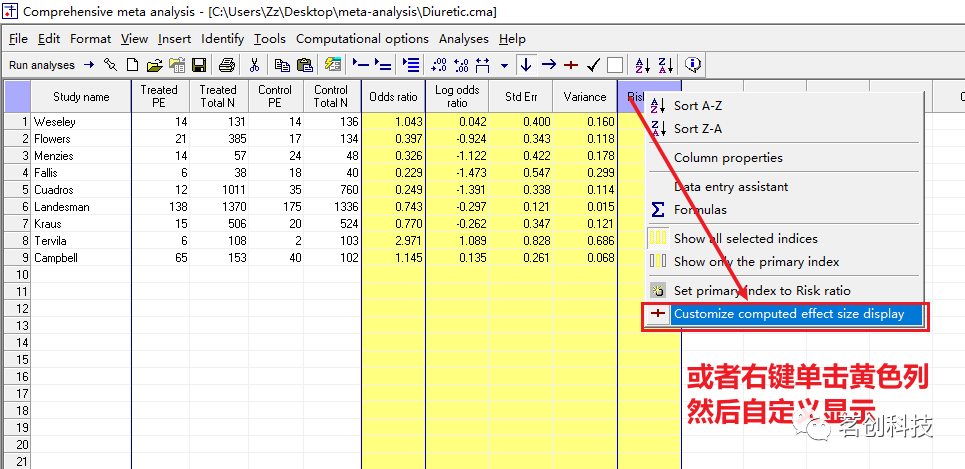
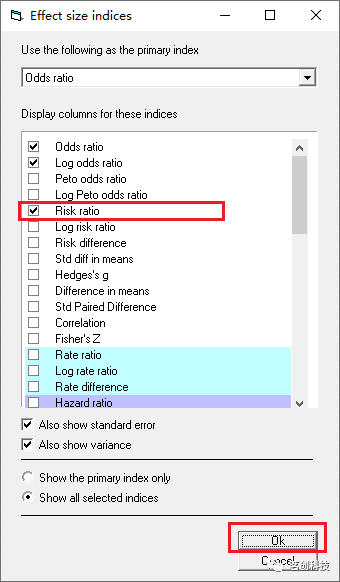
如何显示风险比?一般默认的显示是比值比,你也可以自定义显示。即点击Tools--Customize computed effect size display;或者右键单击黄色列--Customize computed effect size display
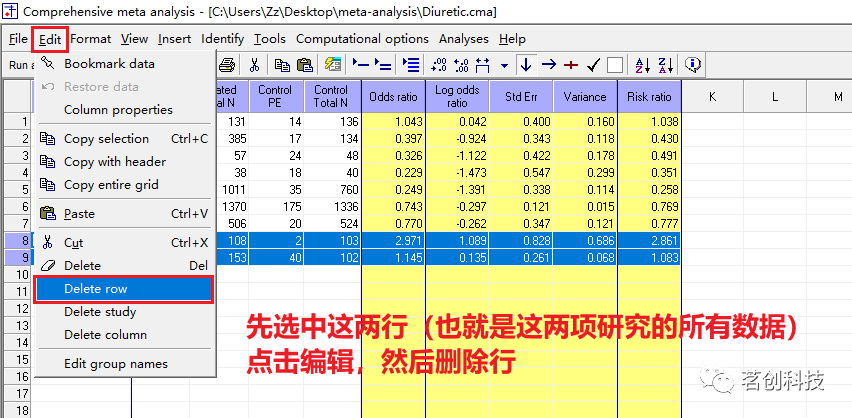
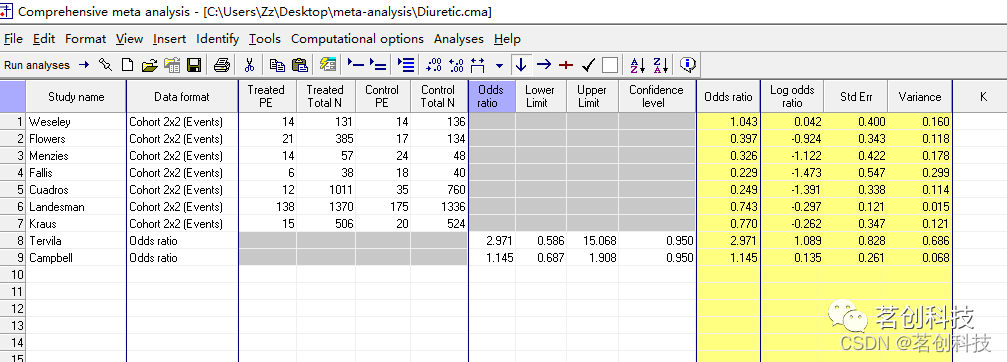
如何输入多种格式的数据?比如元分析的过程中可能会出现,一些研究以另一种格式呈现数据,那么这时候我们该怎么做?假设在该例子中的最后两个研究,Tervilla和Campbell已经发表了比值比和置信区间,就需要插入一组额外的列来适应这种新的数据格式。这里先把Tervilla和Campbell从数据集中删除,以便用新的格式将它们重新输入。
点击 Insert--Column for--Effect size data
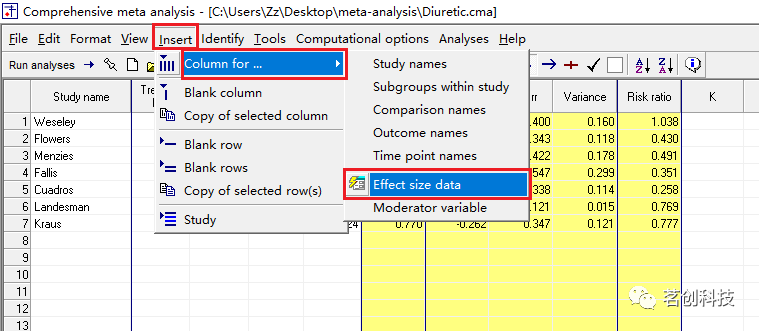
然后就会呈现这样一个对话框。注:蓝色字体表示是现有的格式(事件和样本量)。
![]()
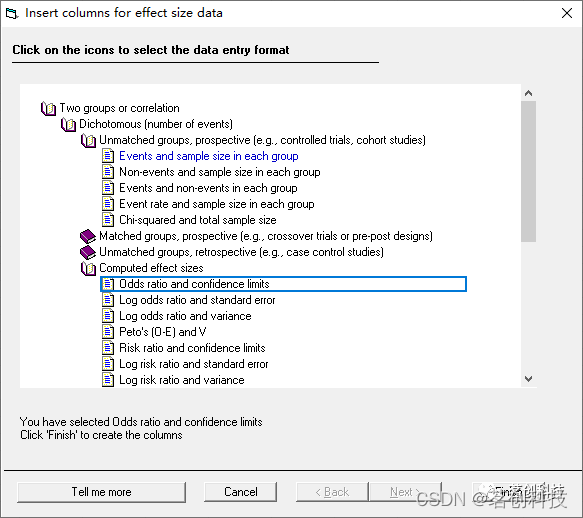
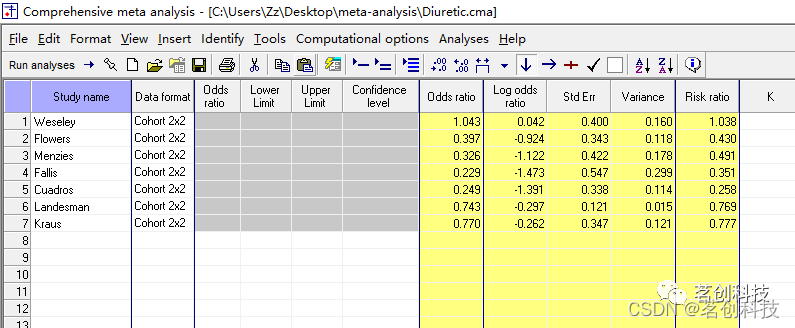
按顺序依次点击 Dichotomous (number of events)--Computed effect sizes--Odds ratio and confidence limits--Finish,数据界面就变成如下图所示:
在屏幕的左下角有关于队列 2×2(事件)和比值比的标签。可以单击这两个标签,在两种格式之间进行切换。
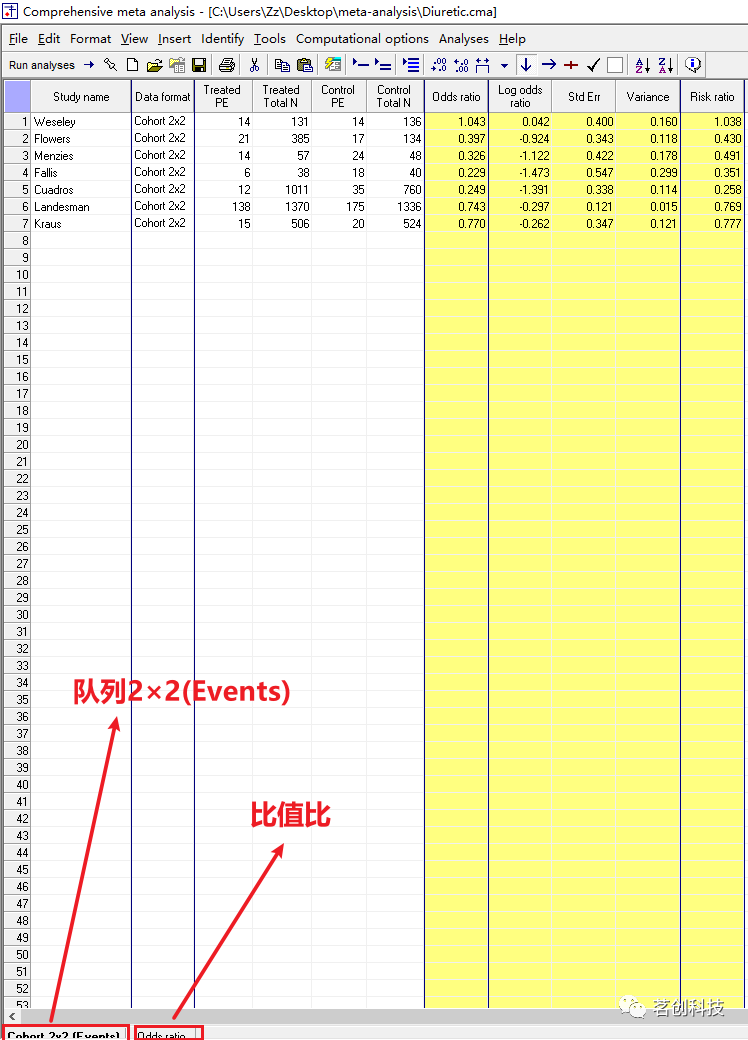
为这两个研究输入如下数据。注意,不要在标有“Data format(数据格式)”的列中输入任何内容。
研究名称:Tervila
Odds ratio:2.971
Lower limit:.586
Upper limit:15.068
Confidence level:0.95
研究名称:Campbell
Odds ratio:1.145
Lower limit:0.687
Upper limit:1.908
Confidence level:0.95
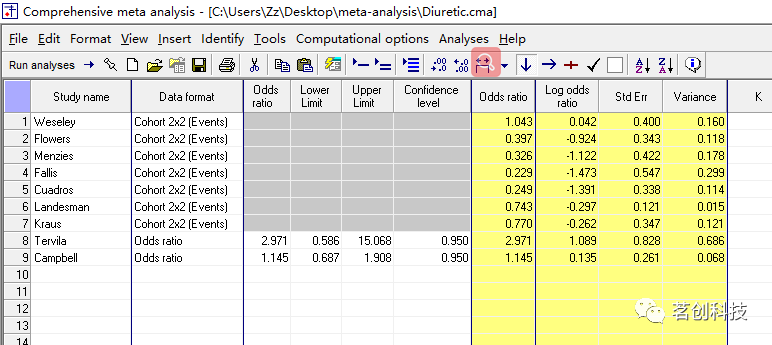
这里只显示了这两个研究的数据,如果想要查看所有数据,用鼠标右键单击白色列(例如比值比列),并选择显示所有数据输入格式。
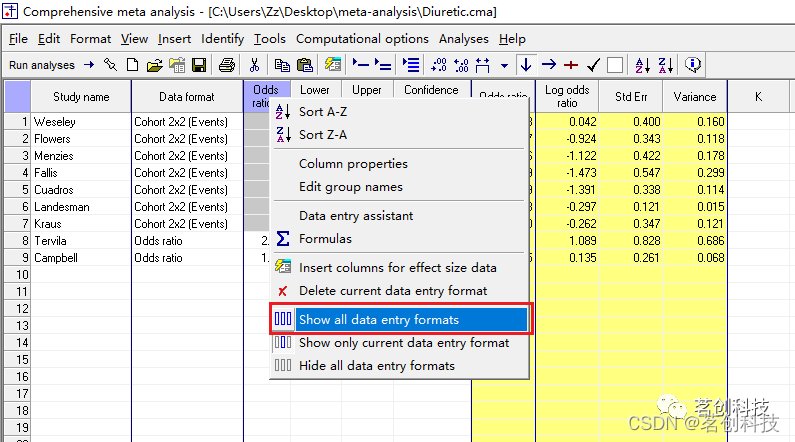
然后,所有数据显示情况如下图所示:![]()
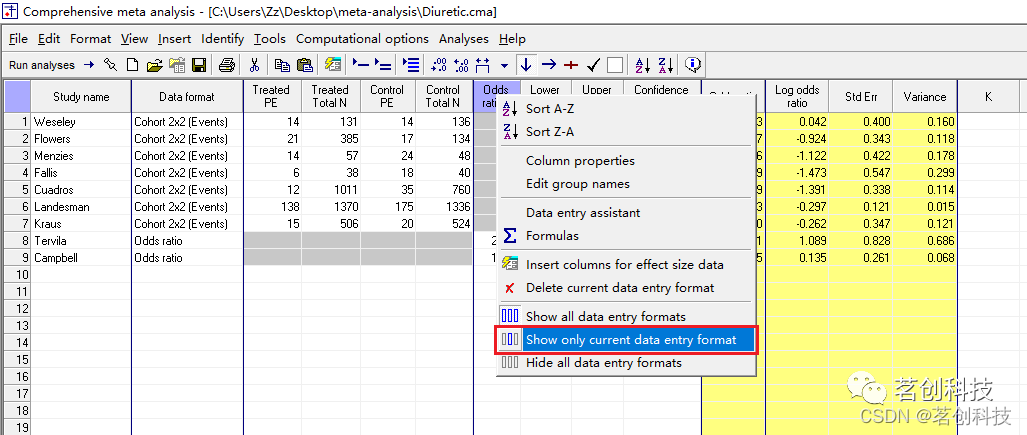
若要返回至正常模式,则同样用右键单击白色列,选择“Show only current data entry format”,表示仅显示当前数据输入格式。![]()
插入额外变量列。
-
第一个未使用的列是K
-
双击该列标题,会显示一个对话框
-
输入列名称
-
指定列为调节变量“Moderator”
-
选择数据类型(“Categorical 类别”,“Integer 整数”,或者“Decimal 小数”)
(在本例中,为“研究质量”创建一个列,并将其定义为一个类别调节变量(调节变量是可以进行疗效估计的一个研究特征)
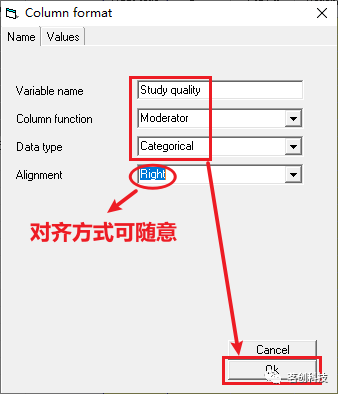
那么,“研究质量”列就创建好了。
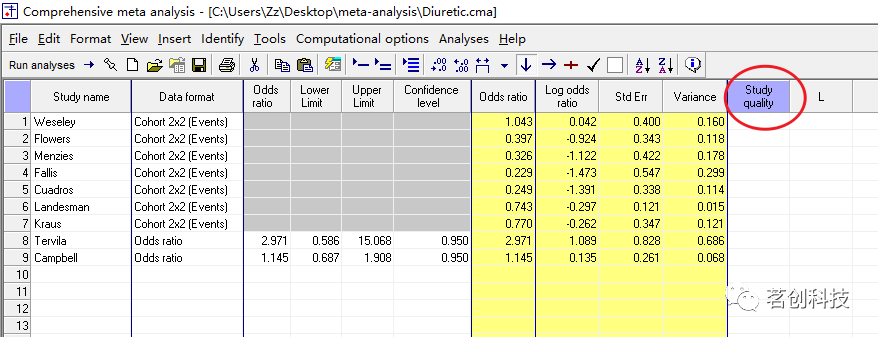
②数据分析部分
如何显示每个研究的权重?点击“Run analysis”后,在分析窗口的工具栏中点击“Show weights”就会显示权重列,再次点击则关闭。
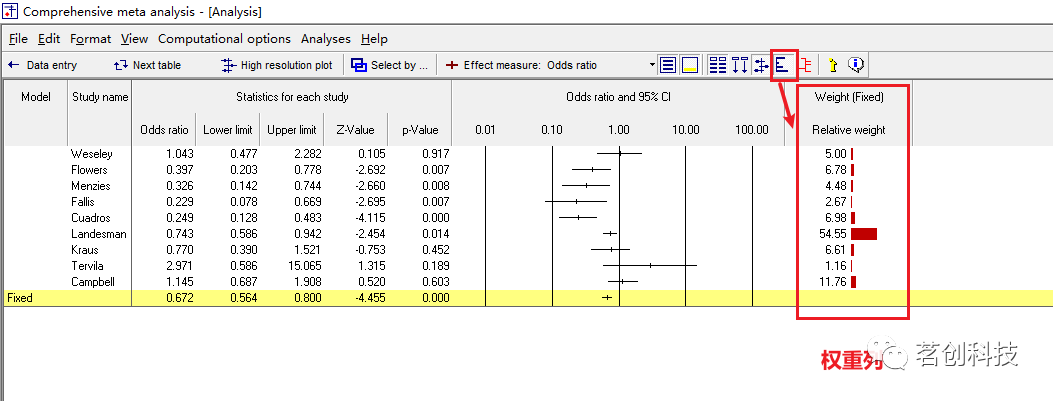
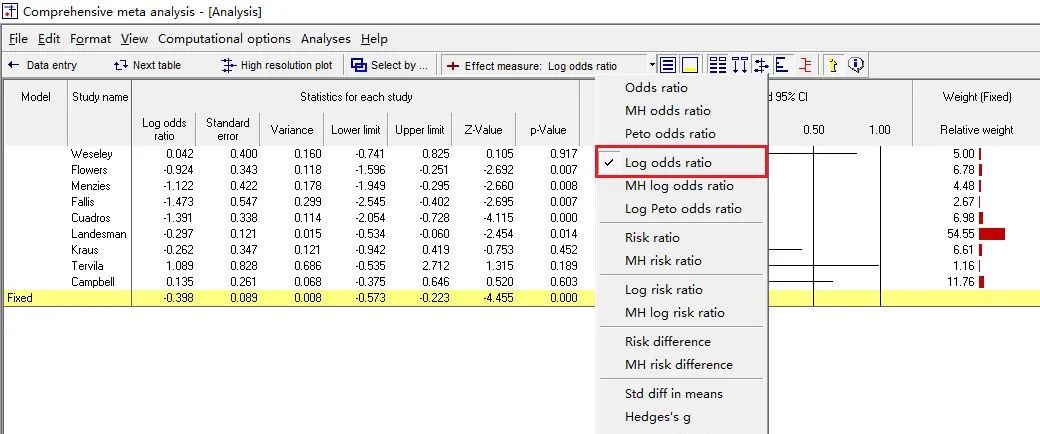
选择查看疗效的其他指标。在工具栏中,选择“Risk Ratio”,然后选择“log odds Ratio”,再选择“odds Ratio”可返回至默认界面。

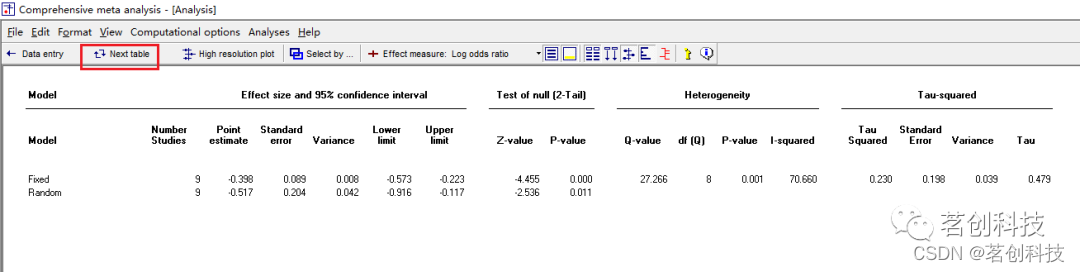
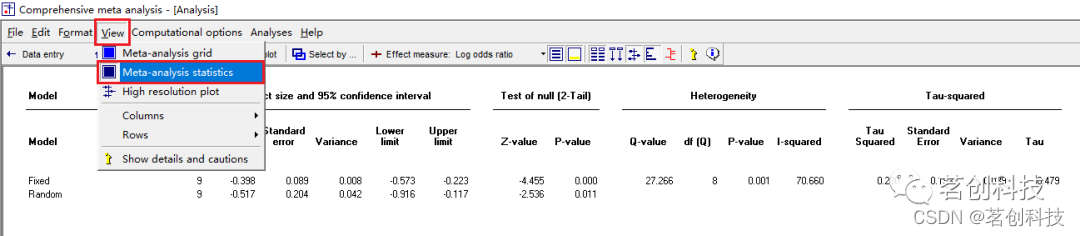
查看统计数据的详细信息。直接点击“Next table”;或者点击 View--Meta-analysis statistics 查看统计数据的详细信息。这个表中不仅有附加的统计信息,还包括异质性等相关信息。再次点击“Next table”则返回至分析界面。![]()
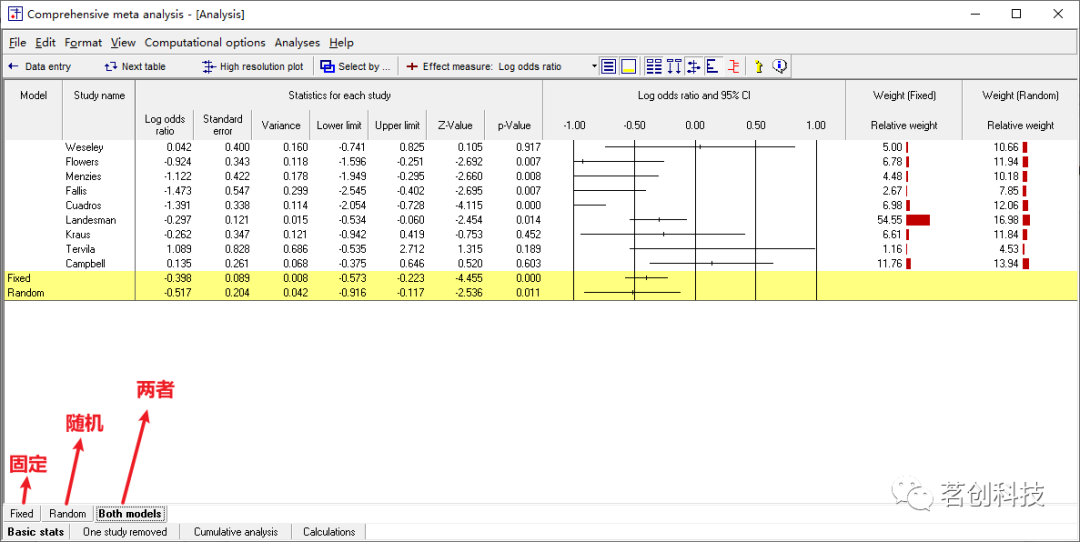
 选择计算模型。在屏幕的左下角可以看到有“Fixed”,“Random”和“Both”标签,分别表示固定效应模型,随机效应模型和两者都呈现。
选择计算模型。在屏幕的左下角可以看到有“Fixed”,“Random”和“Both”标签,分别表示固定效应模型,随机效应模型和两者都呈现。
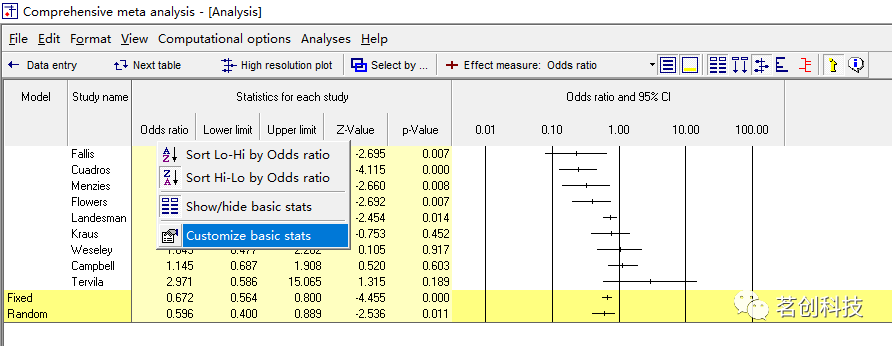
自定义显示。只保留那些我们想要在高分辨率绘图中使用到的列(因为列最少,森林图显示出的视觉效果就更好),所以可以先把权重显示关闭,右键单击比值比列,并选择 Customize basic stats
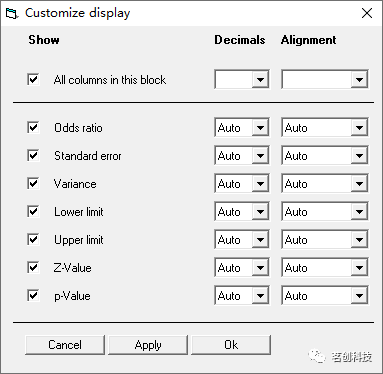
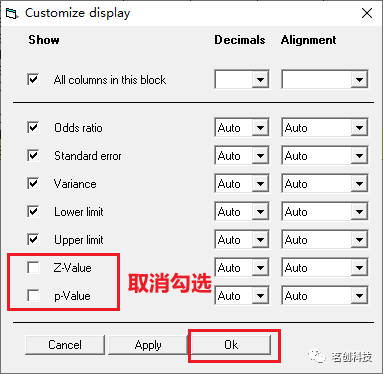
结果显示如下:
③高分辨率绘图部分
点击“High-resolution plot”,现在显示的高分辨率草图如下所示,可以继续进行修改。
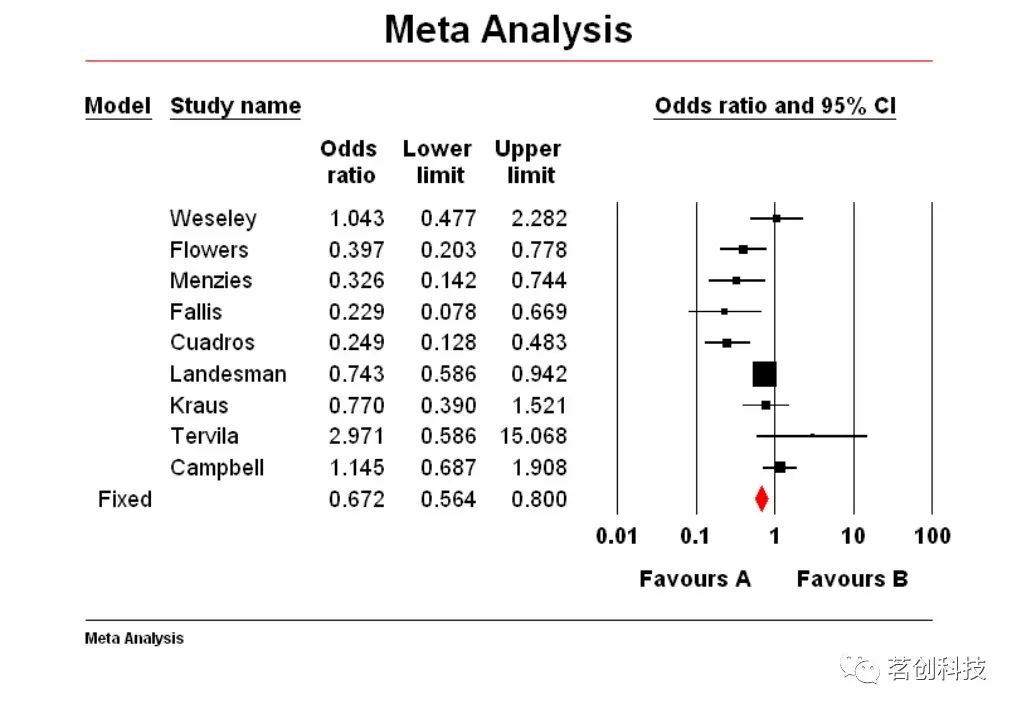
关于 Proportional 和 one-sized 标识。在固定效应模型下,符号的大小与每个研究的权重成比例。
关于固定效应和随机效应。只有当你在分析过程中选择了 Both Models 时,此选项才可用。这里显示的是固定效应,每个研究的符号大小是基于固定效应权重。你可以在工具栏的 Computational options 调整当前所选择的模型。
修改标题。
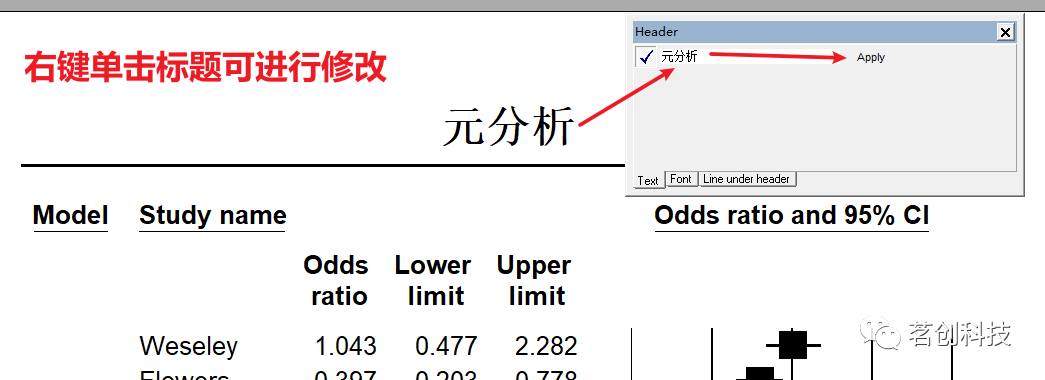
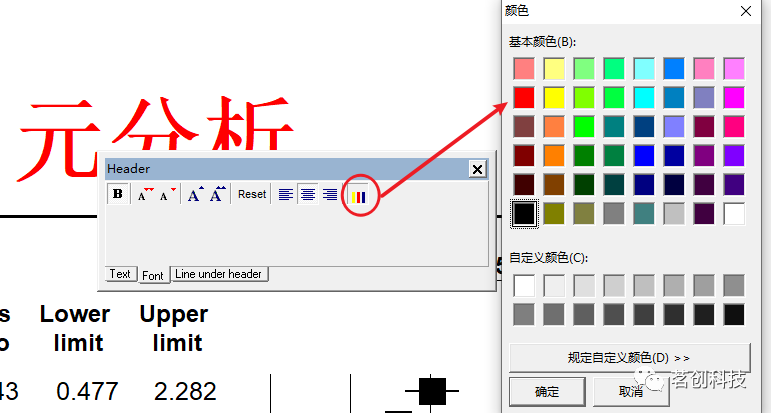
调整大小和颜色。这张表上的内容都可以用右键来进行修改和调整。
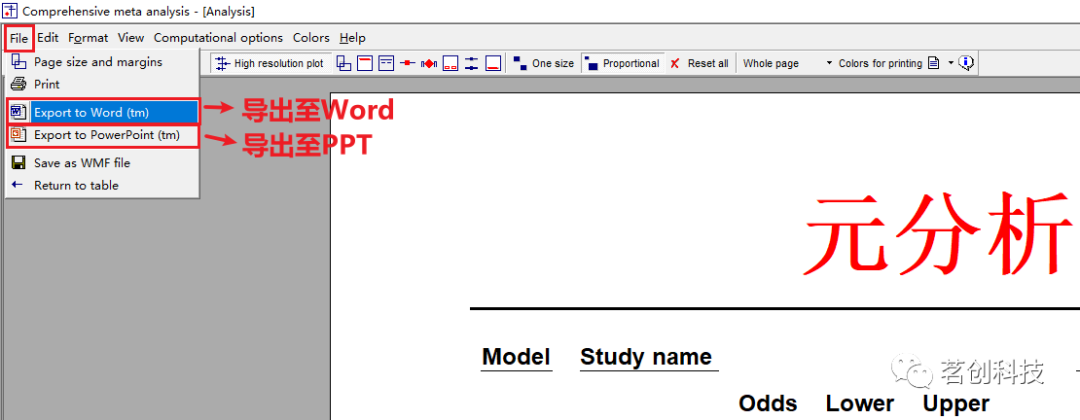
导出至 Word 或 PPT。
(全文完~)
元分析没有想象中困难,但是有很多内容还是需要大家不断实践和带着好奇心去摸索的,我们接下来也会给大家分享更多关于元分析或其他干货知识,希望小伙伴多多关注茗创科技。

















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









