






一、语音识别系统的基本结构
语音识别系统主要由四部分所组成:信号处理和特征提取、声学模型(AM)、语言模型(LM)和解码搜索部分。
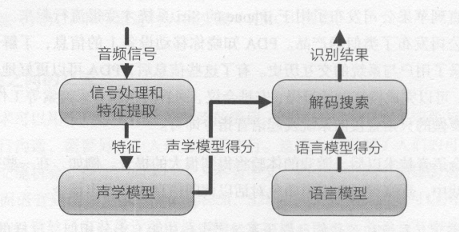
信号处理和特征提取:以音频信号为输入,通过消除噪声和信道失真对语音进行增强,将信号从时域转化到频域,并为后面的声学模型提取合适的有代表性的特征向量。
声学模型:将声学和发音学(phonetics)的知识进行整合,以特征提取部分生成的特征为输入,并为可变长特征序列生成声学模型分数
语言模型:通过从训练语料(通常是文本形式)学习词之间的相互关系,来估计假设词序列的可能性, 又叫语言模型分数。
解码搜索:对给定的特征向量序列和若干假设词序列计算声学模型分数和语言模型分数,将总体输出分数最高的词序列当作识别结果。
1.1 声学模型存在的问题
关于声学模型,有两个主要问题,分别是特征向量序列的可变长和音频信号的丰富变化性。可变长特征向量序列的问题在学术上通常由如动态时间规整(dynamic time warping, DTW )方法和将隐马尔可夫模型(HMM) 方法来解决。 音频信号的丰富变化性(variable)是由说话人的各种复杂的特性(如性别、健康 状况或紧张程度)交织,或是说话风格与速度、环境噪声、周围人声(sidetalk )、信道扭曲(channel distortion )(如麦克风间的差异)、方言差异、非母语口音( non-native accent )引起的。 一个成功的语音识别系统必须能够应付所有这类声音的变化因素。
--------------------------------------------------------------------------------------------------------------------------------
模型:
特征提取方法:梅尔倒谱系数(mel-frequency cepstral coefficient,MFCC)
相对频谱变换斗惑知线性预测”( perceptual linear prediction,PASTA-PLP )
声学模型:混合高斯模型-隐马尔可夫模型( Gaussian mixture model-HMM, GMM-HMM )















 7011
7011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









