







在此之前,我们的OS一直运行在单个CPU上,本节我们将启动多核,让其他CPU参与到调度中。顺便验证一下上一节实现的自旋锁。
在ARMV8上启动时一般来说只启动了一个主核,从核一直处于没上电的状态。因此需要主核主动将从核唤醒上电,ARM公司在ARMV8上提供了一个叫ATF(Arm Trusted Firmware)的东东,是一款开源的安全固件。其中的标准服务有一个模块叫做PSCI,专门负责CPU的管理,我们将使用PSCI提供的功能进行从核的启动。
PSCI
PSCI(Power State Coordination Interface)的主要功能:
- 核心空闲管理
- CPU的热插拔和从核启动
- 系统的关闭和重启
这里我们不对PSCI进行详细的介绍,感兴趣的同学可以去官网找一下文档仔细阅读或查阅其他大佬总结的文档。这里仅介绍下PSCI接口的定义和CPU启动的过程。
PSCI接口定义:
PSCI定义了各种CPU管理的接口,接口格式为X0~X3存放函数调用的参数。然后调用smc指令进入安全世界进行函数处理。处理完成后将结果写入X0,返回到EL1。
下边是CPU_ON调用的例子。参数1是功能定义,参数2是CPU的序号,参数3是启动之后执行的函数入口(必须是EL1的物理地址),参数4是函数的参数。
extern int secure_monitor_call(unsigned long fun_pro, unsigned long arg1, unsigned long arg2, unsigned long arg3);
int arch_cpu_on(int cpu_id, void *entry, void *arg)
{
int err_code;
err_code = secure_monitor_call(CPU_ON, cpu_id, (unsigned long)entry, (unsigned long)arg);
if (err_code != PCSI_SUCCESS) {
hf_printk("psci CPU_ON return err:%d\n", err_code);
}
return err_code;
}CPU_ON:
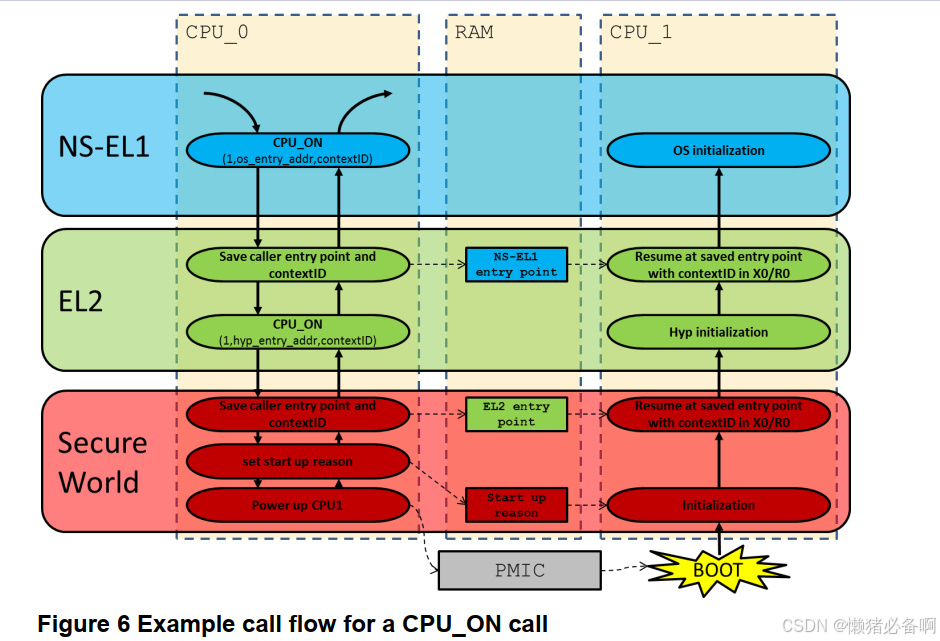
PSCI从核的启动过程,在PSCI的官方文档中给出了具体的调用流程。下图是一个带有hyp的CPU上电过程(我们将EL2的部分忽略即可,知只是做了虚拟化的转换)。
- CPU0在EL1构建PSCI的函数参数(CPU_ON, cpu_index, _entry, arg),调用SMC指令进入安全世界EL3。
- 安全世界进行异常处理,保存CPU启动函数位置和函数参数,并保存启动原因。最后给CPU1上电。并将CPU_ON命令执行的结果保存在X0中,同时返回EL1。
- CPU1上电之后,进行固件初始化,找到CPU0缓存的启动函数和参数,跳转到EL1执行函数。
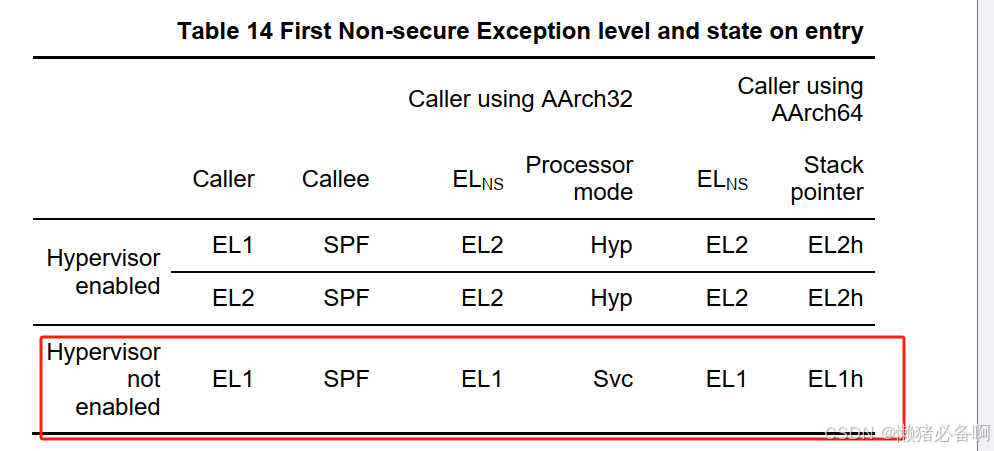
下图是官方文档给出的CPU_ON之后所处的异常等级,从下边可以看到在不使用hyp的情况下,CPU将从EL1开始执行,因此在CPU启动之后,我们不需要进行异常等级的切换。(实际在工程的过程中是需要进行异常等级处理的,可能是qemu启动的时候默认启动了hyp的功能)。
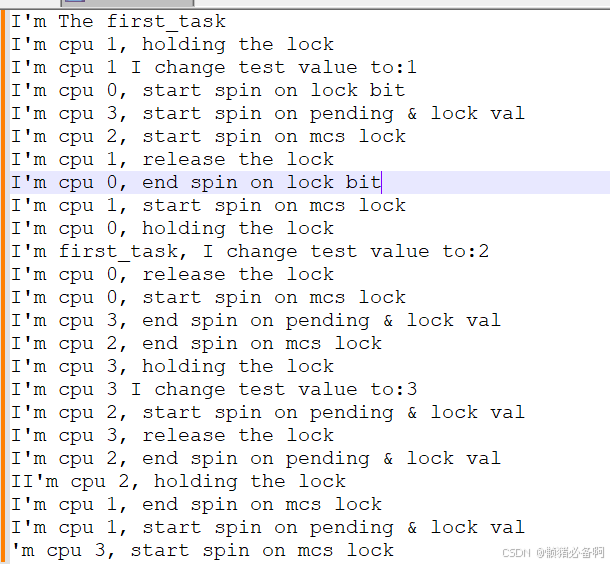
多核启动之后先运行了上一节spinlock的例子,从log中看是符合我们的分析逻辑的。
PER_CPU变量
per_cpu变量是内核实现的一种特性,从名字大概能理解是个什么作用,就是为每个CPU创建一个相同的变量。这是在SMP系统上一个很常用的东西,能大大提高系统的效率。本小节我们将从源码级别看一下per_cpu是如何实现的。
per_cpu变量的定义和初始化
DEFINE_PER_CPU(type, name)用于给每个CPU定义一个type类型的name变量。
//展开之前的代码
#define __PCPU_ATTRS(sec) \
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec)))
#define DEFINE_PER_CPU_SECTION(type, name, sec) \
__PCPU_ATTRS(sec) __typeof__(type) name
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")
//展开之后的代码
#define DEFINE_PER_CPU(type, name) \
__percpu __attribute__((section(.data..percpu))) __typeof__(type) name通过展开后的宏定义我们可以分析,就是在数据段中的percpu段定义了一个type类型,名字为name的变量,咦~好像只有一个呀,并没有每个CPU一个的样子。
其实这里只是在编译阶段做了一个标记,表示这一段的内容要每个CPU都有一份。当系统启动时会调用setup_per_cpu_areas函数,申请per_cpu变量需要的内存,然后从之前定义的数据段为每个CPU拷贝一份变量到内存中,最后设置一下__per_cpu_offset,供访问时使用。
void __init setup_per_cpu_areas(void)
{
unsigned long delta;
unsigned int cpu;
int rc;
/*
* Always reserve area for module percpu variables. That's
* what the legacy allocator did.
*/
rc = pcpu_embed_first_chunk(PERCPU_MODULE_RESERVE,
PERCPU_DYNAMIC_RESERVE, PAGE_SIZE, NULL,
pcpu_dfl_fc_alloc, pcpu_dfl_fc_free);
if (rc < 0)
panic("Failed to initialize percpu areas.");
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu)
__per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];
}per_cpu变量的使用
要访问定义的变量,需要使用per_cpu宏定义。
//根据偏移,找到变量的实际位置
#ifndef RELOC_HIDE
# define RELOC_HIDE(ptr, off) \
({ unsigned long __ptr; \
__ptr = (unsigned long) (ptr); \
(typeof(ptr)) (__ptr + (off)); })
#endif
#define __verify_pcpu_ptr(ptr) \
do { \
const void __percpu *__vpp_verify = (typeof((ptr) + 0))NULL; \
(void)__vpp_verify; \
} while (0)
//根据__per_cpu_offset 找到变量的位置
#define SHIFT_PERCPU_PTR(__p, __offset) \
RELOC_HIDE((typeof(*(__p)) __kernel __force *)(__p), (__offset))
//__per_cpu_offset 的定义
#ifndef __per_cpu_offset
extern unsigned long __per_cpu_offset[NR_CPUS];
#define per_cpu_offset(x) (__per_cpu_offset[x])
#endif
//将变量的地址和__per_cpu_offset组合,找到变量的实际位置
#define per_cpu_ptr(ptr, cpu) \
({ \
__verify_pcpu_ptr(ptr); \
SHIFT_PERCPU_PTR((ptr), per_cpu_offset((cpu))); \
})
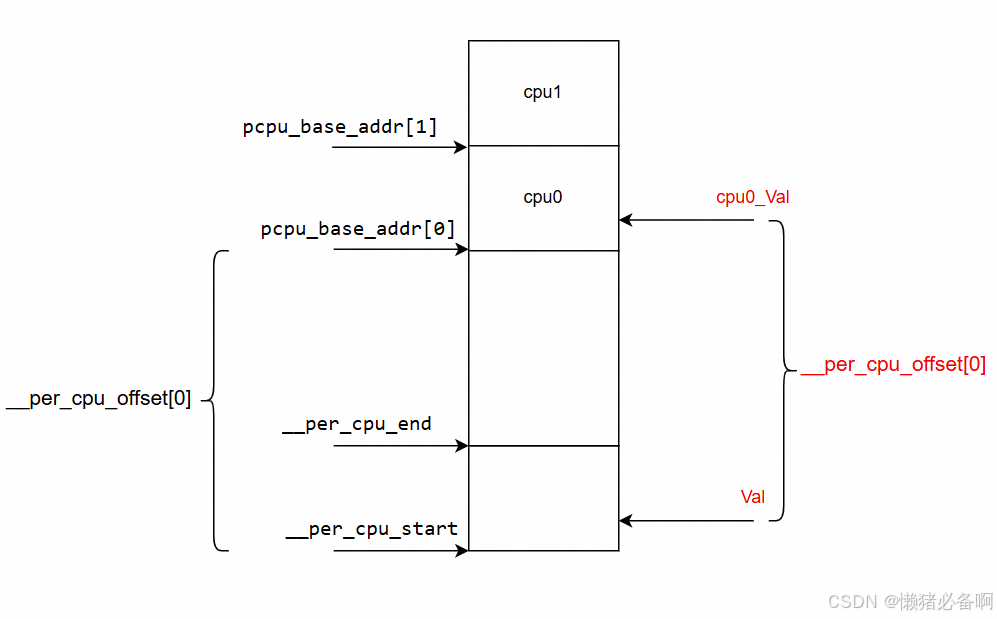
#define per_cpu(var, cpu) (*per_cpu_ptr(&(var), cpu))per_cpu变量的访问原理如下图,当需要访问cpu0的val变量时会调用per_cpu(val, 0)。实际上就是使用val的地址加上 __per_cpu_offset[0] 就得到了cpu0_val的地址,这样就能获取他的内容了。
IPI(Inter-Processor Interrupt)
核间中断介绍
核间中断是处理器间相互通信的一种手段,在ARMV8上通过SGI(Software Generated Interrupts)进行实现,GIC-V3定义了16个软中断,供我们使用。
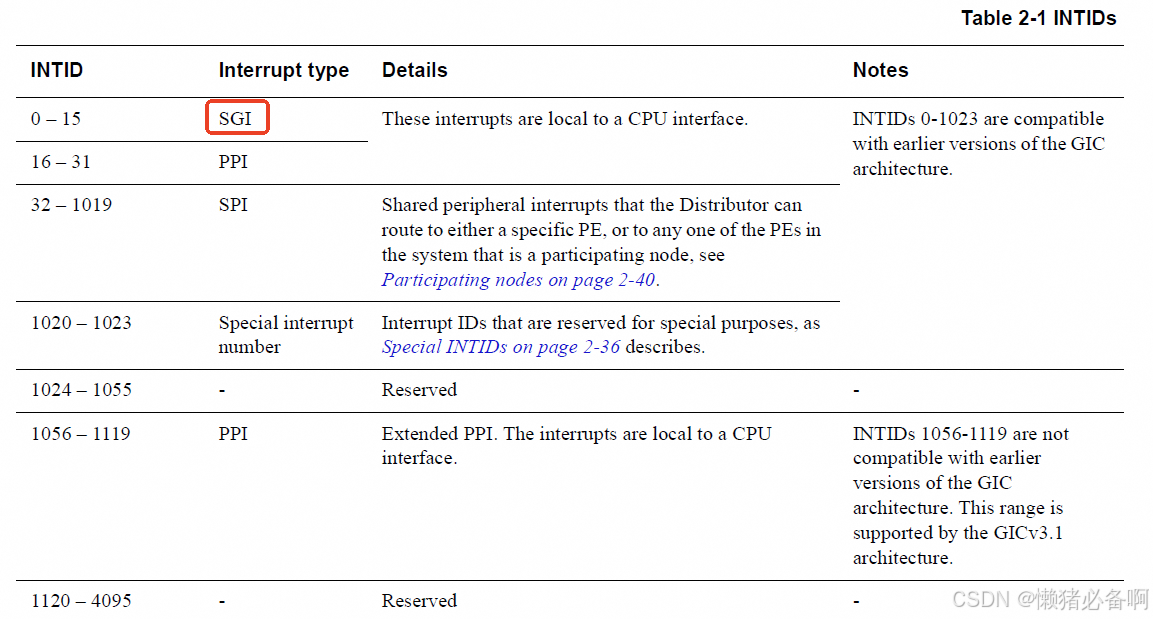
SGI处理的流程: PE-> Redistributor -> Distributor -> target Redistributor -> target CPU interface -> target PE
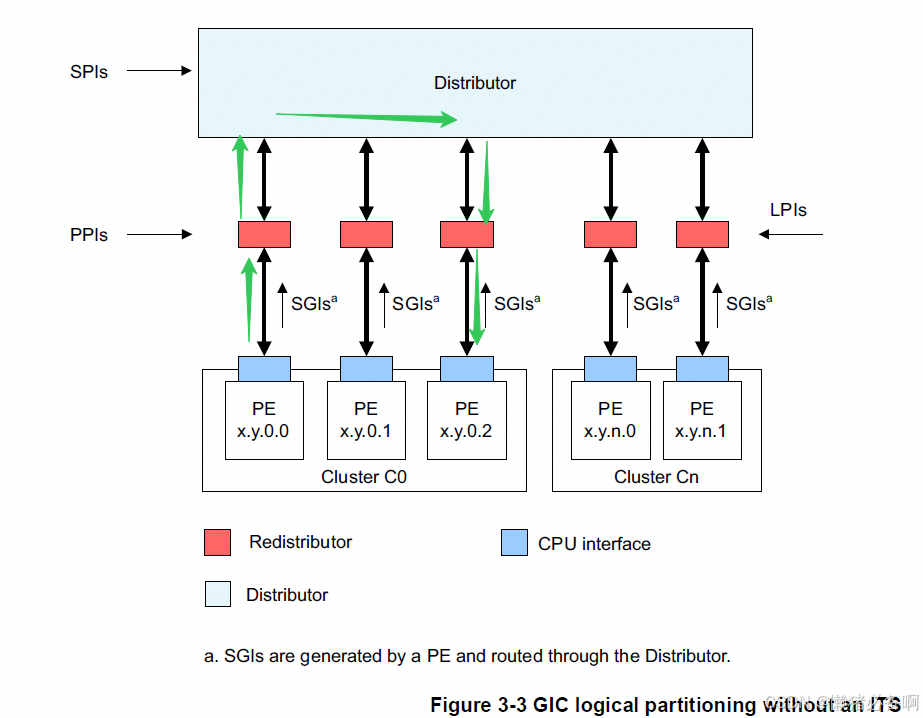
核间中断的使用场景
假设有两个CPU,task1的优先级是50,运行在CPU0上,task2的优先级是60,运行在CPU1上。并且task1和task2是目前优先级最高的两个(数值越小优先级越高)。这时task1在运行的过程中创建了一个task3,优先级是40,当前优先级最高的就变成了task3,会抢占当前的CPU,也就是CPU0,task1这是挂载在就绪队列上。那么当前正在运行的任务就变成了task2和task3,他们的优先级分别是40 和 60。这时就出现了一个现象,60低优先级的任务在运行而50高优先级的任务没在执行。这是不符合抢占设计的,所有需要使用IPI通知CPU1进行一次调度,从而使50优先级的任务再次抢占CPU1。
调试问题
不能正常调度,产生异常
出问题的地方如下:
想实现的功能是根据传递的参数决定是否进行全局锁的释放。此处忽略了cbnz并不会修改lr的值,导致从hf_asm_system_unlock返回之后,并没有按照原先的路径继续往下执行,而是返回到原先的lr地址arch_run_task的结束处。从而导致出现异常的内存访问,不能正常调度。
asm_run_task:
ldr x2, [x0]
mov sp, x2
#if (HF_CONFIG_SMP == 1)
cbnz x1, hf_asm_system_unlock
#endif
LOAD_SYS_REG
dsb sy
isb
LOAD_COMM_REG
eret
修改如下:
根据参数跳转到标签,执行bl hf_asm_system_unlock。bl指令会将下一条指令的地址存入lr寄存器,从而返回后能继续执行。
问题产生的原因是对于CBNZ指令的理解有问题。
asm_run_task:
ldr x2, [x0]
mov sp, x2
#if (HF_CONFIG_SMP == 1)
cbnz x1, .Lunlock
.Lunlock:
bl hf_asm_system_unlock
#endif
LOAD_SYS_REG
dsb sy
isb
LOAD_COMM_REG
eret多核调度异常:
问题现象如下,启动了4个核,之后两个核在运行任务,并且运行一段时间之后,没有任务切换了。或者运行一段时间后系统直接卡死,无法调度。
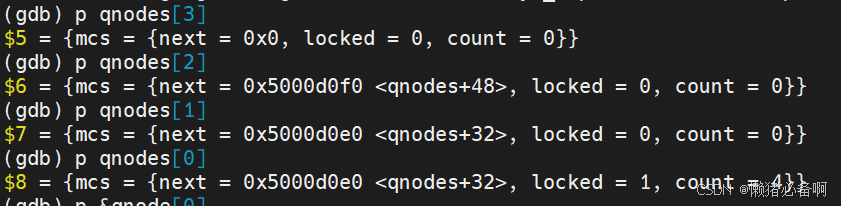
使用GDB调试信息如下,4个CPU都在获取自旋锁,整个系统卡住了。在GDB中对每个CPU进行backtrace信息查看,全都是arch_mcs_spin_lock_contended(&node->locked);这一行进入的,我们只有4个cpu,根据qspinlock的实现每个都卡在这个位置很明显是不正常的。由此判断可能是移植自旋锁的时候出了问题。

中间调试过程使用2个CPU和3个CPU分别进行实验,不会出现类似的问题。基本上可以确定和MCS有关系,因此在GDB调试时查看qnodes的内容,得到如下信息。qnodes数组中有数值,而per_cpu变量位置没有值,这是个不正常的现象。per_cpu变量在其他模块工作正常,因此怀疑可能是qspinlock.c中对于变量的访问出了问题(node = this_cpu_ptr(&qnodes[0].mcs);)。排查发现是编译时没有包含对应的头文件导致HF_CONFIG_SMP没有生效。重新包含后运行正常,移植代码的时候要多多注意此类问题。
代码编译和运行
git clone https://gitee.com/genglufei/hfos.git
cd hfos/day7_smp/hfOS/vendor
./build_hfos.sh qemu_a57
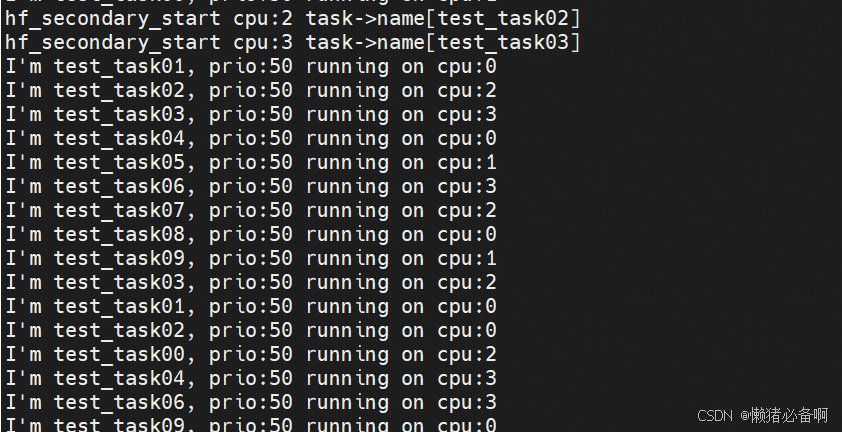
./run_hfos.sh运行结果如下:
可以看到任务在多核CPU上切换运行。

















 3244
3244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









